
Recorderのオンデバイス機械学習

以下の記事が面白かったので、ざっくり訳しました。
・The On-Device Machine Learning Behind Recorder
1. はじめに
過去20年にわたり、Googleは、テキスト情報、写真、ビデオ、地図、仕事まで、検索を通じて情報に広くアクセスできるようにしました。しかし、世界の情報の多くは音声で伝えられます。多くの人々が会話、インタビュー、講義などで重要な情報を録音で取得しますが、数時間の録音から関心のある情報を抽出するのは非常に困難な作業です。しかし、必要なときに必要な関連情報を直感的に見つけられるように、長時間の録音をリアルタイムで自動的に書き起こし、タグ付けする機能があるとしたらどうでしょうか?
そこで私たちは、「Recoder」をリリースしました。これは、Pixelフォン向けの録音アプリで、デバイス上の機械学習を活用して会話を転写します。録音の種類を検出および識別し(音楽やスピーチなどの幅広いカテゴリから、拍手、笑い声などの特定の音まで)、ユーザーが関心のある部分をすばやく見つけて抽出できるように、記録のインデックスを作成します。これらの機能はすべて、オンデバイスで実行されます。
2. 転写
「Recorder」は、デバイス上の自動音声認識モデルを使用してリアルタイムで音声を書き起こします。このモデルが長時間の音声録音(数時間)を確実に転写できるようにし、同時に音声認識モデルによって計算されたタイムスタンプに単語をマッピングして、会話のインデックスを作成できるようにしました。これにより、ユーザーは転写内の単語をクリックして、録音のそのポイントから再生を開始したり、単語を検索して発声された録音の正確なポイントにジャンプしたりできます。

3. サウンド分類によるコンテンツの視覚化の記録
録音のトランスクリプトを提示することは有用であり、特定の単語を検索できるようにする一方で、非常に長い録音お場合は、特定の瞬間や音に基づいて録音を視覚的に検索する方が便利な場合があります。
これを可能にするために、「Recorder」はさらに、各色が異なるサウンドカテゴリに関連付けられている色付きの波形として表示します。これは、CNNを使用して録音の分類(犬の吠え声や楽器の演奏を識別するなど)と、以前に公開された録音イベント検出用のデータセットを組み合わせて、個々のオーディオフレームのサウンドイベントを分類します。
もちろんほとんどの場合、多くの音が同時に表示される可能性があります。
録音を非常に明確な方法で視覚化するために、各波形バーを特定の時間枠で最も支配的なサウンドを表す単一の色(この場合は50msバー)に色付けすることにしました。色付けされた波形により、ユーザーは特定の録音されたコンテンツの種類を理解し、増え続ける録音ライブラリを簡単にナビゲートできます。これにより、録音の視覚的表現がユーザーに提供され、ユーザーは録音内のサウンドイベントを検索できます。

