
Google Colab で AniPortrait を試す

「Google Colab」で「AniPortrait」を試したので、まとめました。
1. AniPortrait
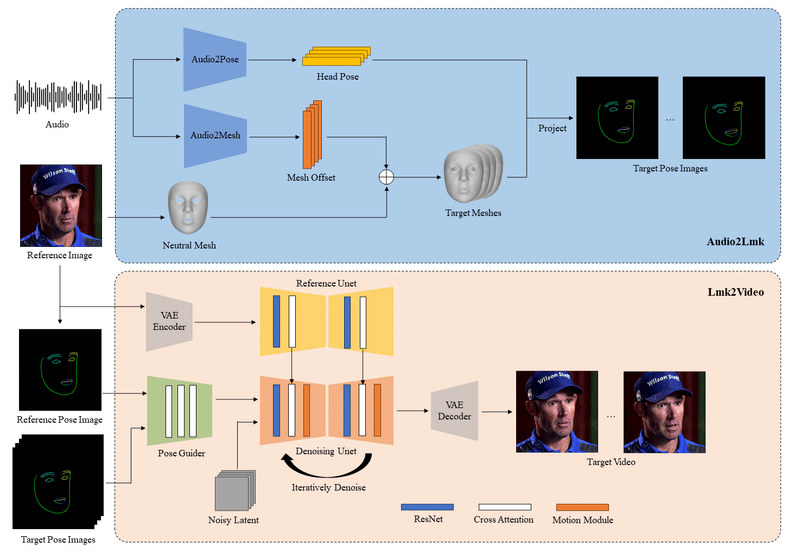
「AniPortrait」は、「音声」と「ポートレート画像」から「動画」を生成することができるフレームワークです。
(1) 音声 + ポートレート画像 → 顔ランドマーク
(2) 顔ランドマーク + ポートレート画像 → ポートレート動画
2. Self driven
2-1. 概要
「ポートレート画像」の人物を「顔ランドマーク動画」(音声付き)にあわせて動かします。
・ポートレート画像 + 顔ランドマーク動画 → ポートレート動画
2-2. Colabノートブック
「AniPortrait-jupyter」の「AniPortrait_pose2vid_jupyter」を開いて、メニュー「ファイル→ドライブにコピーを保存」でコピーして実行してください。GPUでA100を選択にした方が処理が早いです。
「output」に結果が出力されます。
2-3. 設定
「configs/prompts/animation.yaml」でポートレート画像と顔ランドマーク動画を設定できます。
test_cases:
"./configs/inference/ref_images/solo.png":
- "./configs/inference/pose_videos/solo_pose.mp4"以下のコマンドで、ポートレート動画を顔ランドマークに変換できます。
python -m scripts.vid2pose --video_path pose_video_path.mp43. Face reenacment
3-1. 概要
「ポートレート画像」の人物を「ポートレート動画」(音声付き)に合わせて動かします。
・ポートレート画像 + ポートレート動画 → ポートレート動画
3-2. Colabノートブック
「AniPortrait-jupyter」の「AniPortrait_vid2vid_jupyter」を開いて、メニュー「ファイル→ドライブにコピーを保存」でコピーして実行してください。GPUでA100を選択にした方が処理が早いです。
「output」に結果が出力されます。
3-3. 設定
「configs/prompts/animation_facereenac.yaml」でポートレート画像とポートレート動画(音声付き)を設定できます。
test_cases:
"./configs/inference/ref_images/Aragaki.png":
- "./configs/inference/video/Aragaki_song.mp4"4. Audio driven
4-1. 概要
「ポートレート画像」の人物を「音声」にあわせて口パクさせます。頭はデフォルトの頭ポーズコントロールで制御されます。
・ポートレート画像 + 音声 → ポートレート動画
4-2. Colabノートブック
「AniPortrait-jupyter」の「AniPortrait_audio2vid_jupyter」を開いて、メニュー「ファイル→ドライブにコピーを保存」でコピーして実行してください。GPUでA100を選択にした方が処理が早いです。
「output」に結果が出力されます。
4-3. 設定
「configs/prompts/animation_audio.yaml」でポートレート音声を設定できます。
test_cases:
"./configs/inference/ref_images/lyl.png":
- "./configs/inference/audio/lyl.wav"以下のコマンドで、ポートレート動画から頭ポーズコントロール用の「pose_temp.npy」に変換できます。
python -m scripts.generate_ref_pose --ref_video ./configs/inference/head_pose_temp/pose_ref_video.mp4 --save_path ./configs/inference/head_pose_temp/pose.npy以下は、ChatGPTで生成した画像とVoiceVoxで生成した音声から作ったポートレート動画になります(Audio drivenを使用)。
AniPortraitをお試し中https://t.co/IRUg7kJG1p pic.twitter.com/TBs47iVZIJ
— 布留川英一 / Hidekazu Furukawa (@npaka123) March 27, 2024
この記事が気に入ったらサポートをしてみませんか?