
Tritonの紹介 - ニューラルネットワークのためのGPUプログラミング

以下の記事を参考にして書いてます。
・Introducing Triton: Open-Source GPU Programming for Neural Networks
1. はじめに
「Triton 1.0」は、オープンソースのPythonライクなプログラミング言語で、CUDAの経験がない研究者でも、多くの場合、専門家と同等の高効率なGPUコードを書くことができます。
例えば、多くのGPUプログラマができないcuBLASの性能に匹敵するFP16行列乗算カーネルを、25行以下のコードで書くことができます。私たちの研究者は、すでにこのツールを使って、同等のTorch実装よりも、最大2倍効率的なカーネルを作成しています。私たちは、コミュニティと協力して、誰もがGPUプログラミングを利用できるようになることを楽しみにしています。
2. Triton
深層学習の分野における新しい研究アイデアは、一般的にネイティブフレームワークの演算子を組み合わせて実装されています。この方法は便利ですが、多くの一時的なテンソルを作成(または移動)する必要があり、大規模なニューラルネットワークのパフォーマンスを低下させる可能性があります。このような問題は、専用のGPU カーネルを作成することで軽減できますが、GPUプログラミングは非常に複雑で難しいものです。そこで私たちは、最近開発された言語およびコンパイラである「Triton」を拡張・改良することにしました。
3. GPUプログラミングの課題
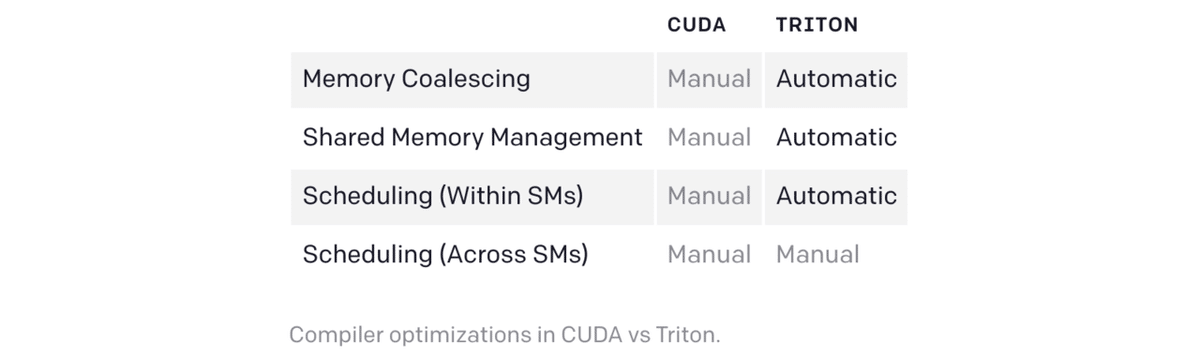
最近のGPUのアーキテクチャは、大きく分けて「DRAM」「SRAM」「ALU」の3つの要素から構成されており、CUDAコードを最適化する際には、それぞれの要素を考慮する必要があります。
・DRAMからのメモリ転送は、最新のメモリインターフェースの広いバス幅を活用するために、大きなトランザクションにまとめる必要があります。
・データを再利用する際には、SRAMに手動で隠し、共有メモリバンクのコンフリクトを最小限に抑えるように管理しなければなりません。
・Streaming Multiprocessors(SM)内での計算の分割とスケジューリングを慎重に行う必要があります。命令/スレッドレベルの並列処理を促進し、特殊な用途のALU(例:テンソルコア)を活用するようにしています。

これらの要素をすべて推論することは、長年の経験を持つ熟練のCUDAプログラマーにとっても困難なことです。「Triton」の目的は、これらの最適化を完全に自動化し、開発者が並列コードのハイレベルなロジックに集中できるようにすることです。「Triton」は幅広い応用を目的としているため、SM間の作業を自動的にスケジューリングすることはなく、重要なアルゴリズムの検討(タイリングやSM間の同期など)は開発者の判断に委ねられます。
4. プログラミングモデル
「Domain Specific Languages」と「JITコンパイラ」の中で、「Triton」はおそらく「Numba」に最も似ています。カーネルはPythonの関数として定義され、いわゆるインスタンスのグリッド上で異なるprogram_idで同時に起動されます。しかし、以下のコードに示されているように、似ているのはそれだけではありません。「Triton」は、「Single Instruction, Multiple Thread」 (SIMT)の実行モデルではなく、ブロック(2の累乗で構成される小さな配列)に対する操作によって、インスタンス内の並列性を実現します。これにより「Triton」は、CUDAスレッドブロック内での並行処理に関する問題(メモリの合体、共有メモリの同期/衝突、テンソルコアのスケジューリングなど)を効果的に抽象化します。
・Tritonでのベクトル加算
BLOCK = 512
