Dify で RAG を試す

「Dify」で「RAG」を試したので、まとめました。
前回
1. RAG
「RAG」(Retrieval Augmented Generation) は、最新の外部知識の習得とハルシネーションの軽減という、LLMの2つの主要課題に対処するためのフレームワークです。開発者はこの技術を利用して、AI搭載のカスタマーボット、企業知識ベース、AI検索エンジンなどをコスト効率よく構築できます。これらのシステムは、自然言語入力を通じて、さまざまな形態の組織化された知識と相互作用します。
下図では、ユーザーが「アメリカの大統領は誰ですか?」と尋ねると、システムは回答のためにLLMに質問を直接渡しません。代わりに、ユーザーの質問について、知識ベース (Wikipediaなど) でベクトル検索を実施します。意味的な類似性マッチングを通じて関連するコンテンツを見つけ (たとえば、「バイデンは現在の第46代アメリカ合衆国大統領です...」)、LLMに発見した知識とともにユーザーの質問を提供します。これにより、モデルは質問に答えるための十分かつ完全な知識を持つことができ、より信頼性の高い回答が得られます。

2. モデルプロバイダーの設定
今回は、「OpenAI」と「Cohere」のAPIを使います。
(1) メニュー「設定→モデルプロバイダー」で、「OpenAI」と「Cohere」のAPIキーを設定。

3. ドキュメントの準備
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のドキュメントを用意しました。
・bocchi.txt
4. 知識ベースの準備
「知識ベース」の準備手順は、次のとおりです。
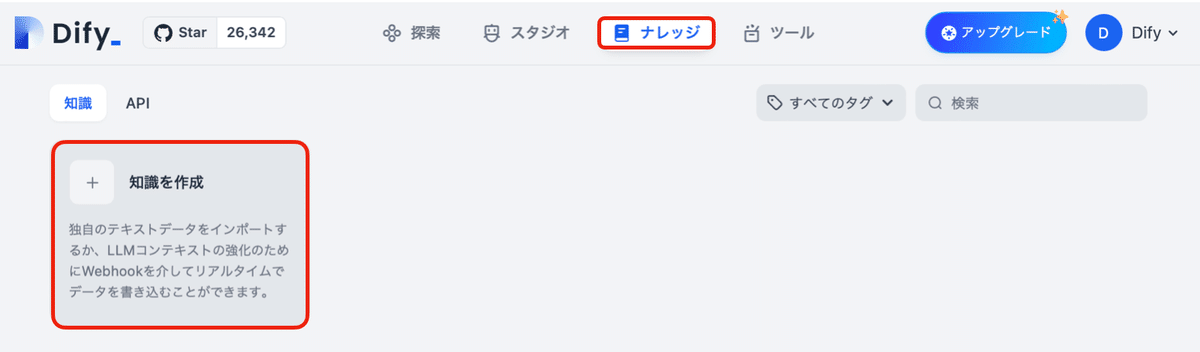
(1) 「ナレッジ」の「知識を作成」ボタンを押す。
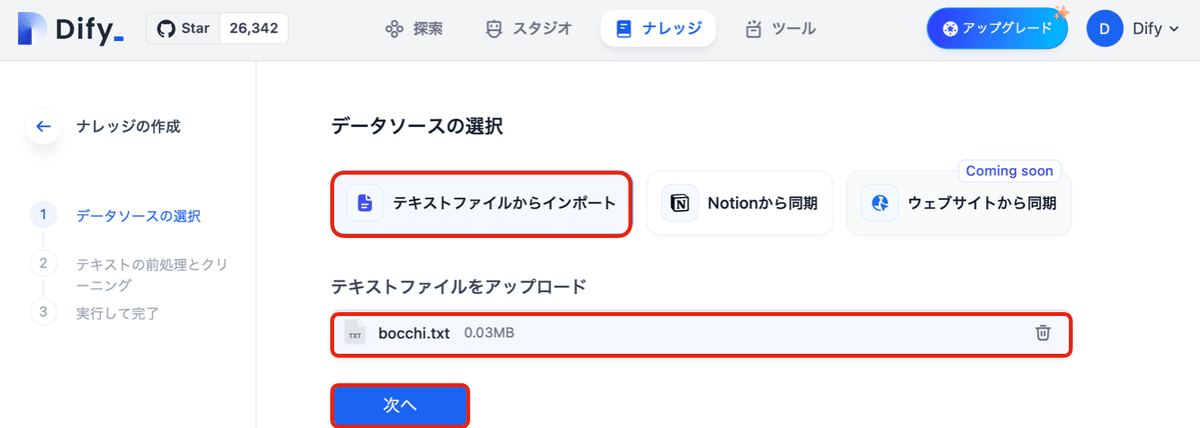
(2) 「テキストファイルからのインポート」で「テキストファイル」をアップロードして、「次へ」ボタンを押す。
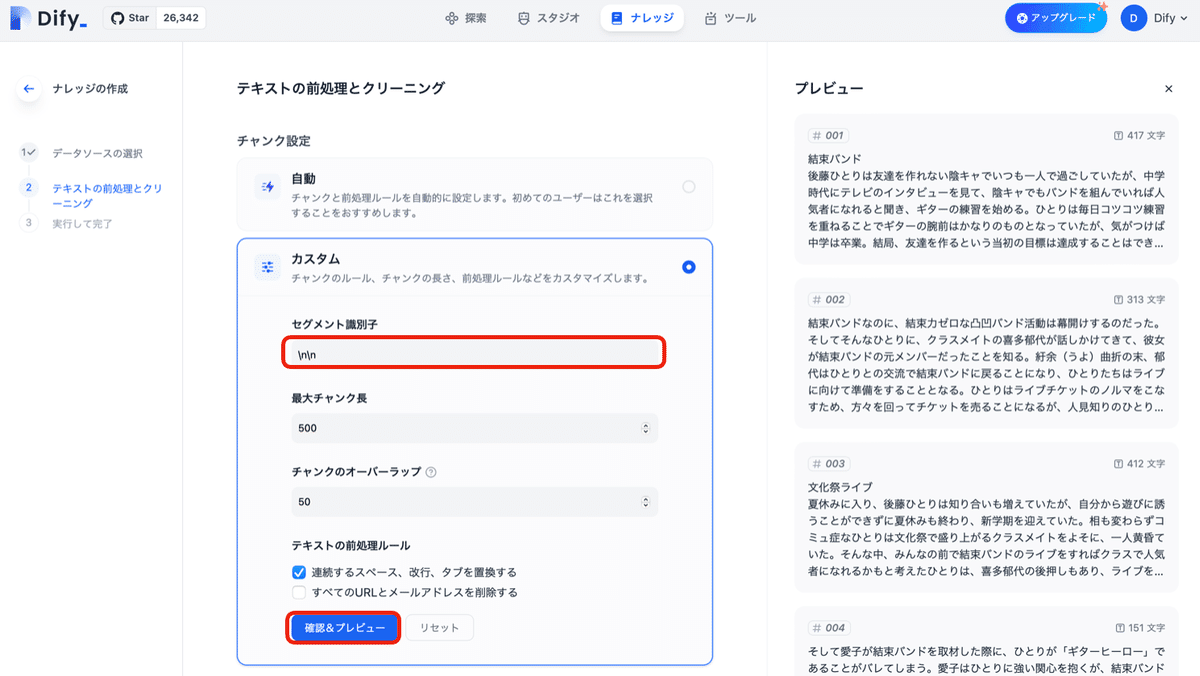
(3) 「チャンク設定」で「カスタム」を選択し、「セグメント識別子」に「\n\n」を指定して「確認&プレビュー」ボタンを押す。
今回のドキュメントのセパレータは「\n\n」のため設定しています。
(4) 「インデックスモード」に「高品質」、「検索設定」に「ベクトル検索」を設定し、「最ランクモデル」を有効化し、「保存して処理」ボタンを押す。

