
HuggingFace Diffusers v0.17.0の新機能

「Diffusers v0.17.0」の新機能についてまとめました。
前回
1. Diffusers v0.17.0 のリリースノート
情報元となる「Diffusers 0.17.0」のリリースノートは、以下で参照できます。
2. Kandinsky 2.1
「Kandinsky 2.1」は、新しいアイデアを導入しながら、「DALL-E 2」と「Latent Diffusion」からのベストプラクティスを継承しています。
◎ インストール
pip install diffusers transformers accelerate◎ コード例
from diffusers import DiffusionPipeline
import torch
pipe_prior = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
pipe_prior.to("cuda")
t2i_pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
t2i_pipe.to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
generator = torch.Generator(device="cuda").manual_seed(12)
image_embeds, negative_image_embeds = pipe_prior(prompt, negative_prompt, guidance_scale=1.0, generator=generator).to_tuple()
image = t2i_pipe(prompt, negative_prompt=negative_prompt, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds).images[0]
image.save("cheeseburger_monster.png")
詳しくは、ドキュメントを参照。
3. UniDiffuser
「UniDiffuser」は、単一の統一されたアプローチを使用して、異なる生成タスクを処理できるマルチモーダル拡散プロセスを導入しています。
・無条件の画像とテキストの生成
・共同画像テキスト生成
・テキストからの画像生成
・画像からのテキスト生成
・画像のバリエーション
・テキストのバリエーション
◎ コード例
import torch