# これはNumbaのGPUカーネルです
# この関数の様々なインスタンスが並行して実行される場合があります
@jit
def add(X, Y, Z, N):
# Numba / CUDAでは、各カーネルインスタンス自体がSIMT実行モデルを使用します
# ここで、threadIdxの様々な値に対して命令が並行して実行されます
tid = threadIdx.x
bid = blockIdx.x
# スカラーインデックス
idx = bid * BLOCK + tid
if id < N:
# Numbaにはポインタがありません
# Z、X、Yは密なテンソルです
Z[idx] = X[idx] + Y[idx]
...
grid = (ceil_div(N, BLOCK),)
block = (BLOCK,)
add[grid, block](x, y, z, x.shape[0])BLOCK = 512
# これはTritonのGPUカーネルです。
# この関数の様々なインスタンスが並行して実行される場合があります
@jit
def add(X, Y, Z, N):
# Tritonでは、各カーネルインスタンスが単一のスレッドでブロック操作を実行します
# threadIdxに類似した構造はありません。
pid = program_id(0)
# block of indices
idx = pid * BLOCK + arange(BLOCK)
mask = idx < N
# Tritonは、インデックス演算子ではなくポインタ演算を使用します
x = load(X + idx, mask=mask)
y = load(Y + idx, mask=mask)
store(Z + idx, x + y, mask=mask)
...
grid = (ceil_div(N, BLOCK),)
# スレッドブロックなし
add[grid](x, y, z, x.shape[0])これは、並列計算(つまり要素単位の計算)には特に役立たないかもしれませんが、より複雑なGPUプログラムの開発を大幅に簡素化できます。
例えば、融合ソフトマックスカーネルの場合(下図)、各インスタンスは与えられた入力テンソル X∈R^{M×N} の異なる行を正規化します。この並列化手法の標準的なCUDA実装は、スレッド間で同じ行のXを同時に削減する際に明示的な同期を必要とするため、記述が困難です。「Triton」では、各カーネルインスタンスが対象となる行をロードし、NumPyのようなプリミティブを用いて順次正規化することで、この複雑さのほとんどが解消されます。
・TritonのFused softmax
import triton
import triton.language as tl
@triton.jit
def softmax(Y, stride_ym, stride_yn, X, stride_xm, stride_xn, M, N):
# 行インデックス
m = tl.program_id(0)
# 列インデックス
# この特定のカーネルは、BLOCK_SIZE列より少ない行列に対してのみ機能します
BLOCK_SIZE = 1024
n = tl.arange(0, BLOCK_SIZE)
# ロードしたいすべての要素のメモリアドレスは次のように計算できます
X = X + m * stride_xm + n * stride_xn
# 入力データをロードします。 範囲外の要素を0で埋めます
x = tl.load(X, mask=n < N, other=-float('inf'))
# 数値的に安定したソフトマックスを計算する
z = x - tl.max(x, axis=0)
num = tl.exp(z)
denom = tl.sum(num, axis=0)
y = num / denom
# Yに書き戻す
Y = Y + m * stride_ym + n * stride_yn