「インデックスモード」は、次の2つから選択します。
・高品質 : デフォルトのシステム埋め込みインターフェースを使用
・経済的 : オフラインのベクトルエンジン、キーワードインデックスなどを使用
「検索設定」は、次の3つから選択します。
・ベクトル検索 : クエリの埋め込みを生成し、そのベクトル表現に最も類似したチャンクを検索
・全文検索 : ドキュメント内のすべての用語をインデックス化し、ユーザーが任意の用語を検索してそれに関連するチャンクを検索
・ハイブリッド検索 : 全文検索とベクトル検索を同時に実行し、ユーザーのクエリに最適なマッチを選択するためにリランクを行う
「ベクトル検索」は、次のようなシナリオは得意です。
・セマンティクス理解 (ネズミ/ネズミ捕り/チーズ、Google/Bing/検索エンジン など関連ワードのマッチング)
・多言語理解 (日本語と英語など別言語のマッチング)
・マルチモーダル理解 (テキスト、画像、オーディオ、動画など別モーダルのマッチング)
・スペルミス、あいまいな説明の処理
「全文検索」は、次のようなシナリオが得意です。
・正確な照合 (製品名、個人名、製品番号など)
・少数の文字の一致 (文字数が少ないとベクトル検索の性能が低下)
・低頻度語彙の一致 (「私はあなたと一緒にコーヒーを飲みたい」の場合、「コーヒー」「飲む」は「私」「あなた」より低頻度だが重要)
「ハイブリッド検索」は、両方の検索の利点を組み合わせながら、それぞれの欠点を補います。
5. Chatflowの作成
「Chatflow」の作成手順は、次のとおりです。
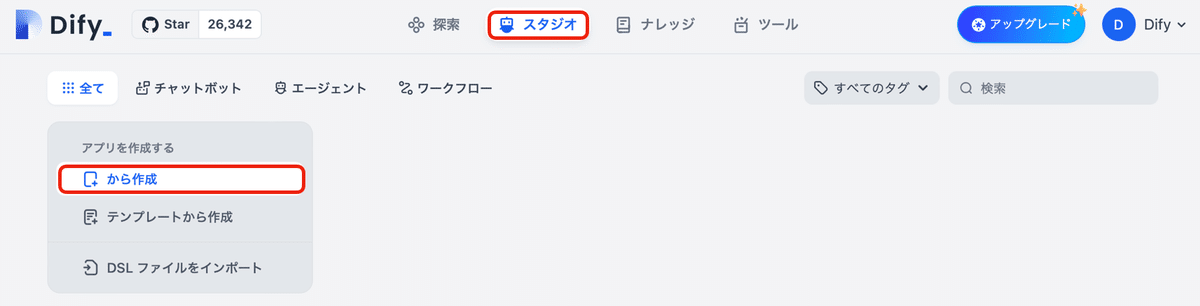
(1) 「スタジオ」の「から作成」をクリック。
(2) 「チャットボット」の「Chatflow」を選択し、「アプリとアイコンと名前」を指定し、「作成する」ボタンを押す。

(3) 「開始ノード」後の「+」で「知識取得ノード」を追加し、「N-to-1リトリーバル」に先ほど準備した知識ベースを追加。
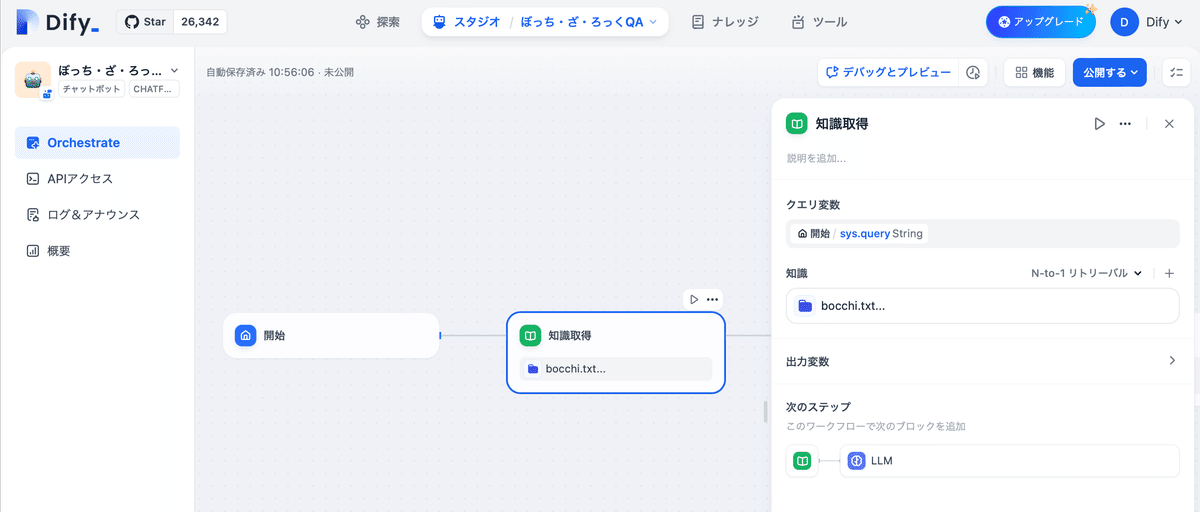
・N-to-1リトリーバル
ユーザーの意図に基づいて最も関連性の高い知識ベースで最良の結果を選択します。
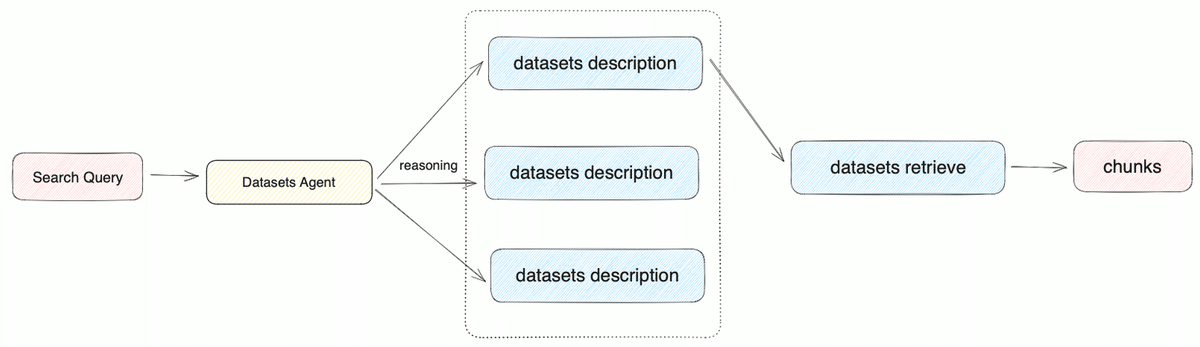
・マルチパスリトリーバル
すべての知識ベースを同時に利用し、リランクでユーザーの質問に一致する最良の結果を選択します。

