
OpenCALM-7BをLoRAでFine tuningして対話ができるようにする

ちょっと出遅れたけど、サイバーエージェントが出したGPT-NeoXベースのLLM、OpenCALM-7BをGoogle Colab上でLoRA使ってFine tuningをしてみました。
とりあえず対話を試したい人
masuidrive/open-calm-instruct-lora-20230525-r4-alpha16-batch32-epoch1 に1 epoch回したLoRAを置いておきます。
Google Colabで試したい人はV100やA100のハイメモリで動かしてください。OpenCALM-7Bのshardが10GB単位なため、12GBの標準メモリでは動きません。transformersのloaderがもう少し賢ければ、T4の標準メモリでも動くと思うんだけど・・・
なぜFine tuningをするのか
OpenCALM-7Bは基礎モデルなので日本語やWikiPediaの内容など知識はありますが、「対話」や「翻訳」「要約」「Q&A」などのタスクは覚えていない状態です。
そのため、何かに使うためにはそのタスクを含んだデータセットでFine tuningしてタスクを覚えてもらう必要があります。
Instructionタスクの学習データを用意する
日本語で多様で品質の高いInstruction データセットということで、kunishou/databricks-dolly-15k-jaとkunishou/hh-rlhf-49k-jaを使わせていただいています。合計65kの日本語のデータセットです。
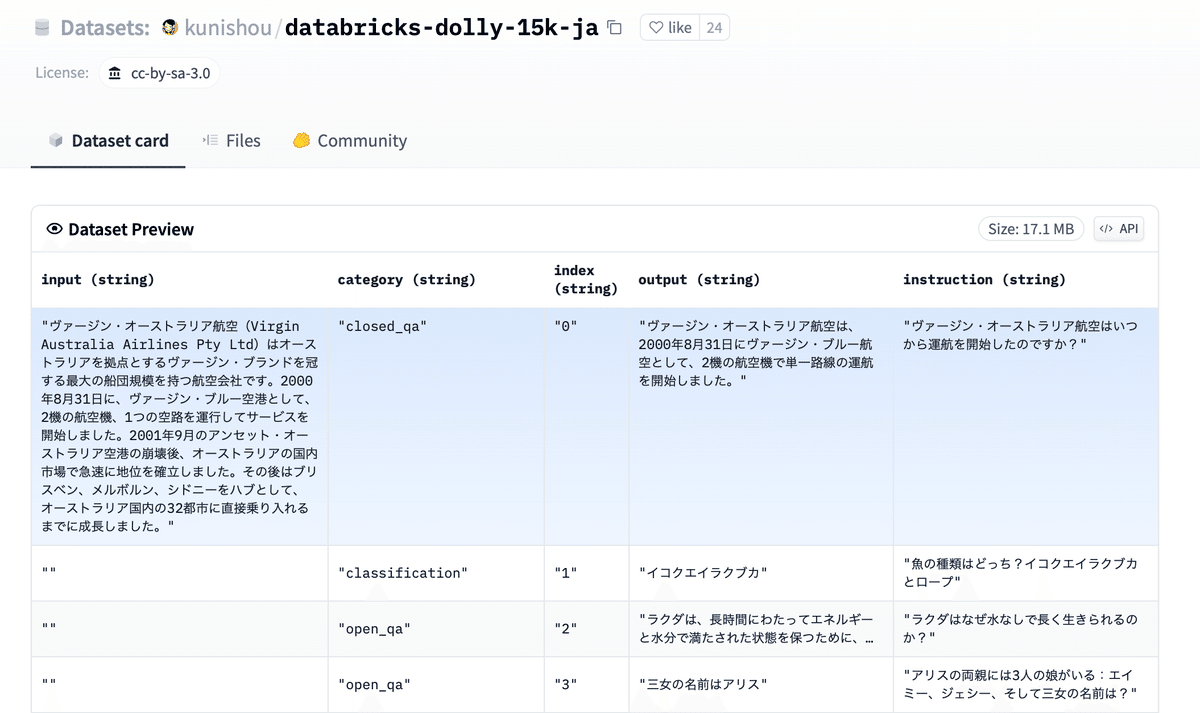

両方ともhuggingfaceに置いてあるので、datasetsライブラリで簡単に読み出せます。
これらデータを元に下記の様なフォーマットにしてこれを学習させます。これはalpacaというLLMで使われていたフォーマットです。
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction
{instruction}
### Input:
{input}
### Response:
{response}OpenCALMがどの程度英語を学習しているのか分からなかったので、指示文やラベルを日本語にして試してみたのですが結果は変わらない感じでした。そのため英語の方を採用しました。しかし1行目の指示文を取った場合は性能が落ちた感じがしたので削らないことにしました。
def generate_prompt(instruction, input=None, response=None):
def add_escape(text):
return text.replace('### Response', '### Response')
if input:
prompt = f"""
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{add_escape(instruction.strip())}
### Input:
{add_escape(input.strip())}
""".strip()
else:
prompt = f"""
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{add_escape(instruction.strip())}
""".strip()
if response:
prompt += f"\n\n### Response:\n{add_escape(response.strip())}<|endoftext|>"
else:
prompt += f"\n\n### Response:\n"
return prompt上記の関数を通してTrainerで使いやすいdataset形式に変換します。今回は二つのdatasetsを使うので、これを一つにまとめます。また両方ともtrainだけなので、testにも分割しておき、validation lossが見れるようにしておきます。
from datasets import DatasetDict, load_dataset, concatenate_datasets
"""
input/instruction/outputからpromptを作ってtokenizeする
"""
def tokenize_qa_function(sample):
context = sample.get('input', '').strip()
instruction = sample.get('instruction', '').strip()
output = sample.get('output', '').strip()
prompt = generate_prompt(instruction, context, output)
return tokenizer(prompt)
"""
nameのdatasetを読み込み、alpaca形式のプロンプトにしてtokenizeする
trainはtest_sizeでtestとsplitする
"""
def process_qa_dataset(name, test_size):
TOKENIZED_COLUMNS = ['input_ids', 'attention_mask']
data = load_dataset(name)
data = data['train'].train_test_split(test_size=test_size)
remove_columns = [item for item in data['train'].column_names if item not in TOKENIZED_COLUMNS]
data = data.map(tokenize_qa_function, remove_columns=remove_columns)
return data
# 二つのデータセットを
data = []
data.append(process_qa_dataset("kunishou/hh-rlhf-49k-ja", 0.01))
data.append(process_qa_dataset("kunishou/databricks-dolly-15k-ja", 0.03))
