
Google Colab で OpenCALM-7B のLoRAファインチューニングを試す

「Google Colab」で「OpenCALM-7B」のLoRAファインチューニングを試したのでまとめました。
【注意】Google Colab Pro/Pro+ の A100で動作確認しています。今回のファインチューニングには、VRAMは23.5GB必要でした。
1. OpenCALM-7B
「OpenCALM-7B」は、「サイバーエージェント」が開発した、日本語LLMです。商用利用可能なライセンスで公開されており、このモデルをベースにチューニングすることで、対話型AI等の開発が可能です。
2. 学習
「Google Colab」で「OpenCALM-7B」のLoRAファインチューニングを行います。データセットは@kun1em0nさんの「kunishou/databricks-dolly-15k-ja」を使わせてもらいました。
学習手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」で「A100」を選択。
(2) Googleドライブのマウント。
# Googleドライブのマウント
from google.colab import drive
drive.mount("/content/drive")(3) 作業フォルダへの移動。
# 作業フォルダへの移動
import os
os.makedirs("/content/drive/My Drive/work", exist_ok=True)
%cd '/content/drive/My Drive/work'(4) 基本パラメータの定義。
# 基本パラメータ
model_name = "cyberagent/open-calm-7b"
dataset = "kunishou/databricks-dolly-15k-ja"
peft_name = "lora-calm-7b"
output_dir = "lora-calm-7b-results"以下のパラメータを定義します。
・model_name : モデル名
・dataset : データセット名
・peft_name : PEFTの出力フォルダ
・output_dir : 学習結果の出力フォルダ
(5) PEFTのインストール。
# PEFTのインストール
!pip install -Uqq git+https://github.com/huggingface/peft.git
!pip install -Uqq transformers datasets accelerate bitsandbytes(6) トークナイザーの準備。
from transformers import AutoTokenizer
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name)(7) トークナイザーのスペシャルトークンの確認。
EOSは0です。
print(tokenizer.special_tokens_map)
print("bos_token :", tokenizer.eos_token, ",", tokenizer.bos_token_id)
print("eos_token :", tokenizer.bos_token, ",", tokenizer.eos_token_id)
print("unk_token :", tokenizer.unk_token, ",", tokenizer.unk_token_id)
print("pad_token :", tokenizer.pad_token, ",", tokenizer.pad_token_id){'bos_token': '<|endoftext|>', 'eos_token': '<|endoftext|>', 'unk_token': '<|endoftext|>', 'pad_token': '<|padding|>'}
bos_token : <|endoftext|> , 0
eos_token : <|endoftext|> , 0
unk_token : <|endoftext|> , 0
pad_token : <|padding|> , 1(8) トークナイズ関数の定義。
プロンプトの末尾にEOSを付加してトークナイズします。
CUTOFF_LEN = 256 # 最大長
# トークナイズ関数の定義
def tokenize(prompt, tokenizer):
result = tokenizer(
prompt+"<|endoftext|>", # EOSの付加
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
)
return {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}(9) トークナイズ関数の確認。
input_idsの最後にEOS「0」が追加されてることを確認します。
# トークナイズの動作確認
tokenize("hi there", tokenizer){'input_ids': [40254, 36767, 0], 'attention_mask': [1, 1, 1]}(10) データセットの準備。
from datasets import load_dataset
# データセットの準備
data = load_dataset(dataset)(11) データセットの確認。
# データセットの確認
data["train"][5]{'category': 'information_extraction',
'instruction': 'ステイルメイトの時に、私の方が多くの駒を持っていたら、私の勝ちですか?',
'output': 'いいえ。\nステイルメイトとは、引き分けた状態のことです。どちらがより多くの駒を捕獲したか、または優勢であるかは関係ない',
'input': 'ステイルメイトとは、チェスにおいて、手番が回ってきたプレーヤーがチェックされておらず、合法的な手がない状態のことである。ステイルメイトの結果、引き分けとなる。終盤では、ステイルメイトは劣勢にあるプレイヤーが負けるのではなく、ゲームを引き分けることを可能にする戦術である[2]。より複雑なポジションでは、ステイルメイトはより稀で、通常は優勢側が不注意な場合にのみ成功する詐欺の形をとる[引用] ステイルメイトは終盤研究や他のチェスの問題においても共通のテーマである。\n\nステイルメイトが引き分けに統一されたのは19世紀である。それ以前は、ステイルメイトしているプレイヤーの勝利、引き分け、負けとみなされたり、反則となったり、ステイルメイトしているプレイヤーはターンを失うことになったりと、その扱いは様々であった。ステイルメイトのルールは、チェス以外のチャトランガ系ゲームごとに異なる。',
'index': '5'}(12) プロンプトテンプレートの準備。
学習用のレスポンス内容あり版になります。
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:
{data_point["output"]}"""
else:
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Response:
{data_point["output"]}"""(13) プロンプトテンプレートの確認。
# プロンプトテンプレートの確認
print(generate_prompt(data["train"][5]))Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
ステイルメイトの時に、私の方が多くの駒を持っていたら、私の勝ちですか?
