深層学習の二重降下

以下の記事を参考に書いてます。
1. 要約
「二重降下現象」は、「CNN」「ResNet」「Transformer」で発生します。パフォーマンスが最初に向上し、次に悪化し、次に「モデルサイズ」「データサイズ」「訓練時間」を増加すると再び向上します。この影響は、「正則化」により回避できることがよくあります。この振る舞いはかなり普遍的であるように見えますが、なぜそれが起こるのかはまだ完全には理解されていません。
2. はじめに
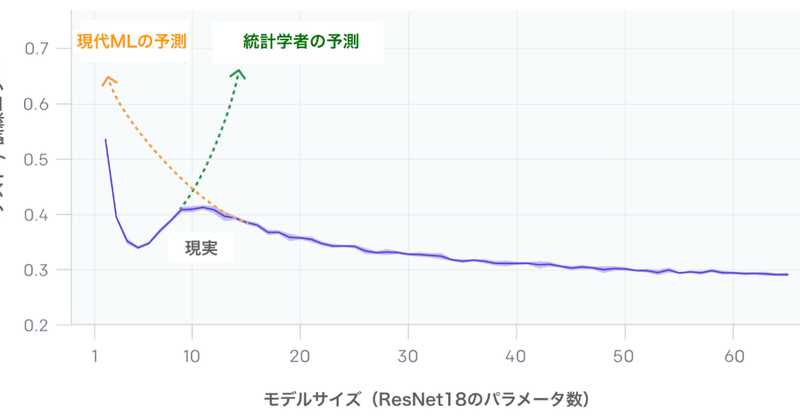
「CNN」「ResNet」「Transformer」などの最新の深層学習モデルは、「Early Stopping」または「正則化」を使用しない場合、「二重降下現象」が発生します。モデルが訓練セットに適合できない「臨界状態」で発生します。ニューラルネットワークの「モデルサイズ」を増やすと、テストエラーは最初に減少、増加し、モデルが訓練セットに適合するように2番目の降下が発生します。
これは、「モデルが大きすぎると悪い」という従来の統計学者の常識とも、「モデルが大きいほど良い」という現代のMLパラダイムとも異なります。「訓練時間」でも「二重降下」が発生することがわかります。
驚くべきことに、これらの現象はデータ破損につながる可能性があり、より大きな訓練セットで深層ネットワークを訓練すると、実際にパフォーマンスが低下することがわかります。
3. モデルが大きい方が悪い場合がある
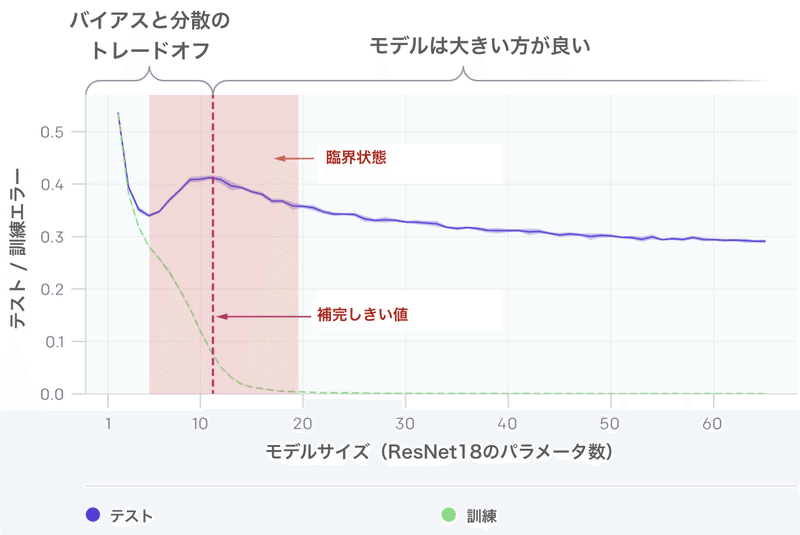
モデルごとの二重降下現象は、より多くのデータ破壊につながる可能性があります。上のグラフでは、モデルが訓練セットに適合するより若干大きい時、「補間しきい値」付近で、テストエラーのピークが発生します。
あらゆるケースで、「補間しきい値」に影響する変更(最適化アルゴリズム、訓練サンプルの数、ラベルノイズの量の変更など)も、テストエラーピークの位置に影響します。「二重降下現象」は、ラベルノイズを追加した場合に最も顕著です。これがないと、ピークは小さくなり、見逃しやすくなります。ラベルノイズを追加すると、この現象が増幅され、簡単に調査できます。
