
LlamaIndex v0.8 クイックスタートガイド - Python版

Python版の「LlamaIndex」のクイックスタートガイドをまとめました。
・LlamaIndex v0.8.59
【最新版の情報は以下で紹介】
1. LlamaIndex
「LlamaIndex」は、プライベートやドメイン固有の知識を必要とする専門知識を必要とする質問応答チャットボットを簡単に作成できるライブラリです。
2. LlamaIndexの5つのステージ
「LlamaIndex」には、5つのステージがあります。

2-1. Loading
データソース (テキストファイル、PDF、Webサイト、データベース、APIなど) からデータを読み込みます。
「Loading」の主要コンポーネントは、次のとおりです。
・Document : データソースのコンテナ
・Node : Documentを分割したもの。チャンクとメタデータが含まれる
・Connector : データソースからDocumentおよびNodeに取り込むモジュール。LlamaHubで数百のConnectorを提供
2-2. Indexing
データのクエリを可能にするデータ構造に変換します。
「Indexing」の主要コンポーネントは、次のとおりです。
・Index : データのクエリを可能にするデータ構造
・Embedding LLM : 関連データを見つけるためのベクトル表現に変換するLLM
2-3. Storing
インデックスが作成した後、インデックスと他のメタデータを保存することで、再作成する必要がなくなります。
2-4. Querying
インデックスから関連データをクエリします。
「Querying」の主要コンポーネントは、次のとおりです
・Retriever : クエリ時にIndexから関連データを効率的に取得する方法を定義
・Node Postprocessor : 取得したノードセットを受け取り、それらに変換、フィルタリング、リランキングを適用
・Response Synthesizer : ユーザークエリと取得したテキストチャンクを使用してレスポンスを生成
2-3. Evaluation
クエリに対するレスポンスがどの程度正確、忠実、迅速であるかを客観的に測定します。
3. ドキュメントの準備
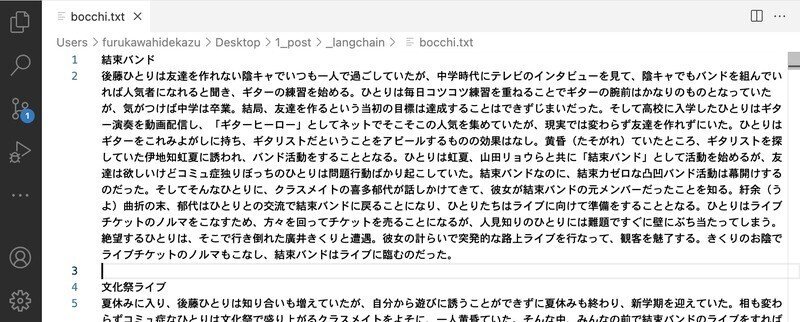
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のドキュメントを用意しました。
・bocchi.txt
4. 質問応答
Google Colabでの質問応答の実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install llama-index==0.8.59(2) 環境変数の準備。
以下のコードの <OpenAI_APIのトークン> にはOpenAI APIのトークンを指定します。(有料)
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIのトークン>"(3) ログレベルの設定。
import logging
import sys
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)・DEBUG : デバッグ情報の出力
・INFO : 情報の出力 (想定通りの事象の発生)
・WARNING : 警告の出力 (想定外の事象の発生)
・ERROR : エラーの出力 (実行の続行不能)
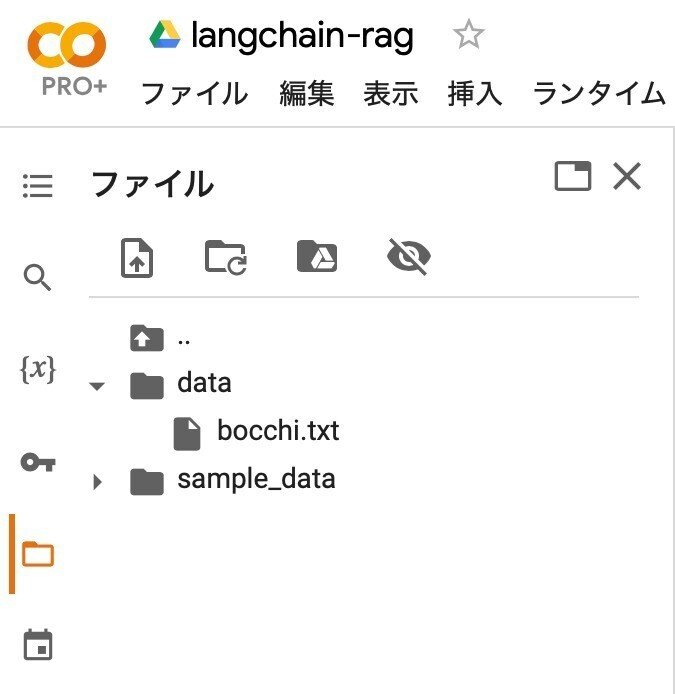
(4) Colabにdataフォルダを作成してドキュメントを配置。
左端のフォルダアイコンでファイル一覧を表示し、右クリック「新しいフォルダ」でdataフォルダを作成し、ドキュメントをドラッグ&ドロップします。
