
Simple Transformers 入門 (3) - 質問応答

「Simple Transformers」で「質問応答」を行う方法をまとめました。
1. 質問応答
「質問応答」は、コンテキストから質問の回答を抽出するタスクです。
サポートモデルは、次のとおりです。
・ALBERT
・BERT
・DistilBERT
・ELECTRA
・XLM
・XLNet
「質問応答」の最小限のコードは、次のとおりです。
from simpletransformers.question_answering import QuestionAnsweringModel
import json
import os
import logging
# ログの設定
logging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.WARNING)
# 学習データ
train_data = [
{
'context': "This is the first context",
'qas': [
{
'id': "00001",
'is_impossible': False,
'question': "Which context is this?",
'answers': [
{
'text': "the first",
'answer_start': 8
}
]
}
]
},
{
'context ':"Other legislation followed, including the Migratory Bird Conservation Act of 1929, a 1937 treaty prohibiting the hunting of right and gray whales,
and the Bald Eagle Protection Act of 1940. These later laws had a low cost to society—the species were relatively rare—and little opposition was raised",
'qas': [
{
'id': " 00002",
'is_im possible': False,
'ques tion': "What was the cost to society?",
'ans wers': [
{
'text': "low cost",
'answer_start': 225
}
]
},
{
'id': "00003",
'is_impossible': False,
'question': "What was the name of the 1937 treaty?",
'answers': [
{
'text': "Bald Eagle Protection Act",
'answer_start': 167
}
]
}
]
}
]
# JSONファイルの保存
os.makedirs('data', exist_ok=True)
with open('data/train.json', 'w') as f:
json.dump(train_data, f)
# モデルの作成
model = QuestionAnsweringModel('distilbert', 'distilbert-base-uncased-distilled-squad',
args={'reprocess_input_data': True, 'overwrite_output_dir': True})
# 学習
model.train_model('data/train.json')
# 学習データは直接使用することも可能
# model.train_model(train_data)
# 評価
result, text = model.eval_model('data/train.json')
print(result)
print(text)
# 予測
to_predict = [{
'context': 'This is the context used for demonstrating predictions.',
'qas': [{
'question': 'What is this context?',
'id': '0'
}]}]
print(model.predict(to_predict))◎ 学習データと評価データ
学習データと評価データは、以下のような辞書形式になります。
{
# コンテキスト
'context': "This is the first context",
# 質問と回答のリスト
'qas': [
{
'id': "00001", # 質問ID
'question': "Which context is this?", # 質問
'is_impossible': False, # 質問に正しく回答できないかどうか
'answers': [ # 正解のリスト
{
'text': "the first", # 回答
'answer_start': 8 # コンテキスト内の回答の開始インデックス
}
]
}
]
},2. 質問応答のデータセット
主な「質問応答」のデータセットは、次のとおりです。
・SQuAD 2.0 - Question Answering
3-1. QuestionAnsweringModel
「QuestionAnsweringModel」は、「質問応答」で使用するクラスです。
◎ コンストラクタ
コンストラクタの書式は、次のとおりです。
QuestionAnsweringModel (model_type, model_name, args=None, use_cuda=True)
パラメータは、次のとおりです。
・model_type : (required) str - モデル種別。
・model_name : (required) str - Huggingface Transformersの事前学習済みモデル名、またはモデルファイルを含むディレクトリへのパス。
・args : (optional) dict - オプション引数。
・use_cuda : (optional) bool - CUDAを使用するかどうか。
・cuda_device : (optional) str - CUDAデバイス。
◎ クラス属性
クラス属性は、次のとおりです。
・tokenizer : トークナイザー。
・model : モデル。
・model_name : Huggingface Transformersの事前学習済みモデル名、またはモデルファイルを含むディレクトリへのパス。
・device : デバイス。
・results : 評価結果。
・args : オプション引数。
・cuda_device : (optional) - CUDAデバイス。
◎ train_model()
学習します。
train_model(self, train_df, output_dir=None, args=None, eval_df=None)
パラメータは、次のとおりです。
・train_df : 学習データのDataFrame。
・output_dir : (optional) - 出力ディレクトリ。
・args : (optional) - オプション引数。
・show_running_loss : (optional) - 損失出力。
・eval_df : (optional) - 評価データのDataFrame。
・**kwargs : 追加のメトリック。
◎ eval_model()
評価します。
eval_model(self, eval_df, output_dir=None, verbose=False)
パラメータは、次のとおりです。
・eval_df : 評価データのDataFrame。
・output_dir : 出力ディレクトリ。
