
Stable Baselines入門 / Stable Baselinesの概要

1. Stable Baselinesとは
「Stable Baselines」は「OpenAI Baselines」をベースにした、強化学習アルゴリズムの実装セットの改良版です。
「OpenAI Baselines」は、OpenAIが提供する強化学習アルゴリズムの実装セットです。これら学習アルゴリズムは正しく機能し、非常に役立つものでした。しかしこれをベースにカスタマイズして使う場合には、「コメントの欠如」「共通のコードスタイルなし」「多数重複」なソースコードのため、かなりの格闘が必要になりました。
そこで、「OpenAI Baselines」をフォークし、大規模なリファクタリングを行い使いやすくしたものが、「Stable Baselines」になります。
2. Stable Baselinesの特徴
「Stable Baselines」の「OpenAI Baselines」と比べた時の特徴は、次の通りです。
・全アルゴリズムの統一構造
・統一コードスタイル(PEP8準拠)
・文書化された関数とクラス
・より多くのテストとより多くのコードカバレッジ
3. Stable Baselinesの強化学習アルゴリズム
「Stable Baselines」は「OpenAI Baselines」と同様に、強化学習アルゴリズムとしてA2C、PPO、TRPO、DQN、ACKTR、ACERおよびDDPGをサポートします。
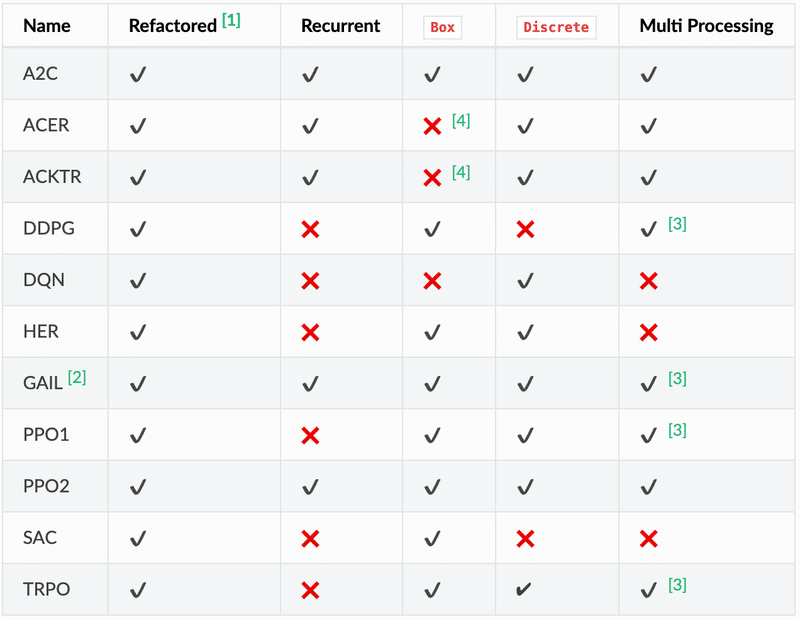
・Name:強化学習アルゴリズム名
・Refactored:リファクタリング済みかどうか
・Recurrent:リカレント(過去の記憶)な学習が可能かどうか
・Box:状態空間・行動空間としてBoxを利用可能かどうか。
・Discrete:状態空間・行動空間としてDiscreteを利用可能かどうか。
・Multi Processing:マルチプロセッシングで並列に学習できるかどうか
BoxとDiscreteは状態空間・行動空間の型です。
・Boxは範囲[low、high]の連続値。Float型の多次元配列。【例】[0.6, 0.2, 0.3]
・Discreteは範囲[0、n-1]の離散値。Int型の1次元配列。【例】[3]
4. Stable Baselinesのシステムパッケージのインストール
はじめに「Stable Baselines」の動作に必要なシステムパッケージをインストールします。
【macOS】
brew install cmake openmpi【Ubuntu】
sudo apt-get update && sudo apt-get install cmake libopenmpi-dev python3-dev zlib1g-dev5. Stable Baselinesのインストール
「Stable Baselines」にはPython 3.5以降がが必要です。Anacondaの仮想環境を作成し、stable-baselinesパッケージをインストールします。
pip install stable-baselines
pip install tensorflow==1.14.0
pip install pyqt5
pip install box2d box2d-kengz
pip install imageio6. Sable Baselinesの学習
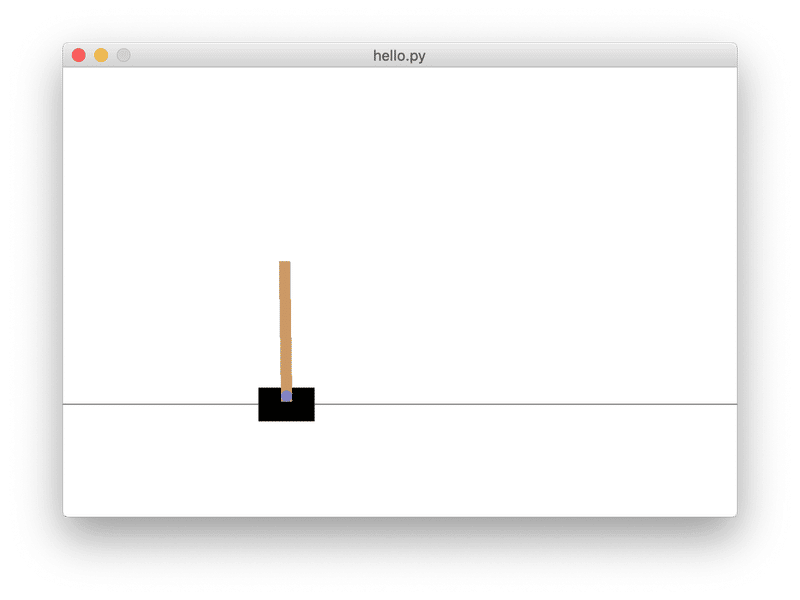
「Stable Baselines」では、PPOエージェントによる学習を、次のように簡潔に記述できます。「エージェント」(学習アルゴリズム)は、train()、predict()、save()、load()といった共通メソッドを利用できます。
import gym
from stable_baselines.bench import Monitor
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
# 環境の生成
env = gym.make('CartPole-v1')
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2(MlpPolicy, env, verbose=1)
# モデルの学習
model.learn(total_timesteps=10000)
# テスト
state = env.reset()
for i in range(200):
env.render()
action, _ = model.predict(state)
state, reward, done, info = env.step(action)◎ベクトル化環境
PPO2のように複数環境で訓練するアルゴリズムは、環境を「ベクトル化環境」に変換してから利用する必要があり、シングルプロセスで十分な場合はDummyVecEnvを使います。
・DummyVecEnv:シングルプロセスのベクトル化環境ラッパー
・SubprocVecEnv:マルチプロセスのベクトル化環境ラッパー
◎ポリシーネットワーク
エージェントの生成には、ポリシーと環境が必要です。Stable Baselinesでは以下のポリシーが用意されています。
・MlpPolicy:MLPを使用して、Actor-Criticを実装するポリシー
・MlpLstmPolicy:MLPとLSTMを使用して、Actor-Criticを実装するポリシー
・MlpLnLstmPolicy:MLPとlayer normalized LSTMを使用して、Actor-Criticを実装するポリシー
