
LlamaIndex v0.7 のデータエージェント

以下の記事が面白かったので、軽くまとめました。
1. データエージェント
「データエージェント」は、LLMを利用したナレッジワーカーです。データに対して「読み取り」と「書き込み」の両タスクをインテリジェントに実行することができます。
「データエージェント」では、次のようなタスクが可能になります。
・「非構造化データ」「半構造化データ」「構造化データ」など、様々なデータに対して自動検索と取得を実行。
・構造化された方法での「外部サービスAPI」 の呼び出し。レスポンスをすぐに処理することも、インデックス化 / キャッシュすることも可能。
・会話履歴の保存。
・上記のすべてを使用して、「単純なデータタスク」と「複雑なデータタスク」の両方を実行。

「データエージェント」を構築するために、「エージェント側」と「ツール側」の両方で、「抽象化」「サービス」「ガイド」を提供しています。
・General Agent/Tool 抽象化 : エージェントループを構築し、構造化されたAPI定義に従ってそれらのループがツールと対話するための一連の抽象化。
・LlamaHub ツールリポジトリ : LlamaHub内の新しいセクションで、接続可能な 15以上のツールを提供。 (Google Calendar、Notion、SQL、OpenAPI など)
2. コアコンポーネント
「データエージェント」は、次の「コアコンポーネント」で構成されています。
・ツール
・推論ループ
2-1. ツール
「データエージェント」には、対話するための「ツール」 (API) が提供されます。これらのAPI は、世界に関する情報を取得したり、状態を変更したりできます。 各「ツール」はリクエスト / レスポンスのインターフェイスを公開します。リクエストは構造化されたパラメータのセットであり、レスポンスは任意の形式にすることができます。
2-2. 推論ループ
入力が与えられると、「データエージェント」は「推論ループ」を使用して、どの「ツール」をどの「順序」で使用するか、各「ツール」を呼び出すパラメータを決定します。「ループ」は概念的には非常に単純なもの (ワンステップのツール選択プロセス) もあれば、複雑なもの (各ステップで多数のツールが選択される複数ステップの選択プロセス) もあります。