from diffusers import UniDiffuserPipeline
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to("cuda")
# This mode can be inferred from the input provided to the `pipe`.
pipe.set_text_to_image_mode()
prompt = "an elephant under the sea"
sample = pipe(prompt=prompt, num_inference_steps=20, guidance_scale=8.0).images[0]
sample.save("elephant.png")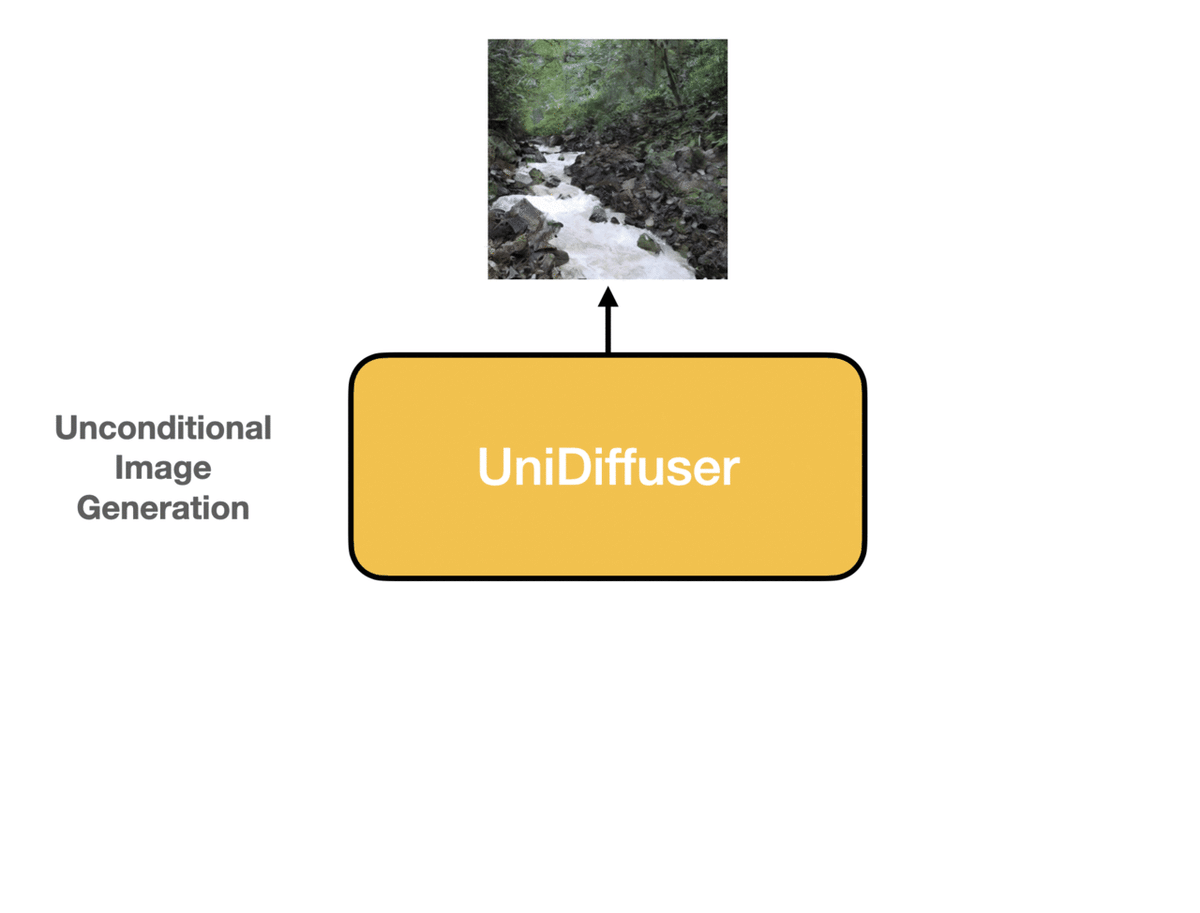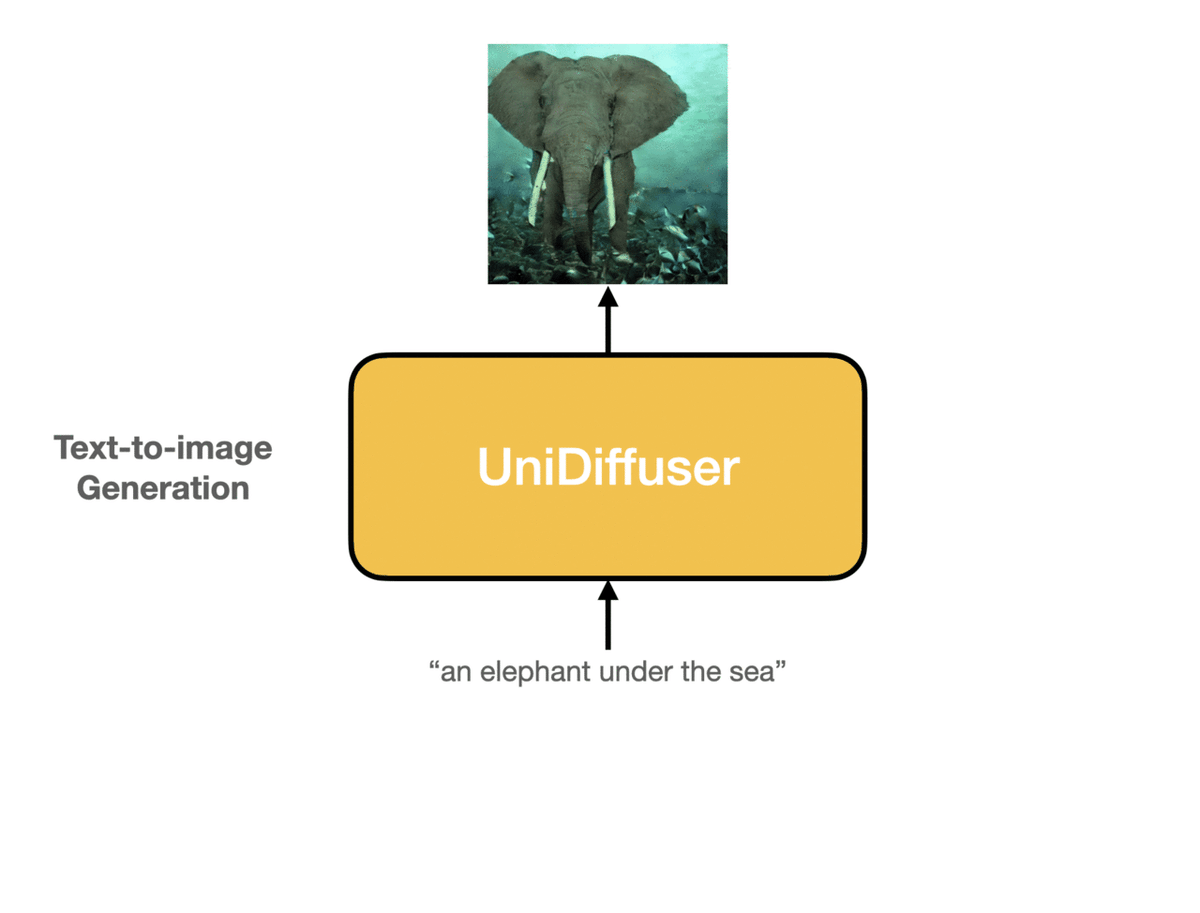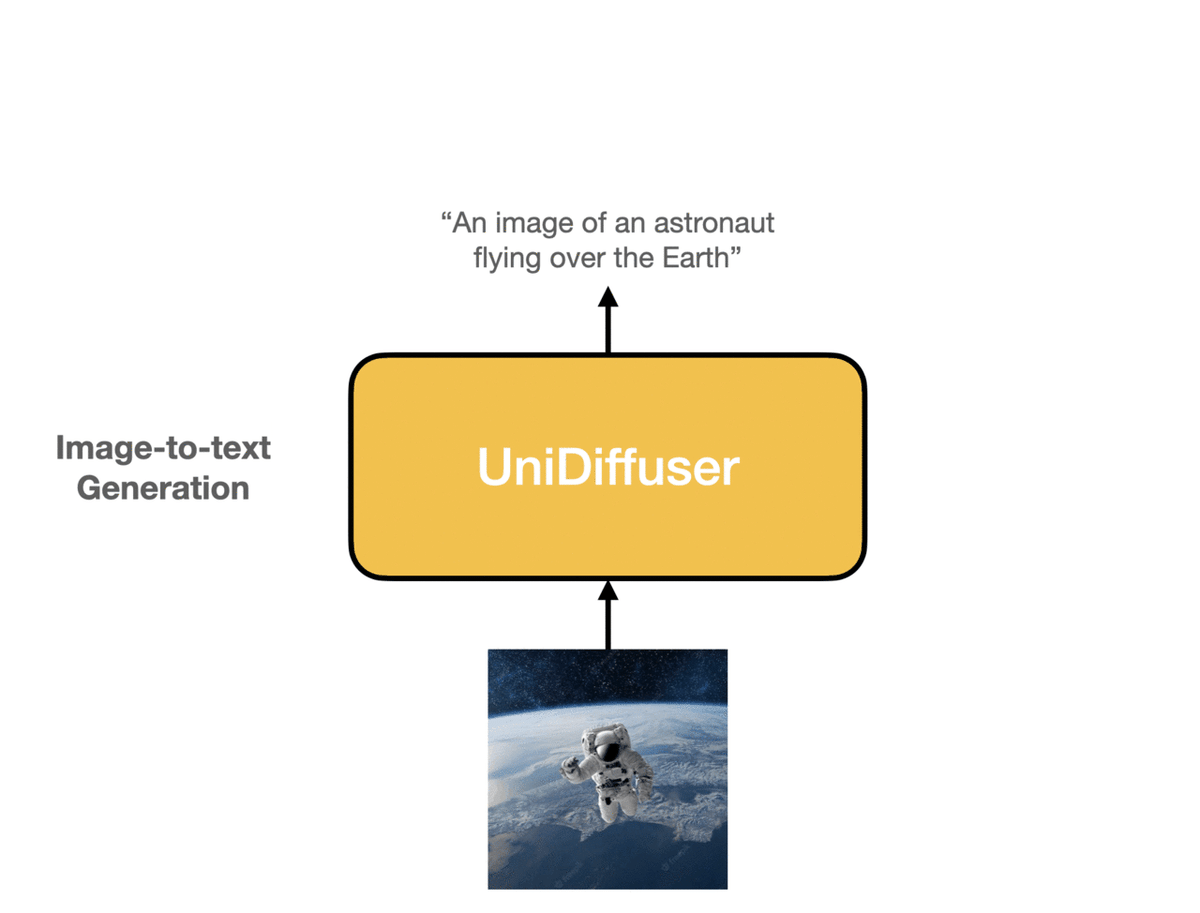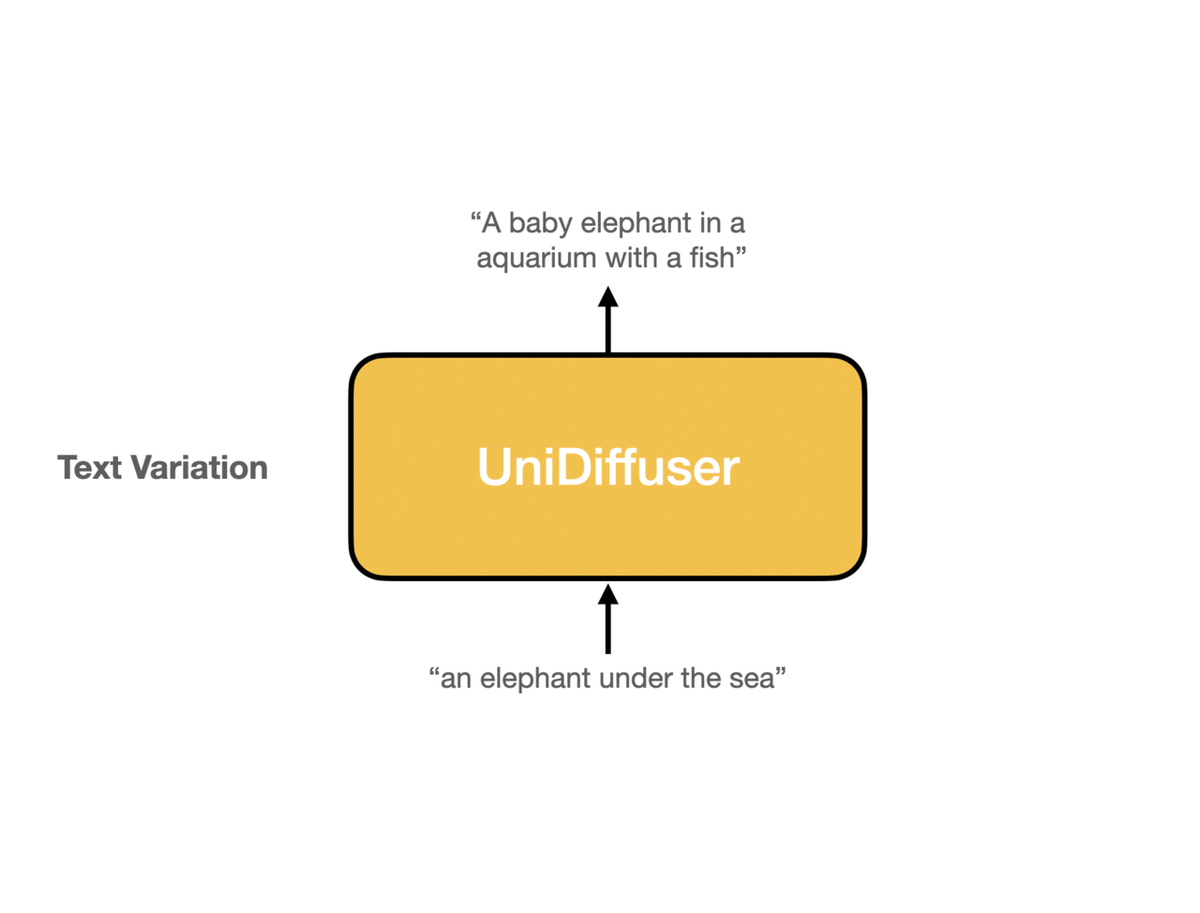
詳しくは、ドキュメントを参照。
4. LoRA
A1111フォーマットのCivitAI LoRAチェックポイントを限られた容量でサポートします。
(1) チェックポイントをダウンロード。
wget https://civitai.com/api/download/models/15603 -O light_and_shadow.safetensors(2) DiffusionPipelineを初期化。
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipeline = StableDiffusionPipeline.from_pretrained(
"gsdf/Counterfeit-V2.5", torch_dtype=torch.float16, safety_checker=None
).to("cuda")
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
pipeline.scheduler.config, use_karras_sigmas=True
)(3) CivitAIからダウンロードしたチェックポイントをロード。
safetensors形式でチェックポイントをロードする場合は、safetensorsがインストールされていることを確認してください。