tl.store(Y, y, mask=n < N)
import torch
# 入力/出力テンソルを割り当てます
X = torch.normal(0, 1, size=(583, 931), device='cuda')
Y = torch.empty_like(X)
# SPMD起動グリッド
grid = (X.shape[0], )
# GPUカーネルをエンキューします
softmax[grid](Y, Y.stride(0), Y.stride(1),
X, X.stride(0), X.stride(1),
X.shape[0] , X.shape[1])「Triton JIT」では,XとYをテンソルではなくポインタとして扱っていることに注意してください。より複雑なデータ構造(ブロック・スパース・テンソルなど)に対応するためには、メモリアクセスを低レベルで制御することが重要だと考えたからです。
重要なのは、このソフトマックスの実装では、正規化プロセス全体を通して、X行をSRAMに保持することで、データの再利用を可能にしていることです。これはPyTorch内部のCUDAコードとは異なります。一時メモリを使用することで、より一般的になりますが、速度は著しく低下します(以下)。ここで重要なのは、「Triton」が本質的に優れているということではなく、汎用ライブラリよりもはるかに高速な特殊カーネルの開発を容易にしているということです。
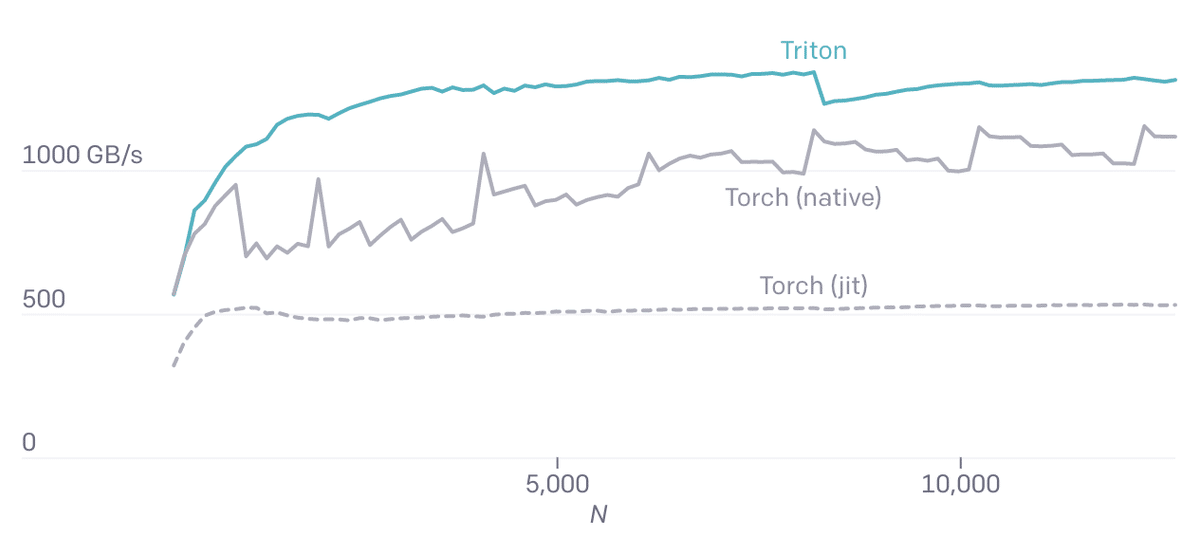
Torch (v1.9) JITのパフォーマンスが低いことは、高レベルのテンソル演算のシーケンスからCUDAコードを自動生成することの難しさを示しています。
・Torch JITとFused softmax
@torch.jit.script
def softmax(x):
x_max = x.max(dim=1)[0]
z = x - x_max[:, None]
numerator = torch.exp(x)
denominator = numerator.sum(dim=1)
return numerator / denominator[:, None]5. 行列の乗算
要素単位の演算や削減のために融合したカーネルを書けることは重要ですが、ニューラルネットワークにおける行列乗算タスクの重要性を考えると十分ではありません。結果的に、「Triton」はこれらの処理にも非常に有効で、わずか25行のPythonコードでピーク性能を達成しました。一方、同様のことをCUDAで実装するとなると、より多くの労力を必要とし、さらには性能が低下する可能性もあります。
・Tritonでの行列乗算
@triton.jit
def matmul(A, B, C, M, N, K, stride_am, stride_ak,
stride_bk, stride_bn, stride_cm, stride_cn,
**META):
# メタパラメータを抽出する
BLOCK_M, GROUP_M = META['BLOCK_M'], META['GROUP_M']
BLOCK_N = META['BLOCK_N']
BLOCK_K = META['BLOCK_K']
# プログラムは、L2ヒット率を向上させるためにグループ化されます
_pid_m = tl.program_id(0)
_pid_n = tl.program_id(1)
pid_m = _pid_m // GROUP_M
pid_n = (_pid_n * GROUP_M) + (_pid_m % GROUP_M)
# rm (またはrn)は、Cの行(または列)のインデックスの範囲を示します
rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
