Stable Diffusion Concepts Library を試す

「Stable Diffusion Concepts Library」を試したので、使い方をまとめました。
・Stable Diffusion v1.4
・Diffusers v0.3.0
1. Stable Diffusion Concepts Library
「Stable Diffusion Concepts Library」は、「Textual Inversion」のファインチューニングでオブジェクト (object) や画風 (style) を追加学習させた「Stable Diffusion」モデルのコレクションです。すでに100以上の学習済みモデルが登録されています。
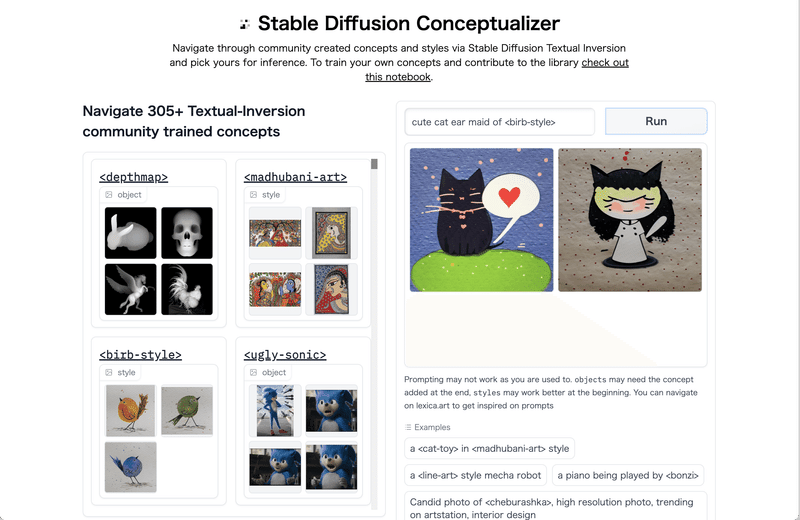
2. Stable Diffusion Conceptualizer
「Stable Diffusion Conceptualizer」のWebページで、「Stable Diffusion Concepts Library」の学習済みモデルを試すことができます。
左側のリストで追加学習した新単語(<birb-style>など)を探し、右上のテキストボックスにプロンプトを入力して「Run」ボタンを押します。
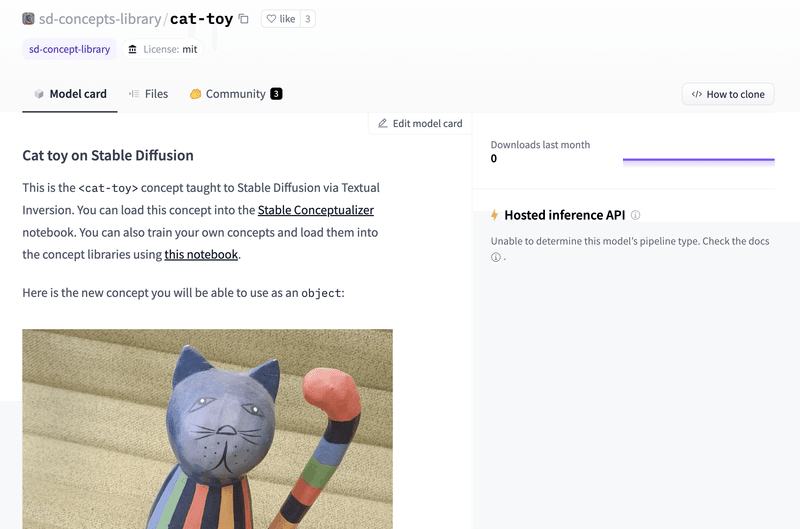
3. 学習済みモデルを探す
「Stable Diffusion Concepts Library」のサイトで、使用したい学習済みモデルを探します。今回は、公式サンプルの「sd-concepts-library/cat-toy」に決めました。学習した新単語 (プレースホルダトークン) は<cat-toy>です。
Filesタブで中身を確認できます。
・learned_embeds.bin : 学習済みモデル (特徴ベクトル)
・token_identifier.txt : プレースホルダトークン
・type_of_concept.txt : object or style
4. 学習済みモデルの実行
学習済みモデルを実行する手順は次のとおりです。
(1) 新規のColabノートブックを開き、「GPU」を選択 (ハイメモリでなくてOK)。
GPUのメモリが16GB以上 (以下は16280MiB) であることを確認します。
# GPUの確認
!nvidia-smi+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 33C P0 27W / 250W | 0MiB / 16280MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+(2) Googleドライブのマウントと作業フォルダへの移動。
あらかじめGoogleドライブのマイドライブ直下に「work」フォルダを作成しておきます。
# Googleドライブのマウントと作業フォルダへの移動
from google.colab import drive
drive.mount('/content/drive')
%cd '/content/drive/My Drive/work'(3) パッケージのインストール。
# パッケージのインストール
!pip install diffusers[training] accelerate transformers(4) HuggingFaceにログイン。
リンク先でトークンをコピーして、テキストフィールドに入力し、Loginボタンを押します。
# HuggingFaceにログイン
from huggingface_hub import notebook_login
notebook_login()(5) 学習済みモデルのダウンロード。
出力フォルダに「learned_embeds.bin」と「token_identifier.txt」がダウンロードされます。
from huggingface_hub import hf_hub_download
import os
# パラメータ
pretrained_model_name_or_path = "CompVis/stable-diffusion-v1-4" # 事前学習モデル
repo_id_embeds = "sd-concepts-library/cat-toy" # リポジトリID
downloaded_embedding_folder = "./downloaded_embedding" # 出力フォルダ
# 学習済みモデルのダウンロード
if not os.path.exists(downloaded_embedding_folder):
os.mkdir(downloaded_embedding_folder)
embeds_path = hf_hub_download(repo_id=repo_id_embeds, filename="learned_embeds.bin", use_auth_token=True)
token_path = hf_hub_download(repo_id=repo_id_embeds, filename="token_identifier.txt", use_auth_token=True)