「Recorder」は、部分的に重複する960msオーディオフレームを50ms間隔で処理するスライディングウィンドウ機能を実装し、フレーム内でサポートされる各オーディオクラスの確率を表すS字型スコアベクトルを出力します。システムの精度を最大化し、正しい音の分類を報告するために、シグモイドスコアにしきい値処理メカニズムと組み合わせて、線形化プロセスを適用します。小さな50msオフセットで960msウィンドウのコンテンツを分析するこのプロセスにより、連続する大きな960msウィンドウスライスを単独で分析するよりも、ミスを起こしにくい方法で正確な開始時間と終了時間を特定できます。
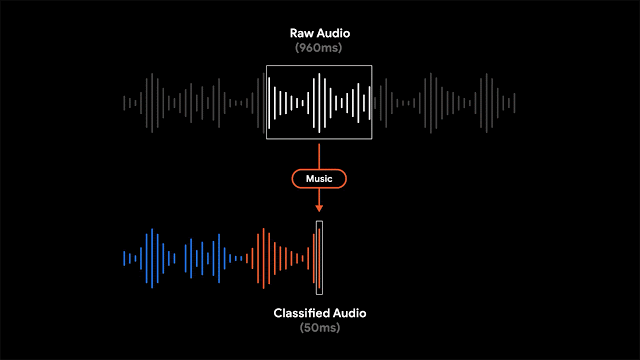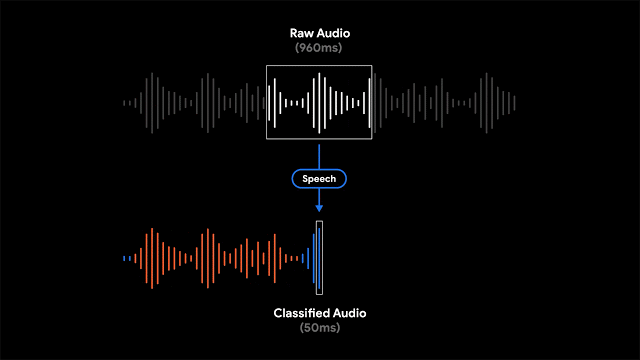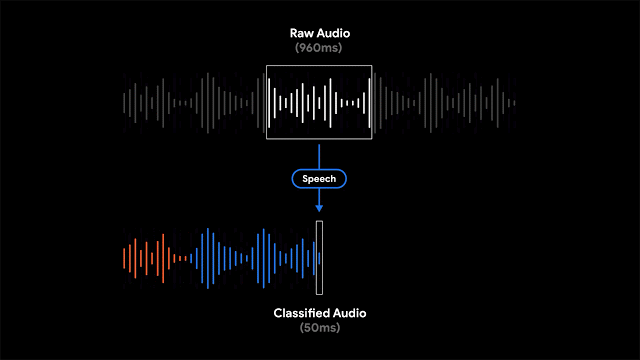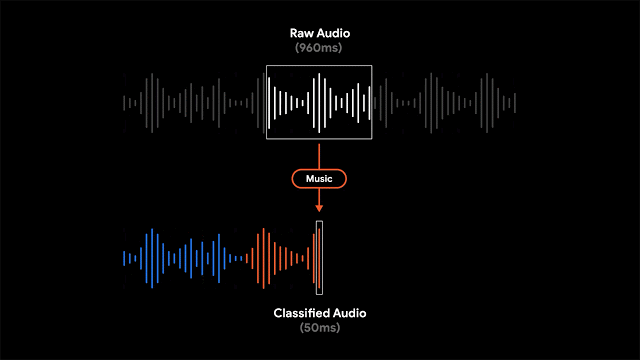
モデルは各オーディオフレームを個別に分析するため、オーディオクラス間で迅速なジッタリングが発生する可能性があります。これは、最新のモデルオーディオクラス出力に適用される適応サイズのメディアンフィルタリング技術により解決され、平滑化された連続出力を提供します。プロセスはリアルタイムで継続的に実行されるため、非常に厳しい電力消費制限を満たす必要があります。
4. タイトルのタグを提案する
「Recorder」は、録音が完了すると、アプリが最も記憶に残るコンテンツを表すと見なす3つのタグを提案し、ユーザーが意味のあるタイトルをすばやく作成できるようにします。

「Recorder」は、記録が終了したときにこれらのタグをすぐに提案できるようにするため、記録中の記録の内容を分析します。まず「Recorder」は、文中の用語の出現と文法的な役割をカウントします。 エンティティとして識別される用語は大文字で表記されます。次に、デバイス上の品詞のタガー(文法上の役割に従って文の各単語にラベルを付けるモデル)を利用して、ユーザーが覚えやすいと思われる一般的な名詞と固有名詞を検出します。「Recorder」は、ユニグラムとバイグラムの両方の用語抽出をサポートする事前スコアテーブルを利用します。スコアを生成するために、会話型データでブーストされた決定ツリーを訓練し、ドキュメントの単語の頻度や特異性などのテキスト機能を利用しました。最後に、ストップワードとスワーワードのフィルタリングが適用され、トップタグが出力されます。

5. おわりに
「Recorder」は、ユーザーのプライバシーを確保するためにモデルをオンデバイスで実行し、最新のオンデバイスML研究を取り入れました。 機械学習の調査とユーザーのニーズの間の正のフィードバックループは、ソフトウェアをさらに便利にするための刺激的な機会を明らかにしました。 すべての人のアイデアや会話をより簡単にアクセスおよび検索できるようになることを期待しています。
この記事が気に入ったらサポートをしてみませんか?