(4) 「知識取得ノード」後の「LLMノード」でコンテキストとメッセージを指定。
コンテキストとクエリは「/」キー経由で追加できます。
・コンテキスト
result・SYSTEM
あなたは世界中で信頼されているQAシステムです。
事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。
従うべきいくつかのルール:
1. 回答内で指定されたコンテキストを直接参照しないでください。
2. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。・USER
コンテキスト情報は以下のとおりです。
----
{{#context#}}
----
事前知識ではなくコンテキスト情報を考慮して、質問に答えます。
Query: {{#sys.query#}}
Answer: 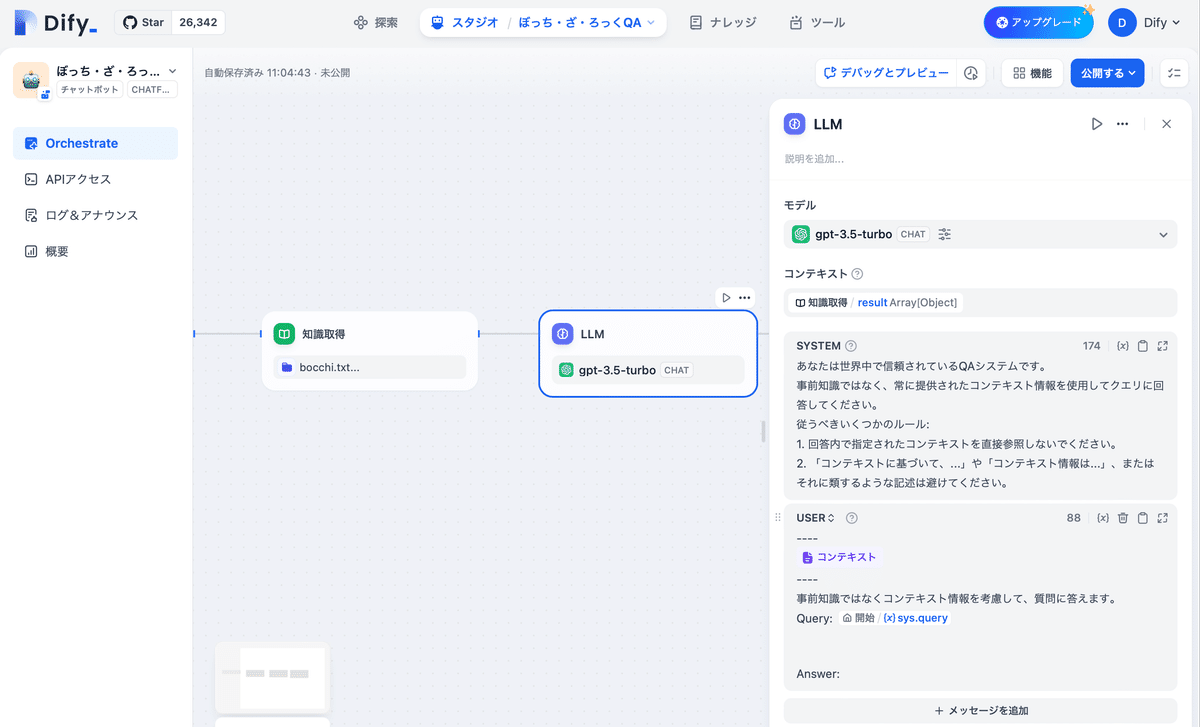
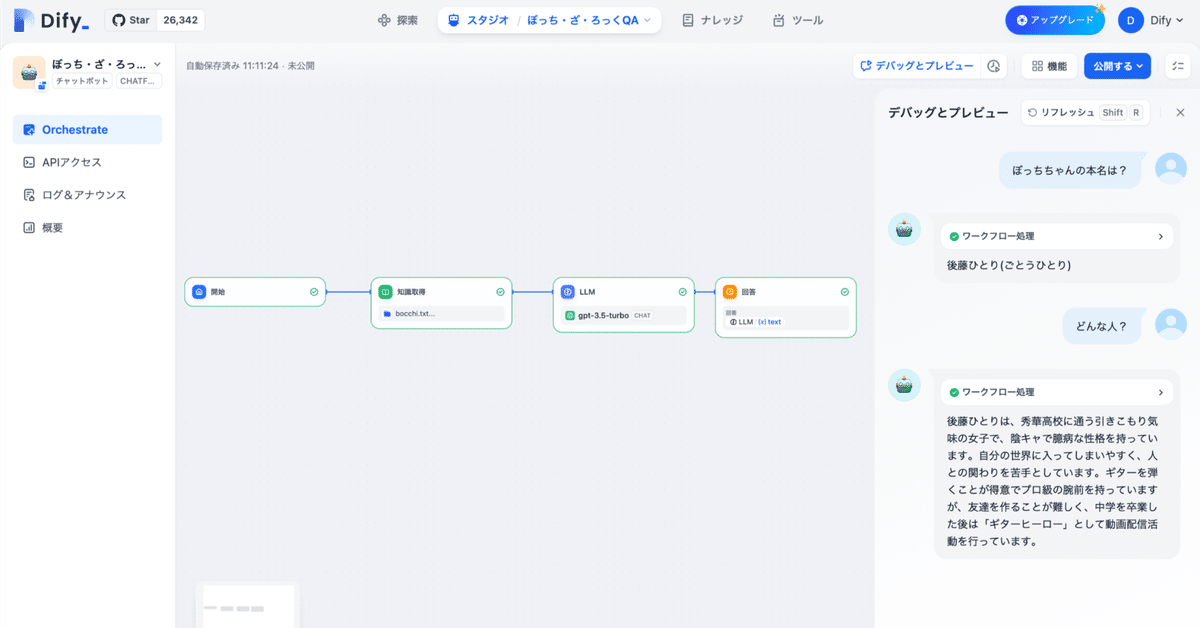
(5) 「LLMノード」後の「回答」に「text」が指定されていることを確認。
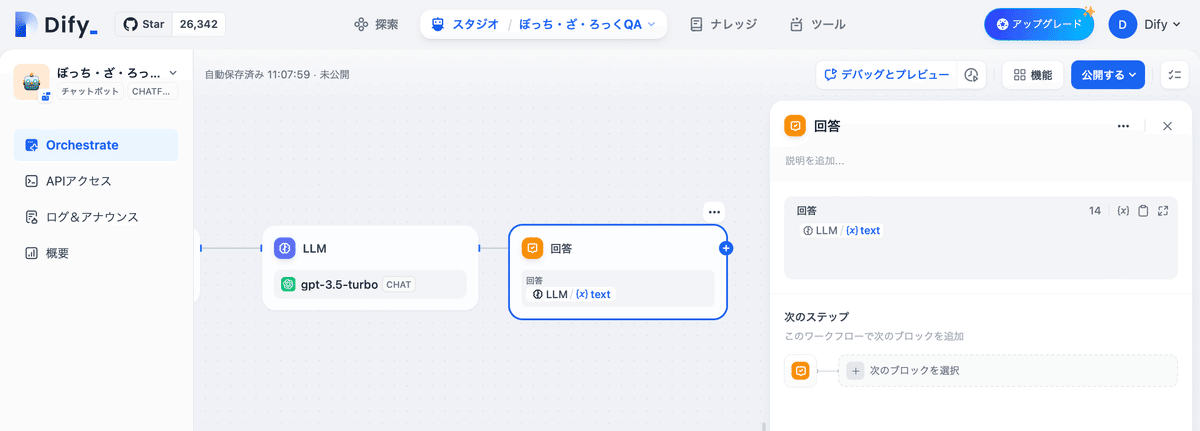
(6) 「デバッグとプレビュー」で動作確認。
