
MT-Bench の概要

「MT-Bench」の概要についてまとめました。
1. MT-Bench
「MT-Bench」は、80の高品質でマルチターンの質問を含む、慎重にキュレーションされたLLMのベンチマークです。これらの質問は、LLMがマルチターンダイアログのモデルの会話の流れと指示に従う能力の評価を目的としており、「一般的なユースケース」と「挑戦的な指示」の両方が含まれています。
次の8つの主要なカテゴリを評価します。
・Writing
・Roleplay
・Extraction
・Reasoning
・Math
・Coding
・Knowledge I (STEM)
・Knowledge II (humanities/social science)
カテゴリごとに10個のマルチターン質問、合計160個の質問セットになります。

2. 採点方法
人間の嗜好はゴールドスタンダードであると信じていますが、収集が遅くて高価です。Vicunaのブログ記事では、「GPT-4」に基づく自動評価パイプラインを調査しています。このアプローチはその後人気を博し、いくつかの並行およびフォローアップ作業で採用されています。
最新の論文「Judging LLM-as-a-judge」では、これらのLLM審査員の信頼性に答えるために体系的な研究を実施しました。
LLM審査員には、次のような制限があります。
・位置バイアス : ペアワイズ比較で最初の答えを支持する傾向がある
・冗長性バイアス : 品質に関係なくより長い回答を好む傾向がある
・自己強化バイアス : 自分の反応を好む傾向がある
・限られた推論能力 : 数学と推論問題の採点を間違える傾向がある
これら制限があるにもかかわらず、「GPT-4」のような強力なLLM審査員は、人間の嗜好と80%以上の合意を達成できることを発見しました。これは、2人の異なる人間の審査員間の合意に匹敵します。したがって、慎重に使用することで、LLM審査員は、人間の嗜好のスケーラブルで説明可能な近似として機能することができると考えられます。
3. 結果と分析
3-1. チャットボットのランク付け
以下の表は、「MT-Bench」で強化されたリーダーボードです。28の一般的な指示チューニングモデルの徹底的な評価を実施してます。
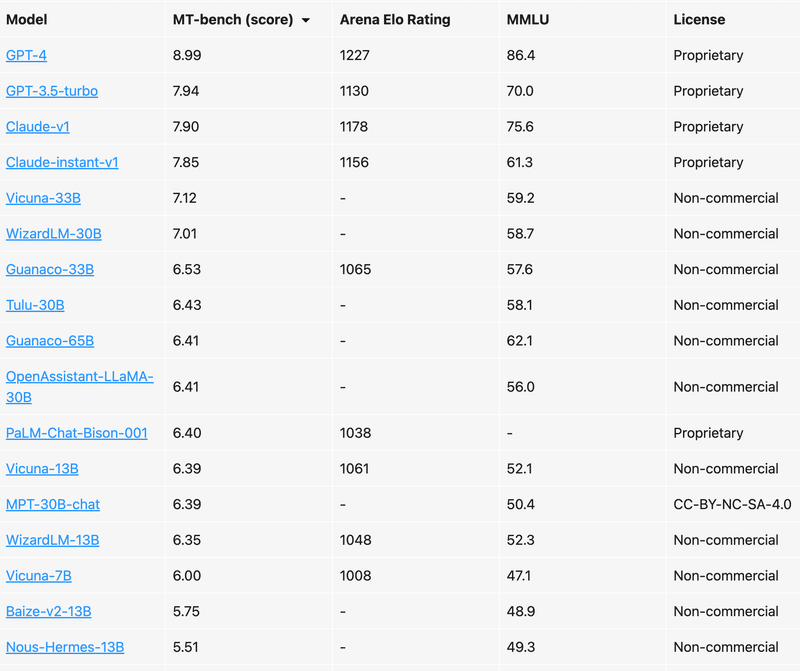