(5) ドキュメントの読み込み。
from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
documents = SimpleDirectoryReader("data").load_data()(6) インデックスの作成。
「インデックス」は、ドキュメントの情報を保持するモジュールです。ドキュメントをチャンクに分割し、チャンク毎に埋め込みに変換して保持ます。チャンクは類似検索の対象となるデータ単位になります。
from llama_index import VectorStoreIndex
# インデックスの作成
index = VectorStoreIndex.from_documents(documents)DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 結束バンド 後藤ひとりは友達を作れない陰キャでいつも一人で過ごしていたが、中学時代にテレビのイ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 文化祭ライブ 夏休みに入り、後藤ひとりは知り合いも増えていたが、自分から遊びに誘うことができず...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: ひねくれ者なヨヨコは、結束バンドをライバル視しながらも、彼女たちにアドバイスを送り、ファンたち...
:(7) クエリエンジンの作成。
「クエリエンジン」は、ユーザー入力(クエリ)と関連する情報をインデックスから取得し、それをもとに応答を生成するモジュールです。
# クエリエンジンの作成
query_engine = index.as_query_engine()(8) 質問応答。
# 質問応答
print(query_engine.query("ぼっちちゃんの得意な楽器は?"))後藤ひとりの得意な楽器はギターです。
ログを確認すると、以下のコンテキストを取得していることがわかります。
[Similarity score: 0.832151] 自分には何の取り柄もないのを痛感していたため、中学の頃に暗い性格の人間がバンドをやって人気者になったインタビューを読んで、ギターを始める。毎日練習したお陰でギターの腕前はプロ級になったが、結局、...
[Similarity score: 0.829139] 変わり者で一人でいるのが好きだが、後藤ひとりと違って特にコミュ障というわけではない。音楽に関しては独自の価値観を持っており、流行(はや)りに流されるのを嫌い、バンドの個性を重視している。そのため...OpenAI APIの通信内容も確認できます。Unicodeエスケープシーケンスを日本語に戻してます。
Context information is below.
---------------------
自分には何の取り柄もないのを痛感していたため、中学の頃に暗い性格の人間がバンドをやって人気者になったインタビューを読んで、ギターを始める。毎日練習したお陰でギターの腕前はプロ級になったが、結局、...
変わり者で一人でいるのが好きだが、後藤ひとりと違って特にコミュ障というわけではない。音楽に関しては独自の価値観を持っており、流行(はや)りに流されるのを嫌い、バンドの個性を重視している。そのため...
---------------------
Given the context information and not prior knowledge, answer the question. If the answer is not in the context, inform the user that you can't answer the question.
Question: ぼっちちゃんの得意な楽器は?
