Google Colab + trlx で OpenCALM のRLHFファインチューニングを練習する

「Google Colab」で「OpenCALM」のRLHFファインチューニングを練習したので、記録を残します。
・trlx v0.6.0
【注意】「Google Colab Pro/Pro+」で使えるA100が必要です。
1. trlx
「trlx」は、RLHFによる言語モデルの分散学習のリポジトリです。rinnaの強化学習も「trlx」で学習しています。
2. 学習内容
「ベースモデル」は、「cyberagent/open-calm-large」を使います。
「報酬モデル」は、感情分析モデル「lxyuan/distilbert-base-multilingual-cased-sentiments-student」を使います。
強化学習の対象となるテキストを生成するプロンプトに「kunishou/hh-rlhf-49k-ja」のinstructionの最初の10文字を使います。
学習の流れは、次のとおりです。
(1) 「hh-rlhf-49k-ja」のinstructionの先頭10文字をプロンプトとして、「open-calm-large」でテキスト生成。
(2) そのテキストに対して「distilbert-base-multilingual-cased-sentiments-student」で評価。
(3) その評価を高くしようと強化学習でファインチューニング。
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install git+https://github.com/CarperAI/trlx(2) メニュー「ランタイム→ランタイムを再起動」で再起動。
(3) パッケージのインポート。
# パッケージのインポート
import yaml
from datasets import load_dataset
from transformers import pipeline
import pathlib
from typing import Dict, List
import trlx
from trlx.data.configs import TRLConfig
import json
import os
import sys
from typing import List
import torch
from transformers import pipeline
import trlx
from trlx.data.default_configs import (
ModelConfig,
OptimizerConfig,
PPOConfig,
SchedulerConfig,
TokenizerConfig,
TrainConfig,
TRLConfig,
)(4) 報酬の取得関数の準備。
「lxyuan/distilbert-base-multilingual-cased-sentiments-student」の"positive"のスコアを返してます。強化学習の報酬として利用します。
# 報酬の取得関数
def get_positive_score(scores):
"Extract value associated with a positive sentiment from pipeline's output"
return dict(map(lambda x: tuple(x.values()), scores))["positive"](5) モデルのパラメータの準備。
旧版0.5.0の「ppo_config.yaml」(0.6.0版はどこ?)をベースにしてます。以下の3つの値を変更しました。batch_sizeはメモリ削減のため減らしてます。
・train/batch_size : 16
・model/model_path : cyberagent/open-calm-large
・tokenizer/tokenizer_path : cyberagent/open-calm-large
# モデルのパラメータの準備
def llama_config():
return TRLConfig(
train=TrainConfig(
seq_length=1024,
epochs=100,
total_steps=10000,
batch_size=16,
checkpoint_interval=10000,
eval_interval=100,
pipeline="PromptPipeline",
trainer="AcceleratePPOTrainer",
save_best=False,