3. エージェントの抽象化
「エージェント」は一連のツールを受け取ります。
「エージェント」は、入力タスクを取り込むため、 「チャット」と「クエリ」の両方をサポートしています。実際、「BaseAgent」は「BaseChatEngine」と「BaseQueryEngine」を継承しています。
現在、次の2つのエージェント種別をサポートしています。
・OpenAI Function エージェント (OpenAI Function API 上で動作)
・ReAct エージェント (あらゆるチャット/テキスト補完エンドポイントで動作)
使い方は、次のとおりです。
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# ツールのインポートと定義
...
# LLMの初期化
llm = OpenAI(model="gpt-3.5-turbo-0613")
# OpenAIエージェントの初期化
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# ReActエージェントの初期化
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# エージェントの使用
response = agent.chat("What is (121 * 3) + 42?")「推論ループ」はエージェント種別によって異なります。
3-1. OpenAI Function エージェント
「OpenAI Function エージェント」は、「ツール」の決定ロジックがFunction API に組み込まれています。入力プロンプトと会話履歴が与えられると、Function API は別の関数呼び出しを行う (ツール選択) か、アシスタントメッセージを返すかを決定します。API が関数呼び出しを返した場合、その関数を実行し、会話履歴に関数メッセージを渡す責任があります。API がアシスタントメッセージを返した場合、ループは完了します (タスクは解決されたと想定)。
3-2. React エージェント
「ReAct エージェント」は一般的なテキスト補完エンドポイントを使用するため、任意のLLMで使用できます。 テキスト補完エンドポイントには単純なTextToTextがあり、推論ロジックをプロンプト内でエンコードする必要があることを意味します。「ReAct エージェント」は、どの「ツール」を選択するかを決定するために、ReAct論文からインスピレーションを得たプロンプトを使用します。
...
You have access to the following tools:
{tool_desc}
To answer the question, please use the following format.
```
Thought: I need to use a tool to help me answer the question.
Action: tool name (one of {tool_names})
Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. {{"text": "hello world", "num_beams": 5}})
```
Please use a valid JSON format for the action input. Do NOT do this {{'text': 'hello world', 'num_beams': 5}}.
If this format is used, you will receive a response in the following format:
```
Observation: tool response
```
...次のツールにアクセスできます。
{tool_desc}
質問の回答には、次の書式を使用してください。
```
Thought: 質問に答えるのに役立つツールを使用する必要がある。
Action: ツール名 ({tool_names} の 1 つ)
Action Input: kwarg を表すJSON形式のツールへの入力 (例: {{"text": "hello world", "num_beams": 5}})
```
Action Inputには有効な JSON形式を使用してください。 {{'text': 'hello world', 'num_beams': 5}}は使用しないでください。
この書式を使用すると、次の書式で応答が返されます。
```
Observation: ツールの反応
```
...
4. ツールの抽象化
「ツール」の定義は、人間による使用ではなくエージェントによる使用を目的としている点を除いて、任意のAPIインターフェイスの定義と似ています。ユーザーは単一のツールと、内部に一連の機能を含む「ToolSpec」の両方を定義できます。
4-1. BaseTool
「BaseTool」は非常に汎用的なインターフェイスを定義します。 call 関数は、任意の一連の引数を受け取り、任意のレスポンスをキャプチャできる汎用の [
「ToolOutput」を返すことができます。 ツールには、その名前、説明、関数スキーマを含む「ToolMetadata」もあります。
@dataclass
class ToolMetadata:
description: str
name: Optional[str] = None
fn_schema: Optional[Type[BaseModel]] = DefaultToolFnSchema
class BaseTool:
@property
@abstractmethod
def metadata(self) -> ToolMetadata:
pass
@abstractmethod
def __call__(self, input: Any) -> ToolOutput:
pass4-2. FunctionTool
「FunctionTool」は、任意の関数をツールとして利用するためのラッパーです。
「FunctionTool」の使用例は、次のとおりです。
from llama_index.tools.function_tool import FunctionTool
def multiply(a: int, b: int) -> int:
"""2つの整数を乗算し、結果の整数を返す"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)4-3. QueryEngineTool
「QueryEngineTool」は、クエリエンジンをツールとして利用するためのラッパーです。
「QueryEngineTool」の使用例は、次のとおりです。
from llama_index.tools import QueryEngineTool
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name='<tool_name>',
description="Queries over X data source."
)
),
...
]4-4. ToolSpec
「ToolSpec」は、エージェントが対話できる完全なAPI仕様を表すPythonクラスです。「ToolSpec」は、エージェントの初期化で指定するツールのリストに変換できます。このクラスを使用すると、単一のツールだけでなく、サービス全体を定義できます。
「ToolSpec」には、読み取り / 書き込みエンドポイントが含まれる場合があります。 たとえば、「SlackToolSpec」では、既存のメッセージとチャネルを読み込むこと (load_data、fetch_channels) 、メッセージを書き込むこと (send_message) の両方を許可できます。
class SlackToolSpec(BaseToolSpec):
"""Slack tool spec."""
spec_functions = ["load_data", "send_message", "fetch_channels"]
def load_data(
self,
channel_ids: List[str],
reverse_chronological: bool = True,
) -> List[Document]:
"""入力ディレクトリからデータをロード"""
...
def send_message(
self,
channel_id: str,
message: str,
) -> None:
"""指定したチャネルIDにメッセージを送信"""
...
def fetch_channels(
self,
) -> List[str]:
"""チャネルのリストの取得"""
...「ToolSpec」は to_tool_list を使用してエージェントに入力できるツールのリストに変換できます。
tool_spec = SlackToolSpec()
# OpenAIエージェントの初期化
agent = OpenAIAgent.from_tools(tool_spec.to_tool_list(), llm=llm, verbose=True)5. LlamaHub ツールリポジトリ
「LlamaHub ツールリポジトリ」は、エージェントが使用できる 15以上の「ToolSpec」で構成されています。 これらの「ToolSpec」は、エージェントが対話し、さまざまなアクションを実行できる厳選されたリストを表します。
・Gmail Spec
・Zapier Spec
・Google Calendar Spec
・OpenAPI Spec
・SQL + Vector Database Spec
6. データエージェントの使用例
メールを自動的に作成 / 送信できる Gmailエージェントの使用例を紹介します。
(1) GmailToolSpecのツールリストでOpenAIAgentを初期化。
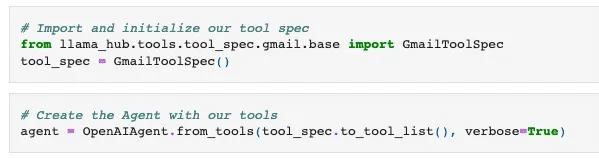
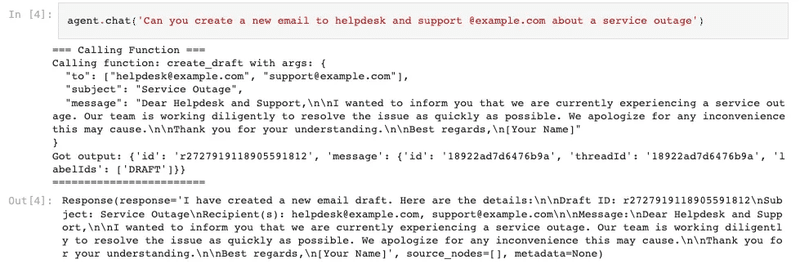
(2) エージェントに一連のコマンドを与えて、メールの下書きを作成。
エージェントは、「to」「subject」「message」パラメータを受け取る create_draft ツールを選択します。エージェントはツールを選択すると同時にパラメータを推測できます。
(3) 下書きに少し変更を加えて更新。