Answer: 5. インデックスの保存
作成したインデックスは保存しておくと、次回に再作成する必要がなくなります。
(1) インデックスの保存。
# インデックスの保存
index.storage_context.persist()(2) インデックスの読み込み。
from llama_index import StorageContext, load_index_from_storage
# インデックスの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)6. カスタマイズ
ユースケースに合わせて以下のコードをカスタマイズします。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# カスタマイズするコード
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)6-1. チャンクサイズの変更
今回は、チャンクサイズを500に設定します。
(1) ServiceContextでチャンクの最大サイズを指定。
from llama_index import ServiceContext
# ServiceContextの準備
service_context = ServiceContext.from_defaults(
chunk_size=500 # チャンクの最大サイズ
)(2) VectorStoreIndexにServiceContextを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# VectorStoreIndexにServiceContextを設定
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context # ServiceContextの設定
)
query_engine = index.as_query_engine()
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)チャンク数は、以下のコードで確認できます。
print(len(index.index_struct.nodes_dict))15から33に増えました。
6-2. クエリで取得するコンテキスト数の変更
今回は、5個のコンテキストを取得するようにします。デフォルトでは2個取得しています。
(1) index.as_query_engine()のsimilarity_top_kにコンテキスト数を指定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# クエリする時により多くのコンテキストを取得
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5) # コンテキスト数
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)6-3. VectorStoreの変更
「LlamaIndex」で利用可能な「VectorStore」は、「Using Vector Stores」で確認できます。
今回は、「Chroma」を使用します。
(1) パッケージのインストール。
# パッケージのインストール
!pip install chromadb(2) StorageContextの準備。
import chromadb
from llama_index.vector_stores import ChromaVectorStore
from llama_index import StorageContext
# StorageContextの準備
chroma_client = chromadb.PersistentClient()
chroma_collection = chroma_client.create_collection("quickstart")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)(3) VectorStoreIndexにStorageContextを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# VectorStoreIndexにStorageContextを設定
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context # StorageContextの設定
)
query_engine = index.as_query_engine()
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)6-4. LLMの変更
「LlamaIndex」では、「LangChain」の「LLM」「ChatModel」も利用できます。
今回は、「gpt-4」を使用します。デフォルトは、「gpt-3.5-turbo」です。
(1) ServiceContextの準備。
from llama_index import ServiceContext
from langchain.chat_models import ChatOpenAI
# ServiceContextの準備
service_context = ServiceContext.from_defaults(
llm=ChatOpenAI(model_name="gpt-4")
)(2) VectorStoreIndexにServiceContextを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 別のLLMの使用
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(
service_context=service_context # ServiceContextの設定
)
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)6-5. レスポンスモードの変更
「LlamaIndex」の主なレスポンスモードは、次の3つです。
・refine : ノードごとに別々のLLM呼び出して応答を返す。精度重視
・compact : refineと似ているが、事前にチャンク連結し、LLM呼び出しのコストを削減。デフォルト
・tree_summarize : 再帰的なツリーのデータ構造を構築し、ルートノードの応答を返す。要約に最適
今回は、レスポンスモードを「refine」にします。デフォルトは「compact」です。
(1) index.as_query_engine()のresponse_modeにレスポンスモードを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# レスポンスモードの変更
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="refine")
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
print(response)ぼっちちゃんの得意な楽器はギターです。彼はバンド経験があり、演奏技術も結束バンドの中でも群を抜いて高いです。彼は独自の音楽の価値観を持っており、バンドの個性を重視しています。ログでOpenAI APIの通信内容も確認できます。
Context information is below.
---------------------
自分には何の取り柄もないのを痛感していたため、中学の頃に暗い性格の人間がバンドをやって人気者になったインタビューを読んで、ギターを始める。毎日練習したお陰でギターの腕前はプロ級になったが、結局、...
---------------------
Given the context information and not prior knowledge, answer the question. If the answer is not in the context, inform the user that you can't answer the question.
Question: ぼっちちゃんの得意な楽器は?
Answer: You are an expert Q&A system that stricly operates in two modeswhen refining existing answers:
1. **Rewrite** an original answer using the new context.
2. **Repeat** the original answer if the new context isn't useful.
Never reference the original answer or context directly in your answer.
When in doubt, just repeat the original answer.New Context: 変わり者で一人でいるのが好きだが、後藤ひとりと違って特にコミュ障というわけではない。音楽に関しては独自の価値観を持っており、流行(はや)りに流されるのを嫌い、バンドの個性を重視している。そのため...
Query: ぼっちちゃんの得意な楽器は?