・verbose : 詳細出力。
・silent : プログレスバーの非表示。
・**kwargs : 追加のメトリック。
戻り値は、次のとおりです。
・result: 評価結果 (correct, similar, incorrect)。
・text: correct_text、similar_text、incorrect_textを含む辞書。
◎ predict()
予測します。
predict(self, to_predict)
パラメータは、次のとおりです。
・to_predict : 予測するコンテキストと質問のペアのリスト。
・n_best_size: (Optional) - 返す予測数。
E.g: predict([
{
'context': "Some context as a demo",
'qas': [
{'id': '0', 'question': 'What is the context here?'},
{'id': '1', 'question': 'What is this for?'}
]
}
])戻り値は、次のとおりです。
・preds: 予測した回答と、各質問のIDを含むPythonリスト。
3-2. QuestionAnsweringModelの追加パラメータ引数
デフォルト値は、次のとおりです。
'doc_stride': 384,
'max_query_length': 64,
'n_best_size': 20,
'max_answer_length': 100,
'null_score_diff_threshold': 0.0
パラメータは、次のとおりです。
・doc_stride: int - 長いドキュメントをチャンクに分割する場合、チャンク間でどのくらいのストライドを取るか。
・max_query_length: int - 質問の最大トークン長。 これより長い質問は、この長さに切り捨てられる。
・n_best_size: int - 質問ごとに与えられた予測の数。
・max_answer_length: int - 生成できる回答の最大トークン長。
・null_score_diff_threshold: float - null_scoreの場合-best_non_nullがしきい値よりも大きい場合はnullを予測。
4. 日本語のデータセットでの質問応答
日本語のデータセットでの「質問応答」を行います。
◎ Simple Transformersのインストール
以下のコマンドでSimple Transformersをインストールします。
# Simple Transformersのインストール
!pip install transformers
!pip install simpletransformers◎ データセットの準備
(1) 運転ドメインQAデータセットのサイトからDDQA-1.0.tar.gzをダウンロード。
(2) Google Colabにアップロード。
左端のファイルのブラウジングからアップロードします。
(3) 以下のコマンドで解凍。
# データセットの解凍
!tar -xvf DDQA-1.0.tar.gz◎ データセットの前処理
データセットを読み込みます。
import json
# 学習データ
with open('DDQA-1.0/RC-QA/DDQA-1.0_RC-QA_train.json', 'r') as f:
train_data = json.load(f)
train_data = [item for topic in train_data['data'] for item in topic['paragraphs']]
# 評価データ
with open('DDQA-1.0/RC-QA/DDQA-1.0_RC-QA_test.json', 'r') as f:
eval_data = json.load(f)
eval_data = [item for topic in eval_data['data'] for item in topic['paragraphs']]◎ 学習と評価
学習と評価を実行します。Huggingface Transformersの日本語BERTモデル「cl-tohoku/bert-base-japanese-whole-word-masking」を利用します。
from simpletransformers.question_answering import QuestionAnsweringModel
# モデルの作成
model = QuestionAnsweringModel('bert', 'cl-tohoku/bert-base-japanese-whole-word-masking',
args={'reprocess_input_data': True, 'overwrite_output_dir': True})
# 学習
model.train_model(train_data)
# 評価
result, text = model.eval_model(eval_data)
print(result){'correct': 457, 'similar': 496, 'incorrect': 71, 'eval_loss': -6.630337547709924}正解(correct)は457、同様(similar)は496、不正解(71)、評価時の損失(eval_loss)は-6.630となりました。
◎ TensorBoardでの確認
学習時の損失が最適化されてる様子を、TensorBoardでも確認してみます。
%load_ext tensorboard
%tensorboard --logdir runs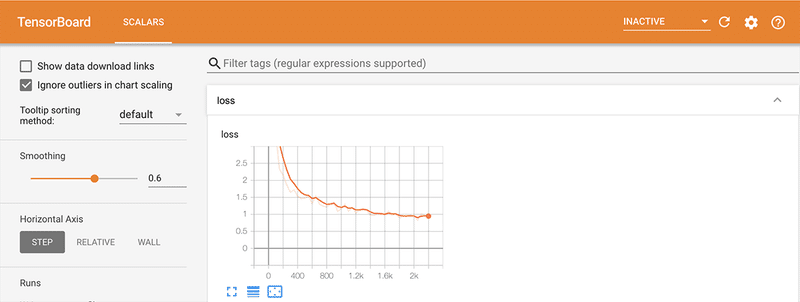
◎ 予測
予測を実行します。
to_predict = [{"context": "本日お昼頃、上野方面へ自転車で出かけました。", "qas": [{"id": "0", "question": "どこへ出掛けた?"}]}]
print(model.predict(to_predict))([{'id': '0', 'answer': ['上野方面', '上野方面へ自転車', '自転車', '本日お昼頃、上野方面', 'お昼頃、上野方面', '上野方面へ自転車で出かけました。', '野方面', '本日お昼頃、上野方面へ自転車', '上野方', '上', '上野方面へ', '自転車で出かけました。', '上野方面へ自転車で出かけました', 'お昼頃、上野方面へ自転車', '上野方面へ自転車で', '方面', '上野', '上野方面へ自転', '面', '野方面へ自転車']}], [{'id': '0', 'probability': [0.8766171813515922, 0.0957007980766471, 0.018918360164162207, 0.004012247819599146, 0.0011152495597627364, 0.0008316207004708825, 0.0006286604537355076, 0.00043801938472721005, 0.0003683543539959805, 0.00020690570679733248, 0.00019201166694403845, 0.00016439674744280064, 0.00012834527641520106, 0.00012175243104334729, 0.00011928098362375667, 0.0001191354657894015, 8.99501253785711e-05, 8.33529064708731e-05, 7.574559980088946e-05, 6.863122058474115e-05]}])この記事が気に入ったらサポートをしてみませんか?