・CnnPolicy:CNNを使用して、Actor-Criticを実装するポリシー
・CnnLstmPolicy:CNNとLSTMを使用して、Actor-Cliticを実装するポリシー
・CnnLnLstmPolicy:CNNとlayer normalized LSTMを使用して、Actor-Criticを実装するポリシー
「CnnPolicies」はイメージ用で、「MlpPolicies」はそれ以外(ロボット関節など)用です。ポリシーをカスタマイズするには、パラメータ「policy_kwargs」を使います。より細かく制御する必要がある場合は、Custom Polikcyを生成することもできます。
実行すると次の画面とログが表示されます。
--------------------------------------
| approxkl | 8.6919084e-05 |
| clipfrac | 0.0 |
| explained_variance | -0.000483 |
| fps | 443 |
| n_updates | 1 |
| policy_entropy | 0.6930789 |
| policy_loss | -0.0024873326 |
| serial_timesteps | 128 |
| time_elapsed | 3.1e-06 |
| total_timesteps | 128 |
| value_loss | 54.57497 |
--------------------------------------
:
---------------------------------------
| approxkl | 2.5313466e-06 |
| clipfrac | 0.0 |
| explained_variance | 0.0169 |
| fps | 2044 |
| n_updates | 78 |
| policy_entropy | 0.585216 |
| policy_loss | -0.00025959627 |
| serial_timesteps | 9984 |
| time_elapsed | 5.24 |
| total_timesteps | 9984 |
| value_loss | 68.08393 |
---------------------------------------
7. 平均報酬と平均エピソード長の表示
上記コードでも学習時のログがでますが、肝心の「平均報酬」(ep_reward_mean)と「平均エピソード長」(ep_len_mean)が表示されません。
「Monitor」を追加することで、表示されるようになります。
import gym
import os
from stable_baselines.bench import Monitor
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('CartPole-v1')
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2(MlpPolicy, env, verbose=1)
# モデルの学習
model.learn(total_timesteps=10000)
# テスト
state = env.reset()
for i in range(200):
env.render()
action, _ = model.predict(state)
state, reward, done, info = env.step(action)ログは次の通りです。
--------------------------------------
| approxkl | 0.00010607178 |
| clipfrac | 0.0 |
| ep_len_mean | 25.2 |
| ep_reward_mean | 25.2 |
| explained_variance | -0.00763 |
| fps | 438 |
| n_updates | 1 |
| policy_entropy | 0.6930357 |
| policy_loss | -0.0031061308 |
| serial_timesteps | 128 |
| time_elapsed | 1.91e-06 |
| total_timesteps | 128 |
| value_loss | 42.66241 |
--------------------------------------
:
---------------------------------------
| approxkl | 3.9626757e-05 |
| clipfrac | 0.0 |
| ep_len_mean | 85.8 |
| ep_reward_mean | 85.8 |
| explained_variance | 0.0234 |
| fps | 1798 |
| n_updates | 78 |
| policy_entropy | 0.5740223 |
| policy_loss | -0.00036769366 |
| serial_timesteps | 9984 |
| time_elapsed | 5.23 |
| total_timesteps | 9984 |
| value_loss | 68.69821 |
---------------------------------------
この記事が気に入ったらサポートをしてみませんか?