### Input:
ステイルメイトとは、チェスにおいて、手番が回ってきたプレーヤーがチェックされておらず、合法的な手がない状態のことである。ステイルメイトの結果、引き分けとなる。終盤では、ステイルメイトは劣勢にあるプレイヤーが負けるのではなく、ゲームを引き分けることを可能にする戦術である[2]。より複雑なポジションでは、ステイルメイトはより稀で、通常は優勢側が不注意な場合にのみ成功する詐欺の形をとる[引用] ステイルメイトは終盤研究や他のチェスの問題においても共通のテーマである。
ステイルメイトが引き分けに統一されたのは19世紀である。それ以前は、ステイルメイトしているプレイヤーの勝利、引き分け、負けとみなされたり、反則となったり、ステイルメイトしているプレイヤーはターンを失うことになったりと、その扱いは様々であった。ステイルメイトのルールは、チェス以外のチャトランガ系ゲームごとに異なる。
### Response:
いいえ。
ステイルメイトとは、引き分けた状態のことです。どちらがより多くの駒を捕獲したか、または優勢であるかは関係ない(14) 学習データと検証データの準備。
VAL_SET_SIZE = 2000
# 学習データと検証データの準備
train_val = data["train"].train_test_split(
test_size=VAL_SET_SIZE, shuffle=True, seed=42
)
train_data = train_val["train"]
val_data = train_val["test"]
train_data = train_data.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))
val_data = val_data.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))(15) モデルの準備。
「load_in_8bit=True」でint8量子化を有効にしています。
from transformers import AutoModelForCausalLM
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)GPUメモリ使用量を削減する方法は、以下が参考になります。
(16) LoRAモデルの準備。
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
# LoRAのパラメータ
lora_config = LoraConfig(
r= 8,
lora_alpha=16,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
# モデルの前処理
model = prepare_model_for_int8_training(model)
# LoRAモデルの準備
model = get_peft_model(model, lora_config)
# 学習可能パラメータの確認
model.print_trainable_parameters()trainable params: 4194304 || all params: 6876176384 || trainable%: 0.06099762085451472PEFTの関数は、次のとおり。
・LoraConfig()
LoRAのコンフィグ。
- r (int): Loraのアテンションの次元
- lora_alpha (float): LoRAスケーリングのalphaパラメータ
- target_modules (Union[List[str],str]): Lora を適用するモジュールの名前
- lora_dropout (float): LoRAレイヤーのdropout確率
- bias (str): LoRAのバイアス種別 (none, all, lora_only)
- fan_in_fan_out (bool): 置換レイヤーに (fan_in, fan_out) のようなウェイトを保存する場合True。
- modules_to_save (List[str]): 学習可能として設定され、最終チェックポイントに保存されるLoRAレイヤー以外のモジュールのリスト
・prepare_model_for_int8_training(
model, use_gradient_checkpointing=True)
モデルの前処理。
- layernormをfp32でキャスト
- 出力埋め込み層にgradsを要求
- lm_headにアップキャスティングを追加
・get_peft_model(model, peft_config)