pipeline.load_lora_weights(".", weight_name="light_and_shadow.safetensors")(4) 推論を実行。
prompt = "masterpiece, best quality, 1girl, at dusk"
negative_prompt = ("(low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), "
"bad composition, inaccurate eyes, extra digit, fewer digits, (extra arms:1.2), large breasts")
images = pipeline(prompt=prompt,
negative_prompt=negative_prompt,
width=512,
height=768,
num_inference_steps=15,
num_images_per_prompt=4,
generator=torch.manual_seed(0)
).images以下は、LoRAと非LoRAの結果の比較です。

詳しくは、ドキュメントを参照。
5. Torch 2.0 Compile Speed-up
Attentionを効率的に計算するためのTorch 2.0サポートを導入しました。モデルをtorch.compile()でコンパイルできるように、モデルの「graph breaks」の数を減らすように多くの改善を行いました。その結果、最も人気のあるパイプラインの推論速度の大幅な改善できました。
詳しくは、ドキュメントを参照。
6. VAE pre-processing
パイプラインが画像入力を準備し、出力を後処理するための統一されたAPIを提供するVae Imageプロセッサクラスを追加しました。PIL Image、PyTorch、Numpy配列間のサイズ変更、正規化、変換をサポートします。
これにより、すべてのStable Diffusionパイプラインは、PIL Imageに加えて、Pytorch TensorとNumpy配列の形式で画像入力を受け入れ、これら3つの形式で出力を生成することができます。また、潜在性を受け入れて返します。これは、あるパイプラインから生成された潜在性を取り出し、潜在空間を離れることなく、入力として別のパイプラインに渡すことができることを意味します。複数のパイプラインで作業する場合は、PILイメージに変換せずに、Pytorch Tensorを渡すことができます。
詳しくは、ドキュメントを参照。
7. ControlNet Img2Img & Inpainting