Original Answer: ぼっちちゃんの得意な楽器はギターです。
New Answer:6-6. エンジンの変更
「LlamaIndex」には、次の3つのエンジンがあります。
・Query Engine : データに対して質問するためのエンジン。クエリを受け取り、LLMに参照コンテキストとともに渡してレスポンスを取得
・Chat Engine : データと会話するためのエンジン。一問一答ではなく、マルチターンで、会話履歴もレスポンス生成に利用
・Agent : タスクを完了するために任意の数のステップを実行し、最適な行動方針を動的に決定。一連の「Tool」を介して世界と対話
今回は「Chat Engine」を使います。デフォルトは「Query Engine」です
(1) index.as_chat_engine()でチャットエンジンを取得してchat()で会話。
VectorStoreのコンテキストを利用して会話します。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# チャットで会話
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("後藤ひとりの性格は?")
print(response)後藤ひとりは変わり者で一人でいることを好みますが、コミュニケーションが苦手というわけではありません。彼は独自の音楽の価値観を持ち、流行に流されることを嫌います。バンドの個性を重視しており、演奏技術も高いです。ただし、彼はミステリアスな雰囲気を持っており、周囲からは勉強が得意と思われていましたが、実際には学力は中学生レベルであり、成績は常に赤点です。彼は要領が良いため、高校受験の際には一夜漬けで乗り切ったと言われています。
(2) 会話履歴が必要な内容で会話。
チャットエンジンは会話履歴も利用して会話します。
response = chat_engine.chat("その人物についてどう思いますか?")
print(response)私は後藤ひとりについては個性的で興味深い人物だと思います。彼の音楽への独自の価値観やバンドへのこだわりは素晴らしいと思いますし、演奏技術の高さも魅力的です。また、一人でいることを好むという一面も興味深いですね。ただし、学力が低いという点は少し驚きですが、彼の要領の良さや一夜漬けで高校受験を乗り切ったというエピソードも興味深いです。全体的には後藤ひとりは魅力的な人物だと思います。
6-7. ストリーミングの有効化
レスポンスのストリーミングを有効化します。
(1) index.as_query_engine()のstreamingにTrueを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# レスポンスをストリーミングに変更
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
response.print_response_stream()6-8. プロンプトテンプレートの変更
今回は、日本語のプロンプトテンプレートに切り替えます。
(1) QAプロンプトテンプレートとRefineプロンプトテンプレートの準備。
from llama_index.llms import ChatMessage, MessageRole
from llama_index.prompts import ChatPromptTemplate
# Text QA Prompt
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="""あなたは世界中で信頼されているQAシステムです。
事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。
従うべきいくつかのルール:
1. 回答内で指定されたコンテキストを直接参照しないでください。
2. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。""",
),
ChatMessage(
role=MessageRole.USER,
content="""コンテキスト情報は以下のとおりです。
---------------------
{context_str}
---------------------
事前知識ではなくコンテキスト情報を考慮して、クエリに答えます。
Query: {query_str}
Answer: """
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
# Refine Prompt
chat_refine_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="""あなたは世界中で信頼されているQAシステムです。
事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。
従うべきいくつかのルール:
1. 回答内で指定されたコンテキストを直接参照しないでください。
2. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。""",
),
ChatMessage(
role=MessageRole.USER,
content="""あなたは、既存の回答を改良する際に2つのモードで厳密に動作するQAシステムのエキスパートです。
1. 新しいコンテキストを使用して元の回答を**書き直す**。
2. 新しいコンテキストが役に立たない場合は、元の回答を**繰り返す**。
回答内で元の回答やコンテキストを直接参照しないでください。
疑問がある場合は、元の答えを繰り返してください。
New Context: {context_msg}
Query: {query_str}
Original Answer: {existing_answer}
New Answer: """
),
]
refine_template = ChatPromptTemplate(chat_refine_msgs)(2) index.as_query_engine()のtext_qa_templateにQAプロンプトテンプレート、refine_templateにRefineプロンプトテンプレートを設定。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# レスポンスをストリーミングに変更
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(
text_qa_template=text_qa_template, # QAプロンプトテンプレートの設定
refine_template=refine_template # Refineプロンプトテンプレートの設定
)
response = query_engine.query("ぼっちちゃんの得意な楽器は?")
response.print_response_stream()ログでプロンプトテンプレートが変更されていることを確認できます。
コンテキスト情報は以下のとおりです。
---------------------
自分には何の取り柄もないのを痛感していたため、中学の頃に暗い性格の人間がバンドをやって人気者になったインタビューを読んで、ギターを始める。毎日練習したお陰でギターの腕前はプロ級になったが、結局、...