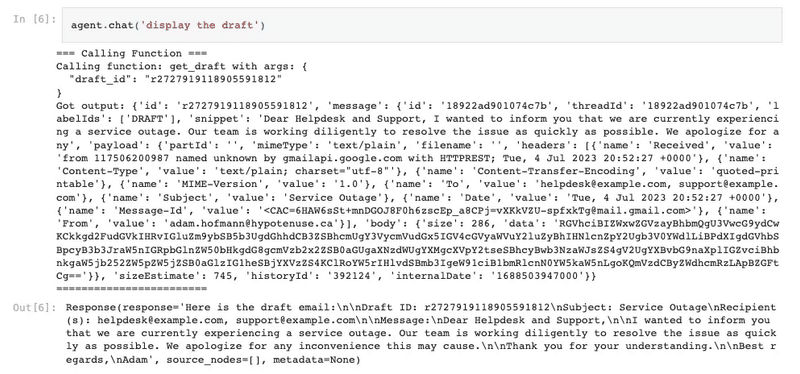
(4) 下書きの状態の確認。
(5) メール送信。

7. ユーティリティツール
APIを直接クエリすると大量のデータが返される可能性があり、それ自体でLLMのコンテキストウィンドウがオーバーフローする可能性があります。
これに対処するため、LlamaIndexリポジトリに「ユーティリティツール」の初期セットを提供しました。ユーティリティツールは概念的には特定のサービス (Gmail、Notion など) に結び付けられているのではなく、既存のツールの機能を拡張できます。この特定のケースでは、ユーティリティツールは、APIリクエストから返されたデータをキャッシュ/インデックス付けし、クエリする必要がある一般的なパターンを抽象化するのに役立ちます。
主要なユーティリティツールは、次の2つです。
7-1. OnDemandLoaderTool
「OnDemandLoaderTool」は、既存のLlamaIndexデータローダー (BaseReader) をエージェントが使用できるツールに変えます。このツールは、データローダーからload_dataをトリガーするために必要なすべてのパラメータと自然言語クエリ文字列を使用して呼び出すことができます。 実行中は、まずデータローダーからデータをロードし、インデックスを作成し、次に「オンデマンド」でクエリを実行します。 これら3つのステップはすべて、1回のツール呼び出しで実行されます。

多くの場合、APIデータを自分でロードしてインデックスを作成する方法を考えるよりも、この方が望ましい場合があります。これによりデータの再利用が可能になりますが、多くの場合、ユーザーはAPI 呼び出しのプロンプトウィンドウの制限を抽象化するためのアドホックインデックスを必要とするだけです。
使用例は、次のとおりです。
from llama_hub.wikipedia.base import WikipediaReader
from llama_index.tools.on_demand_loader_tool import OnDemandLoaderTool
tool = OnDemandLoaderTool.from_defaults(
reader,
name="Wikipedia Tool",
description="A tool for loading data and querying articles from Wikipedia"
)7-2. LoadAndSearchToolSpec
「LoadAndSearchToolSpec」は、既存のツールを入力として受け取ります。ToolSpecとして、 to_tool_list が実装されており、その関数が呼び出されると、「load」ツールと「search」ツールの2つが返されます。
「load」 ツールを実行すると、基礎となるツールが呼び出され、出力にインデックスが付けられます。「search」ツールの実行では、クエリ文字列を入力として受け取り、基礎となるインデックスを呼び出します。