data = DatasetDict()
for key in ['train', 'test']:
data[key] = concatenate_datasets([data1[key], data2[key]])
print(f"{key}: {len(data[key])}")
# トークンサイズを超えるものは削除
data = data.filter(lambda x: len(x['input_ids']) < model.config.max_position_embeddings)PEFTでFine tuning
ベースモデルの読み込み
cyberagent/open-calm-7bをベースモデルとして読み込ます。メモリを節約するためにfp16を指定します。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
"cyberagent/open-calm-7b",
torch_dtype=torch.float16,
device_map='auto',
offload_folder="./offload"
)重要なパラメータだけfp32にする
Fine tuningで重要なパラメータだけ計算精度を上げるためにfp32にします。
from torch import nn
for param in model.parameters():
param.requires_grad = False
if param.ndim == 1:
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
# embed_outがないと言われる場合は、下記のモデル情報を見て最後の層の名前を指定してみてください。
model.lm_head = CastOutputToFloat(model.embed_out)PEFTでLoRAの準備をする
TransformersでLoRAモデルを作るライブラリとしてPEFTを使います。
ハイパーパラメータとして、R, α, dropoutがあり、どのモジュールに適用するかを指定するtarget_modulesがあります。これはググって適当な値を設定してください。ハイパーパラメータは評価関数を作り自動探索するのがいいので、そのうちやりたいなと思っています。
from transformers import TrainingArguments
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
bias="none",
fan_in_fan_out=False,
target_modules=["query_key_value"],
r=LORA_R,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT
)
model = get_peft_model(model, peft_config)学習を開始する
あとは普通の学習と一緒で、epoch, learning rate, batch size、データセットを渡してTrainerで学習を開始します。
import transformers
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
# 学習の設定
trainer = Trainer(
model=model,
train_dataset=datasetDict['train'],
eval_dataset=datasetDict['test'],
args=TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=BATCH_SIZE // MICRO_BATCH_SIZE,
warmup_steps=WARMUP_STEPS,
max_steps=MAX_STEPS,
learning_rate=LEARNING_RATE,
fp16=True,
num_train_epochs=EPOCHS,
save_strategy='epoch',
output_dir="result",
evaluation_strategy='steps',
eval_steps=EVAL_STEPS,
logging_dir='./logs',
logging_steps=100,
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
# 学習開始
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
# 推論モード
model.eval()
# Google Driveに保存
if SAVE_TO_GDRIVE:
!mkdir -p "{PEFT_MODEL_PATH}"
model.save_pretrained(PEFT_MODEL_PATH)BLEUで評価をしようと思ったのですがメモリがギリギリすぎてダメでした。今度DeepSpeedを使ってCPUに一部逃した後、試してみたいです。
Google ColabのA100を使って、1 epochあたり2時間ぐらいかかります。とりあえず試すならmax_stepsを300ぐらいにするとちょっと試せます。
実行する
実行は普通のモデルと一緒です。投げる時のプロンプトは前に指定したフォーマットになります。
def qa(instruction, context=None):
prompt = generate_prompt(instruction, context)
batch = tokenizer(prompt, return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(
**batch,
max_new_tokens=256,
temperature = 0.7,
repetition_penalty=1.05
)
text = tokenizer.decode(output_tokens[0],pad_token_id=tokenizer.pad_token_id,
skip_special_tokens=True)
return get_response(text)
instruction = "トヨタ自動車は何年設立ですか?"