rn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
# rkは、A(またはB)の列(または行)のインデックスの範囲を示します
rk = tl.arange(0, BLOCK_K)
# AとBの最初のブロックの要素のメモリアドレスは、
# numpyスタイルのブロードキャストを使用して計算できます
A = A + (rm[:, None] * stride_am + rk[None, :] * stride_ak)
B = B + (rk [:, None] * stride_bk + rn[None, :] * stride_bn)
# アキュムレータを初期化して繰り返し更新します
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(K, 0, -BLOCK_K):
a = tl.load(A)
b = tl.load(B)
# ブロックレベルの行列乗算
acc += tl.dot(a, b)
# 次の反復中にAとBの次のブロックがロードされるようにポインタをインクリメントします
A += BLOCK_K * stride_ak
B += BLOCK_K * stride_bk
# fuse leaky ReLU if desired
# acc = tl.where(acc >= 0, acc, alpha * acc)
# 結果を書き戻す
C = C + (rm[:, None] * stride_cm + rn[None, :] * stride_cn)
mask = (rm[:, None] < M) & (rn[None, :] < N)
tl.store(C, acc, mask=mask)手書きの行列乗算カーネルの重要な利点の1つは、入力(例:スライス)と出力(例:Leaky ReLU)の融合的な変換に対応するように、必要に応じてカスタマイズできることです。「Triton」のようなシステムがなければ、GPUプログラミングの専門知識を持たない開発者にとって、行列乗算カーネルの自明でない変更は手の届かないものになってしまうでしょう。

6. ハイレベルなシステムアーキテクチャ
Tritonの優れた性能は、LLVMベースの中間表現であるTriton-IRを中心としたモジュール式のシステムアーキテクチャによって実現されています。この中間表現では、多次元の値のブロックがファーストクラスとして扱われます。
・Tritonの高レベルのアーキテクチャ

@triton.jit デコレータは,Python 関数の抽象構文木(AST)を走査し,一般的なSSA構築アルゴリズムを用いて Triton-IR をオンザフライで生成します。生成されたIRコードは、コンパイラバックエンドによって単純化、最適化、自動並列化された後、高品質な LLVM-IR、最終的には PTX に変換され、最近のNVIDIA GPUで実行されます。現時点では、CPUとAMDのGPUはサポートされていませんが、この問題を解決するためのコミュニティへの貢献を歓迎します。
7. コンパイラバックエンド
Triton-IRを用いてブロック化されたプログラムを表現することで、コンパイラが様々な重要なプログラム最適化を自動的に行うことができることがわかりました。例えば、計算量の多いブロックレベルの演算(例:tl.dot)のオペランドを見ることで、データを自動的に共有メモリに格納したり、標準的なライブネス解析技術を用いて割り当て/同期を行うことができます。

一方、「Triton」のプログラムは、(1)異なるカーネルインスタンスを同時に実行することで、SM間で効率的かつ自動的に並列化することができます。また、(2)SM内では、以下のように、各ブロックレベルの演算の反復空間を分析し、異なるSIMDユニットに適切に分割することで、効率的かつ自動的に並列化することができます。

この記事が気に入ったらサポートをしてみませんか?