「ControlNet」は最も使用されているDiffusionモデルの1つであり、コミュニティからの強い需要に応じて、controlnet img2imgとcontrolnet inpaintパイプラインを追加しました。これにより、image-2-image設定とinpaintの両方にControlNetチェックポイントを使用できます。
◎ コード例
from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import numpy as np
import torch
import cv2
from PIL import Image
# download an image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
np_image = np.array(image)
# get canny image
np_image = cv2.Canny(np_image, 100, 200)
np_image = np_image[:, :, None]
np_image = np.concatenate([np_image, np_image, np_image], axis=2)
canny_image = Image.fromarray(np_image)
# load control net and stable diffusion v1-5
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
# generate image
generator = torch.manual_seed(0)
image = pipe(
"futuristic-looking woman",
num_inference_steps=20,
generator=generator,
image=image,
control_image=canny_image,
).images[0]8. Diffedit Zero-Shot Inpainting Pipeline
「Diffedit Zero-Shot Inpainting Pipeline」は、自然言語での画像編集を可能にします。以下はエンドツーエンドの例です。
(1) パイプラインの読み込み。
import torch
from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionDiffEditPipeline
sd_model_ckpt = "stabilityai/stable-diffusion-2-1"
pipeline = StableDiffusionDiffEditPipeline.from_pretrained(
sd_model_ckpt,
torch_dtype=torch.float16,
safety_checker=None,
)
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
pipeline.enable_model_cpu_offload()
pipeline.enable_vae_slicing()
generator = torch.manual_seed(0)(2) 入力画像をロードして、次の方法で編集。
from diffusers.utils import load_image
img_url = "https://github.com/Xiang-cd/DiffEdit-stable-diffusion/raw/main/assets/origin.png"
raw_image = load_image(img_url).convert("RGB").resize((768, 768))(3) ソースとターゲットのプロンプトを使用して編集マスクを生成。
source_prompt = "a bowl of fruits"
target_prompt = "a basket of fruits"
mask_image = pipeline.generate_mask(
image=raw_image,
source_prompt=source_prompt,
target_prompt=target_prompt,
generator=generator,
) (4) キャプションと入力画像を使用して、反転した潜在性を取得。
inv_latents = pipeline.invert(prompt=source_prompt, image=raw_image, generator=generator).latents(5) 反転した潜在性と意味的に生成されたマスクで画像を生成。
image = pipeline(
prompt=target_prompt,
mask_image=mask_image,
image_latents=inv_latents,
generator=generator,
negative_prompt=source_prompt,
).images[0]
image.save("edited_image.png")
詳しくは、ドキュメントを参照。
次回
この記事が気に入ったらサポートをしてみませんか?