context = "豊田自動織機製作所自動車部時代は、社名中の「豊田」の読みが「トヨダ」であったため、ロゴや刻印も英語は「TOYODA」であった。エンブレムは漢字の「豊田」を使用していた。しかし、1936年夏に行われた新トヨダマークの公募で、約27,000点の応募作品から選ばれたのは「トヨダ」ではなく「トヨタ」のマークだった。理由として、デザイン的にスマートであること、画数が8画で縁起がいいこと、個人名から離れ社会的存在へと発展することなどが挙げられている[11]。1936年9月25日に「トヨタ(TOYOTA)」の使用が開始され、翌年の自動車部門独立時も「トヨタ自動車工業株式会社」が社名に採用された。"
print("----")
print(instruction)
print(qa(instruction))
print(qa(instruction, context))上記の結果は下記のようになり、Q&Aタスクは無事に処理できるようになっています。
トヨタ自動車は何年設立ですか?
コンテキストなし: 1948年に設立され、現在は世界最大の自動車製造会社であり、世界で最も有名なブランドの一つです。
下記コンテキスト: 1938年に設立された
豊田自動織機製作所自動車部時代は、社名中の「豊田」の読みが「トヨダ」であったため、ロゴや刻印も英語は「TOYODA」であった。エンブレムは漢字の「豊田」を使用していた。しかし、1936年夏に行われた新トヨダマークの公募で、約27,000点の応募作品から選ばれたのは「トヨダ」ではなく「トヨタ」のマークだった。理由として、デザイン的にスマートであること、画数が8画で縁起がいいこと、個人名から離れ社会的存在へと発展することなどが挙げられている[11]。1936年9月25日に「トヨタ(TOYOTA)」の使用が開始され、翌年の自動車部門独立時も「トヨタ自動車工業株式会社」が社名に採用された。マイナンバーカードの受け取りは免許書を持って行けばいいですか?
コンテキストなし: 運転免許証があれば、マイナンバーカードを受け取ることができます。
下記コンテキスト: 運転免許証、パスポート、顔写真付きの本人確認書類は1点、その他の2点は2点必要です。
マイナンバーカードの受け取りに必要な書類は以下のとおりです。
交付通知書
本人確認書類(有効期間内のもの)
顔写真付きの本人確認書類は1点
その他は2点(例:健康保険証+年金手帳)
お持ちの方のみ
通知カード
住民基本台帳カード
マイナンバーカード
詳しくは必要な持ち物をご確認ください。情報セキュリティ対策に関わる責任者と担当者の役割や権限が明確になっていますか?具体的には、個人情報保護責任者、個人情報保護担当者は任命されていますか?
コンテキストなし: はい。情報セキュリティ管理の責任者として任命された人がいます。
下記コンテキスト: いいえ。
個人情報保護管理者: 任命なし
責任と権限
・JISQ15001に適合したPMSを構築、運用する
・PMSの運用状況や成果を、トップマネジメントに報告す
----
個人情報保護監査責任者
宮崎健吾
責任と権限
・内部監査計画書の作成
・内部監査員の選定
・内部監査の指揮
・内部監査報告書の作成及びトップマネジメントへの報告地球温暖化とはなんですか?
コンテキストなし: 地球温暖化は、大気中の温室効果ガスの濃度が上昇することを指します。温室効果ガスは、太陽からの熱を宇宙に逃がすのを妨げるため、地球の気温が上昇します。
下記コンテキスト: 気候変動は、地球の温度を上昇させることです。
リモートワークでリモートワークができた
毎日でも食べたいということは毎日でも食べているというわけではない
今のままではいけないと思っています。だからこそ日本は今のままではいけないと思っている
約束は守るためにありますから、約束を守るために全力を尽くしますソースコード
上記のをまとめたソースコードをgistに置いておくので、実行してみたい方はV100 ハイメモリ環境で実行してください。