これは、デフォルトで大量のデータを返すAPI エンドポイントに役立ちます。たとえば、WikipediaToolSpec はデフォルトで Wikipedia ページ全体を返しますが、ほとんどのLLMコンテキストウィンドウが簡単にオーバーフローしてしまいます。
使用例を以下に示します。
from llama_hub.tools.wikipedia.base import WikipediaToolSpec
from llama_index.tools.tool_spec.load_and_search.base import LoadAndSearchToolSpec
wiki_spec = WikipediaToolSpec()
# Wikipedia検索ツールを取得
tool = wiki_spec.to_tool_list()[1]
# load/searchツールを使用してエージェントを作成
agent = OpenAIAgent.from_tools(
LoadAndSearchToolSpec.from_defaults(
tool
).to_tool_list(), verbose=True
)実行例は、次のとおりです。
agent.chat('what is the capital of poland')=== Calling Function ===
Calling function: search_data with args: {
"query": "capital of Poland"
}
Got output: Content loaded! You can now search the information using read_search_data
========================
=== Calling Function ===
Calling function: read_search_data with args: {
"query": "What is the capital of Poland?"
}
Got output:
The capital of Poland is Warsaw.
========================
AgentChatResponse(response='The capital of Poland is Warsaw.', sources=[])エージェントは、最初に「load」ツールを呼び出す必要があることを理解していることに注意してください。この「load」ツールは、Wikipedia ページとインデックスを内部的にロードします。出力には、「コンテンツがロードされた」ことが記載されており、次のステップは「read_search_data」を使用することであることがエージェントに伝えられます。 次に、エージェントは、正しい答えを得るためにインデックスをクエリする「read_search_data」ツールを呼び出す必要があると判断します。
8. FAQ
Q. 「検索」と「取得」にはデータエージェントを使用する必要がありますか? それともクエリエンジンを引き続き使用する必要がありますか?
A. どちらも可能です。クエリエンジンを使用すると、制約付きの推論方法と制約のない方法の両方で、データに対して独自のワークフローを定義できます。たとえば、NLStructStoreQueryEngine (制約付き) を使用してテキストから SQL への特定のワークフローを定義したり、セマンティック検索と要約 (制約が少ない) のどちらかを決定するルーターモジュールを定義したり、SubQuestionQueryEngine を使用してサブグループ間で質問を分解したりすることができます。
デフォルトでは、エージェントには制約がなく、理論的には与えられたあらゆるツールセットを推論できます。これは、すぐに使える高度な検索 / 取得機能を利用できることを意味します。たとえば、OpenAI Cookbookでは、SQLクエリエンジンとベクターストア クエリを提供するだけでテキストからSQLへの結合機能を利用できることが示されています。しかしその一方で、この方法で構築されたエージェントは非常に信頼性が低い場合があります。
Q. LlamaIndex データエージェントは既存のエージェントフレームワーク (LangChain、HuggingFace など) とどう違うのですか?
A. これらの中核となる概念のほとんどは新しいものではありません。しかし、「LlamaIndex」の「データ エージェント」の設計では、次の重要な質問にうまく答えるために最善を尽くしています。
・事前にデータのインデックス付けやクエリ、取得を効果的に行うにはどうすればよいか?
・効果的にインデックス / クエリを実行し、オンザフライでデータを取得するにはどうすればよいか?
・豊富な機能 (構造化された入力を取り込むことができる) でありながら、エージェントにとって理解しやすい読み取り / 書き込み のAPIインターフェイスをどのように設計すればよいか?
・引用文の出典を適切に取得するにはどうすればよいか?
「データ エージェント」の目標は、データを推論し、データと対話できる自動化されたナレッジワーカーを作成することです。「LlamaIndex」のコアツールキットは、データのインデックス「作成」「取得」「クエリ」を適切に実行するための基盤を提供します。これらはツールとして簡単に統合できます。 API 出力をオンザフライで「キャッシュ」したい場合に対処するために、追加のツール抽象化がいくつか提供されています 。 最後に、エージェントが構造化された方法で外部サービスとインターフェースできるように、原則に基づいたツールの抽象化と設計原則を提供します。
Q. LangChain エージェントでツールを使用できますか?
A. LangChain エージェントでも「LlamaIndex」のツールを簡単に使用できます。
tools = tool_spec.to_tool_list()
langchain_tools = [t.to_langchain_tool() for t in tools]この記事が気に入ったらサポートをしてみませんか?