モデルとコンフィグからPeftモデルを返す。
・print_trainable_parameters()
モデル内の学習可能なパラメーター数を出力。
(17) トレーナーの準備。
import transformers
eval_steps = 200
save_steps = 200
logging_steps = 20
# トレーナーの準備
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
num_train_epochs=3,
learning_rate=3e-4,
logging_steps=logging_steps,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
report_to="none",
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)TrainingArgumentsのパラメータは、以下が参考になります。
(18) 学習の実行。
5時間ほどかかりました。
# 学習の実行
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
# LoRAモデルの保存
trainer.model.save_pretrained(peft_name)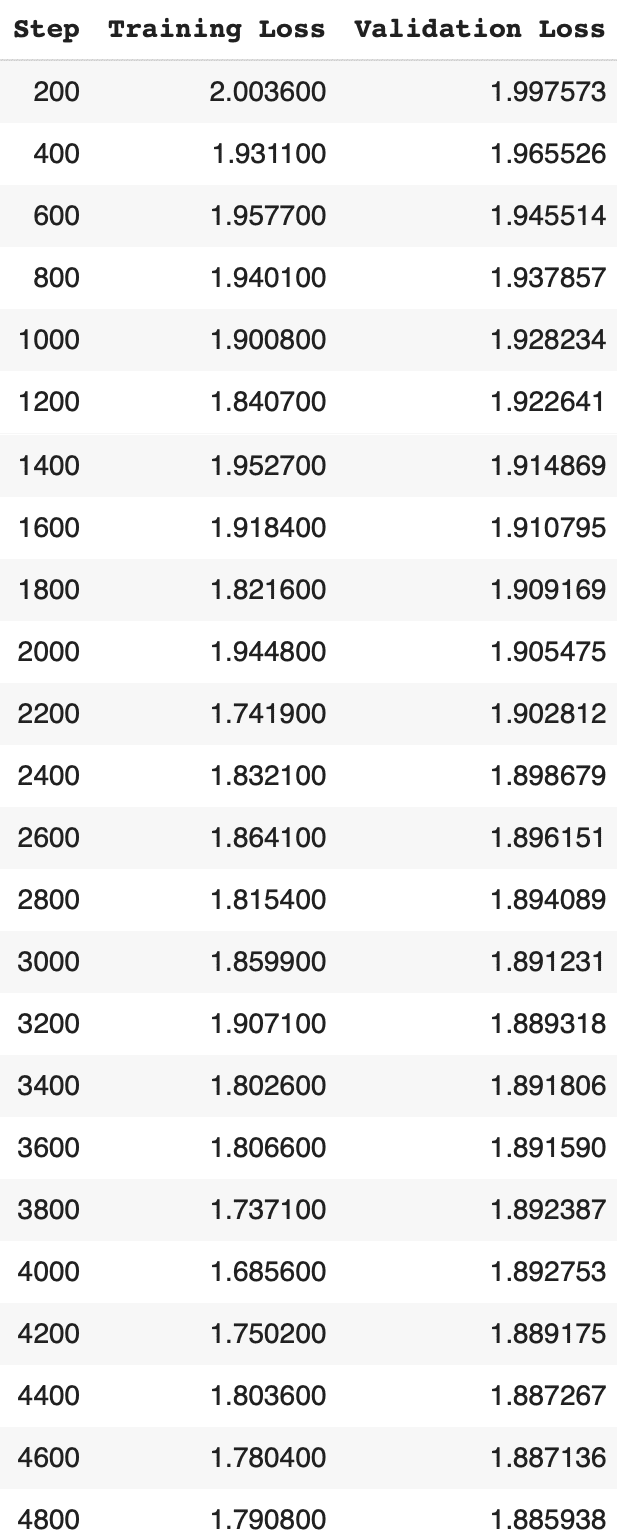
3. 推論
「Google Colab」で「OpenCALM-7B」のLoRAモデルの推論手順は、次のとおりです。
(1) モデルとトークナイザーの準備。
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)
# トークンナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name)
# LoRAモデルの準備
model = PeftModel.from_pretrained(
model,
peft_name,
device_map="auto"
)
# 評価モード
model.eval()(2) プロンプトテンプレートの準備。
推論用のレスポンス内容なし版になります。
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:"""
else:
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Response:"""(3) テキスト生成関数の定義。
# テキスト生成関数の定義
def generate(instruction,input=None,maxTokens=256):
# 推論
prompt = generate_prompt({'instruction':instruction,'input':input})
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=maxTokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
# EOSトークンにヒットしたらデコード完了
if tokenizer.eos_token_id in outputs:
eos_index = outputs.index(tokenizer.eos_token_id)
decoded = tokenizer.decode(outputs[:eos_index])
# レスポンス内容のみ抽出
sentinel = "### Response:"
sentinelLoc = decoded.find(sentinel)
if sentinelLoc >= 0:
print(decoded[sentinelLoc+len(sentinel):])
else:
print('Warning: Expected prompt template to be emitted. Ignoring output.')
else:
print('Warning: no <eos> detected ignoring output')model.generate()のパラメータは、以下が参考になります。
(4) 推論の実行。
質問に対する答えだけ返してEOSしているため、学習できてそうです。
generate("自然言語処理とは?")自然に存在する言語をコンピューターに処理させるためのアルゴリズムとツール群。自然言語は、機械が理解できるように形式化されています。generate("日本の首都は?")東京generate("まどか☆マギカで一番かわいいのは?")ほむらです。関連
この記事が気に入ったらサポートをしてみませんか?