「MT-Bench」は、「GPT-4」と「GPT-3.5/Claude」の間、および「オープンモデル」と「プロプライエタリモデル」の間の顕著なパフォーマンスギャップを明らかにしています。
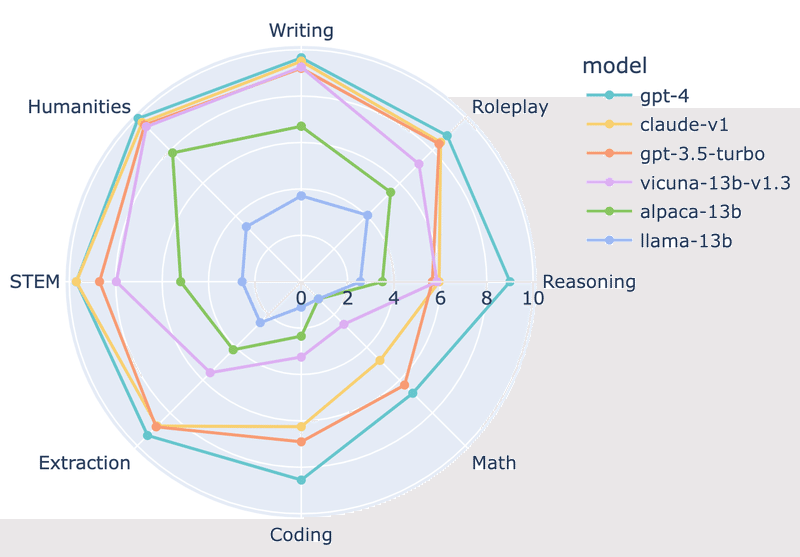
「GPT-4」は、「GPT-3.5/Claude」と比較してコーディングと推論で優れたパフォーマンスを示していますが、「Vicuna-13B」は抽出、コーディング、数学など、いくつかの特定のカテゴリで大幅に遅れています。これは、オープンソースモデルにはまだ十分な改善の余地があることを示唆しています。
3-2. マルチターン会話機能
以下の表では、選択したモデルのマルチターンスコアを分析しています。
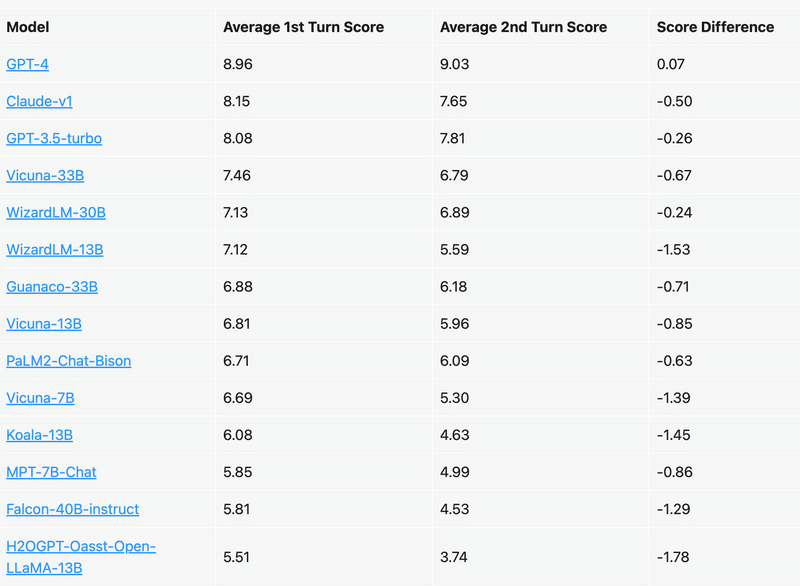
「MT-Bench」には、設計の一部として挑戦的なフォローアップの質問が組み込まれています。オープンモデル (Vicon-7B、WizardLM-13Bなど) の場合、パフォーマンスは 1st Turn から 2nd Turn に大幅に低下しますが、強力なプロプライエタリモデルは一貫性を維持します。また、LLaMAベースのモデルと許容ライセンスを持つモデル(MPT-7B、Falcon-40B、指示チューニングされたOpen-LLaMA)との間にかなりの性能ギャップがあることにも気づきます。
3-3. LLM審査員の説明可能性
LLM審査員のもう1つの利点は、説明可能な評価を提供する能力です。以下の図は、「Alpaca-13b」と「gpt-3.5-turbo」からの回答を含む、「MT-Bench」の質問に対する「GPT-4」の判断の例を示しています。
「GPT-4」は、その判断を裏付けるために、徹底的かつ論理的なフィードバックを提供します。私たちの研究では、そのようなレビューは、人間がより良い情報に基づいた決定を下すように導くのに有益であることがわかりました。すべての「GPT-4」の判断は、デモサイトで見つけることができます。
4. おわりに
結論として、「MT-Bench」はさまざまな機能のチャットボットを効果的にランク付けすることを示しました。スケーラブルで、カテゴリの内訳で貴重な洞察を提供し、人間審査員が検証するための説明可能性を提供します。ただし、LLM審査員は慎重に使用する必要があります。特に数学/推論の問題を採点するとき、それはまだ間違う可能性があります。
参考
次回
この記事が気に入ったらサポートをしてみませんか?