),
model=ModelConfig(
model_path='cyberagent/open-calm-large',
num_layers_unfrozen=2,
),
tokenizer=TokenizerConfig(
tokenizer_path='cyberagent/open-calm-large',
truncation_side="right"
),
optimizer=OptimizerConfig(
name="adamw",
kwargs=dict(
lr=1.0e-4,
betas=(0.9, 0.95),
eps=1.0e-8,
weight_decay=1.0e-6
)
),
scheduler=SchedulerConfig(
name="cosine_annealing",
kwargs=dict(T_max=10000, eta_min=1.0e-4)
),
method=PPOConfig(
name="PPOConfig",
num_rollouts=128,
chunk_size=128,
ppo_epochs=4,
init_kl_coef=0.05,
target=6,
horizon=10000,
gamma=1,
lam=0.95,
cliprange=0.2,
cliprange_value=0.2,
vf_coef=1,
scale_reward=False,
ref_mean=None,
ref_std=None,
cliprange_reward=10,
gen_kwargs=dict(
max_new_tokens=40,
top_k=0,
top_p=1.0,
do_sample=True,
),
),
)(6) main関数の準備。
def main(hparams={}):
# TRLのパラメータの準備
config = TRLConfig.update(llama_config().to_dict(), hparams)
# デバイスの準備
if torch.cuda.is_available():
device = int(os.environ.get("LOCAL_RANK", 0))
else:
device = -1
# 感情分析パイプラインの準備
sentiment_fn = pipeline(
"sentiment-analysis",
"lxyuan/distilbert-base-multilingual-cased-sentiments-student",
top_k=3,
truncation=True,
batch_size=16,
device=device,
return_all_scores=True,
)
# 報酬の取得
def reward_fn(samples: List[str], **kwargs) -> List[float]:
sentiments = list(map(get_positive_score, sentiment_fn(samples)))
return sentiments
# 強化学習で使うプロンプトの準備 (文頭10文字)
ds = load_dataset("kunishou/hh-rlhf-49k-ja", split="train")
ds = ds.filter(lambda example: example["ng_translation"]=="0.0", batched=False)
texts = [d["instruction"][:10] for d in ds]
# 学習の開始
trlx.train(
reward_fn=reward_fn,
prompts=texts[64:],
eval_prompts=texts[:64],
config=config,
)(7) main関数の実行。
main({})(8) 実行開始時に、「wandb」(Weights & Biases)の「APIキー」を求められるので入力。
「wandb」のAPIキーは「wandb」のサイトで入手できます。学習結果が「wandb」で見れるようになります。
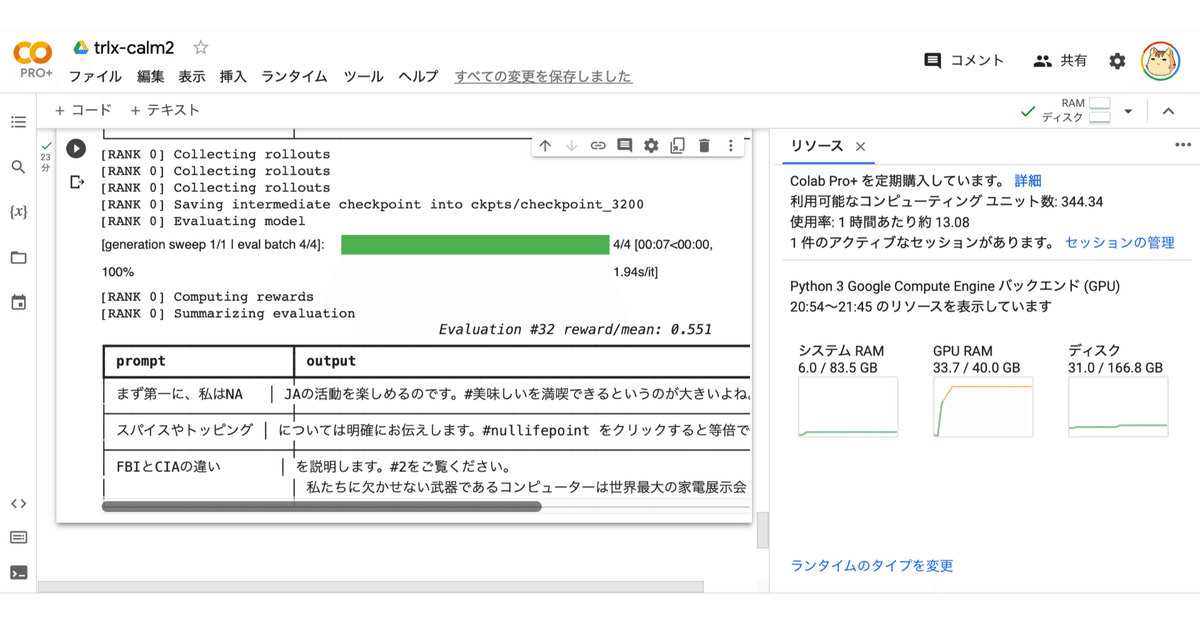
学習中は、定期的に評価が行われ、平均報酬と3つの出力例が表示されます。

学習完了まで24分ほどかかりました。
(9) 学習完了したら、「wandb」で平均報酬を確認。
3Kステップで怪しいが平均報酬は右肩上がりの模様です。

【おまけ】 失敗例
平均報酬が安定して上がって喜んでたら、「!」をたくさんつけると報酬もらえる裏技を発見してたということがありました。


関連
この記事が気に入ったらサポートをしてみませんか?