!cp $embeds_path $downloaded_embedding_folder
!cp $token_path $downloaded_embedding_folderパラメータの項目は、次のとおりです。
・pretrained_model_name_or_path : 事前学習モデル (CompVis/stable-diffusion-v1-4)
・repo_id_embeds : Concepts LibraryのリポジトリID
・downloaded_embedding_folder : 出力フォルダ
(6) トークナイザーとエンコーダーを準備。
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
import torch
# トークナイザーとテキストエンコーダーの準備
tokenizer = CLIPTokenizer.from_pretrained(
pretrained_model_name_or_path,
subfolder="tokenizer",
use_auth_token=True,
)
text_encoder = CLIPTextModel.from_pretrained(
pretrained_model_name_or_path, subfolder="text_encoder", use_auth_token=True
)
# 学習した特徴ベクトルをCLIPに読み込み
def load_learned_embed_in_clip(learned_embeds_path, text_encoder, tokenizer, token=None):
loaded_learned_embeds = torch.load(learned_embeds_path, map_location="cpu")
# 個別のトークンと特徴ベクトル
trained_token = list(loaded_learned_embeds.keys())[0]
embeds = loaded_learned_embeds[trained_token]
# text_encoderのdtypeにキャスト
dtype = text_encoder.get_input_embeddings().weight.dtype
embeds.to(dtype)
# トークナイザーにトークンを追加
token = token if token is not None else trained_token
num_added_tokens = tokenizer.add_tokens(token)
if num_added_tokens == 0:
raise ValueError(f"The tokenizer already contains the token {token}.")
# トークンの特徴ベクトルのサイズ変更
text_encoder.resize_token_embeddings(len(tokenizer))
# トークンのIDを取得し特徴ベクトルを割り当てる
token_id = tokenizer.convert_tokens_to_ids(token)
text_encoder.get_input_embeddings().weight.data[token_id] = embeds
load_learned_embed_in_clip(
f"{downloaded_embedding_folder}/learned_embeds.bin",
text_encoder,
tokenizer)(7) Stable Diffusionパイプラインの準備。
from diffusers import StableDiffusionPipeline
# Stable Diffusionパイプラインの準備
pipe = StableDiffusionPipeline.from_pretrained(
pretrained_model_name_or_path,
torch_dtype=torch.float16,
text_encoder=text_encoder,
tokenizer=tokenizer,
use_auth_token=True,
).to("cuda")(8) 推論の実行。
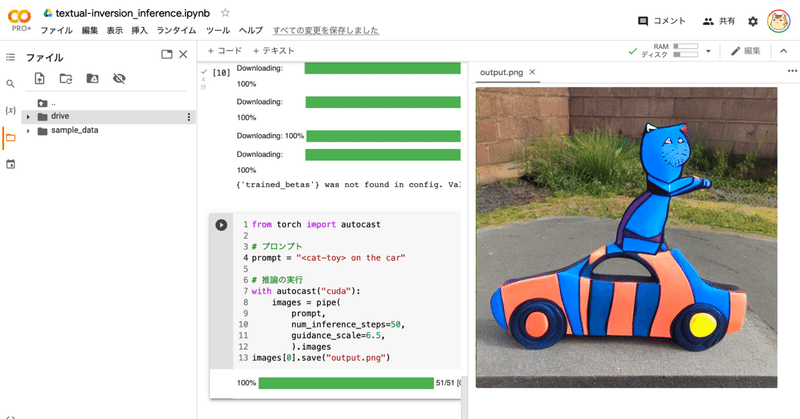
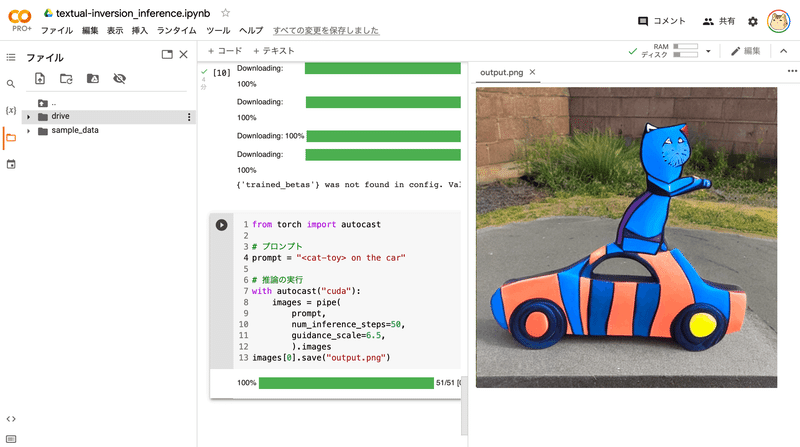
プロンプトにプレースホルダートークン(今回は<cat-toy>)を含めてください。
from torch import autocast
# プロンプト
prompt = "<cat-toy> on the car"
# 推論の実行
with autocast("cuda"):
images = pipe(
prompt,
num_inference_steps=50,
guidance_scale=7.5,
).images
images[0].save("output.png")(9) 生成した画像の確認。
左端のフォルダアイコンでファイル一覧を表示し、「output.png」をダブルクリックします。
5. 関連
この記事が気に入ったらサポートをしてみませんか?