変わり者で一人でいるのが好きだが、後藤ひとりと違って特にコミュ障というわけではない。音楽に関しては独自の価値観を持っており、流行(はや)りに流されるのを嫌い、バンドの個性を重視している。そのため...
---------------------
事前知識ではなくコンテキスト情報を考慮して、クエリに答えます。
Query: ぼっちちゃんの得意な楽器は?
Answer: 7. LlamaHub
「LlamaIndex」がドキュメントとして読み込めるのは、テキストだけではありません。「LlamaHub」で提供しているデータコネクタを利用することで、さまざまなファイル (PDF、ePub、Word、PowerPoint、Audioなど) やWebサービス (Notion、Slack、Wikipediaなど) をドキュメントのデータソースとして利用できます。
今回は、PDFについてLlamaIndexで質問してみます。
(1) llama_hubパッケージのインストール。
# llama_hubパッケージのインストール
!pip install llama_hub(2) ターゲットとなるPDFの準備。
今回は、PDF「GPT-4V(ision) System Card」を準備しました。
# PDFの準備
!wget https://cdn.openai.com/papers/GPTV_System_Card.pdf(3) 「LlamaHub」のサイトを開き、目的のデータコネクタを探す。
今回は、「file/pdf」をクリックします。
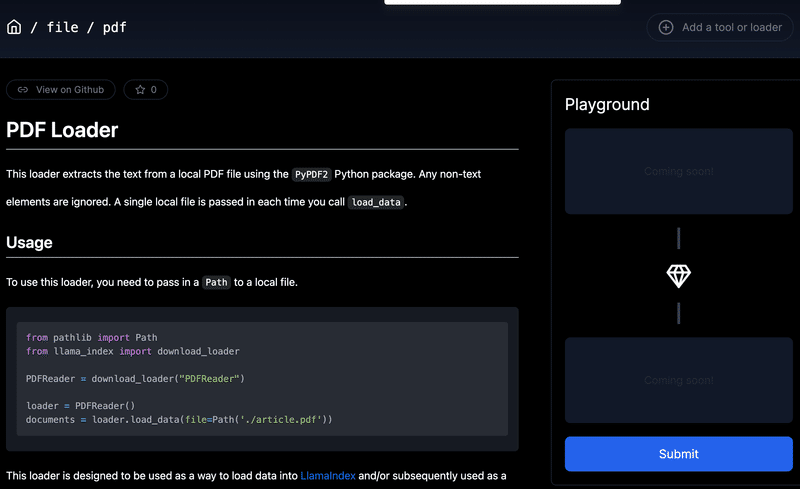
(4) 使い方 (Usage) の手順に沿って、サンプルコードをコピペし、PDFのファイル名を変更。
from pathlib import Path
from llama_index import download_loader
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path('./GPTV_System_Card.pdf'))(5) インデックスとクエリエンジンの作成。
from llama_index import VectorStoreIndex
# インデックスの作成
index = VectorStoreIndex.from_documents(documents)
# クエリエンジンの作成
query_engine = index.as_query_engine()(5) 質問応答。
# 質問応答
print(query_engine.query("GPT-4Vの特徴は?"))GPT-4Vの特徴は、ユーザーが提供した画像入力を分析する能力を持つことです。これにより、GPT-4Vは従来の言語モデルにはない新しいインターフェースと機能を提供し、新しいタスクを解決したり、ユーザーに新しい体験を提供することが可能です。また、GPT-4Vはテキストとビジョンの両方のモダリティの制約と能力を持ち、大規模なモデルによって提供される知能と推論によって生まれる新しい能力も備えています。
関連
・LlamaIndex
・LlamaIndex.ts
・Chat LlamaIndex
・LlamaIndex Document
・LlamaIndex Hub
この記事が気に入ったらサポートをしてみませんか?