4. サンプル数が多いほうが悪い場合がある
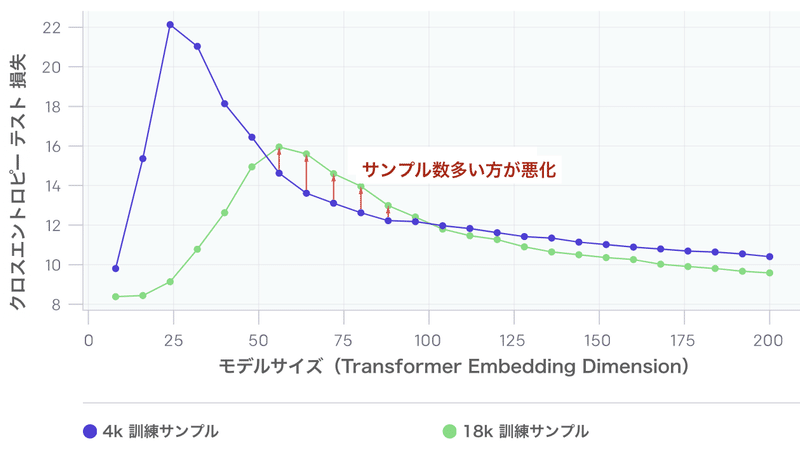
上のグラフは、ラベルノイズが追加されていない言語翻訳タスクで訓練された「Transformer」を示しています。予想通り、サンプル数を増やすと、曲線はテストエラーが低くなる方向にシフトします。ただし、より多くのサンプルが適合するためにより大きなモデルを必要とするため、サンプル数を増やすと、「補間しきい値」(およびテストエラーのピーク)も右にシフトします。中間モデルサイズ(赤い矢印)の場合、これら2つの効果が組み合わされ、4.5倍以上のサンプルで訓練すると実際にテストパフォーマンスが低下することがわかります。
5. 訓練が長すぎるとオーバーフィッティングが逆転する場合がある
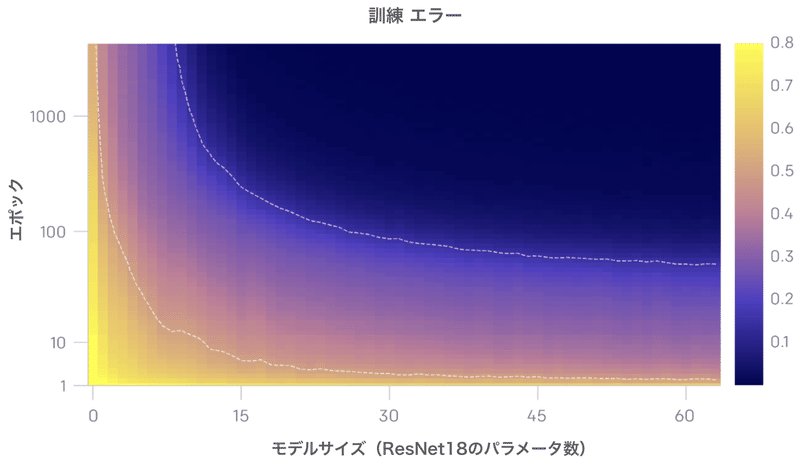
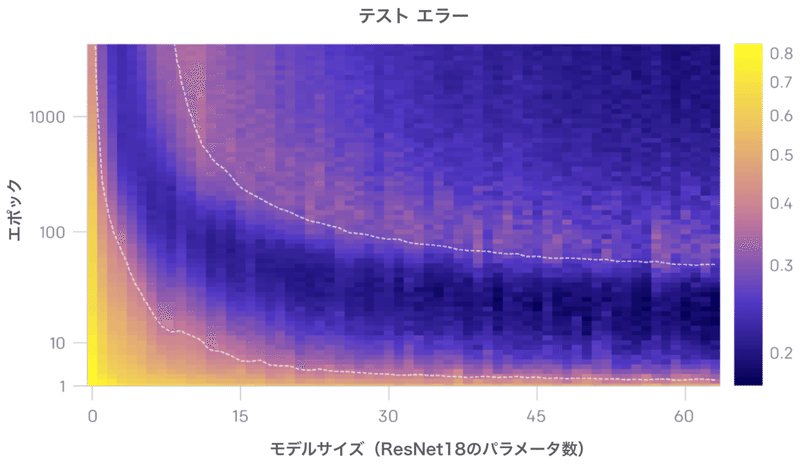
上のグラフは、「モデルサイズ」と「訓練時間」の関数として、テストと訓練のエラーを示しています。特定の「訓練時間」(固定Y座標)で、テストと訓練のエラーは「モデルサイズ」の二重降下を示します。特定の「モデルサイズ」(固定X座標)でテストと訓練のエラーは「訓練時間」の二重降下を示します。この現象を「epoch-wise二重降下」と呼びます。
一般に、モデルが訓練セットにほとんど適合しない場合、テストエラーのピークは体系的に表示されます。
私たちの直感では、「補間しきい値」のモデルには、訓練データに適合するモデルが事実上1つしかないため、ノイズが多い、または誤ったラベルに適合するように強制すると、そのグローバル構造が破壊されます。つまり、訓練セットを補間し、テストセットで良好に機能する「良いモデル」はありません。ただし、パラメータが過剰な場合、訓練セットに適合する多くのモデルがあります。さらに、「確率的勾配降下法」(SGD)の暗黙のバイアスは、まだ理解されていない理由により、優れたモデルを導きます。
ディープニューラルネットワークの「二重降下」の背後にあるメカニズムを完全に理解することは、重要な未解決の問題です。
この記事が気に入ったらサポートをしてみませんか?