
Google Open Sources Dreamer : 画像から長期視点のタスクを学習できる強化学習エージェント

以下の記事を参考に書いてます。
1. はじめに
深層強化学習(DRL)は、過去10年間で最も重要な人工知能(AI)のブレークスルーの中心にありました。DRLは、環境との相互作用に依存しているため、非常に複雑な環境で動作するため、自動運転車など、多くの現実世界のシナリオに適用されています。そして現在は、試行錯誤をあまり必要とせずに環境の知識を汎化できるエージェントを作成するDRL研究が推進されています。
DeepMindとGoogleは最近、画像から「世界モデル」を学習し、それを使用して長期視点の「行動」を学習する強化学習エージェント「Dreamer」をオープンソース化しました。
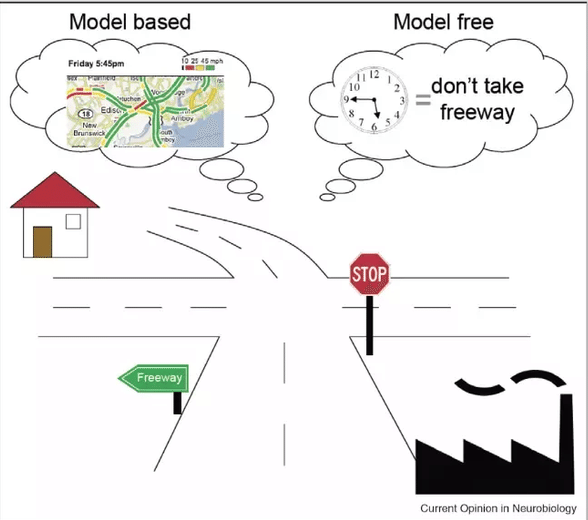
2. モデルフリーとモデルベース
DRLの世界は、大きく「モデルフリー」と「モデルベース」の2つに分けることができます。
「モデルフリー」は、「報酬」を特定の「行動」にマッピングすることにより、特定のタスクを攻略することに焦点を合わせています。AtariゲームをマスターしたDeepMindの「DQN」などが基盤となっています。「モデルフリー」では通常、感覚的な入力を行動にマッピングするために、多数の時間が必要になります。結果として長期計画戦略では制限されることがよくあります。
「モデルベース」は、最もよく知られている「モデルフリー」の代替手段です。Open AIの「Dota2エージェント」やDeepMindの「Quake IIIエージェント」「AlphaGo」「AlphaStar」など、強化学習の大きなブレークスルーの背後にある基盤となっています。「モデルベース」は、「モデルフリー」とは対照的に、エージェントに世界を学習させ、長期的な結果に基づいて行動を選択しようとします。このタイプの知識生成は「世界モデル」と呼ばれ、「モデルベース」のDRLの基本的な要素になります。当然のことながら、「モデルベース」は、長期計画でより効率的であることが証明されています。
「モデルベース」のDRLを主流に採用するための主な課題の1つは、長期的なタスクを汎化する能力でした。実際のシナリオでは、DRLエージェントは定期的に複雑な環境と対話し、これまでに見たことのない状況に直面します。この新しい状況への汎化を可能にするため、過去の経験から世界の表現を構築する能力が必要になります。この分野ではいくつかの顕著な進歩がありましたが、「モデルベース」のDRLでの長期計画の課題は、計算の観点からは非常に高価なままです。
3. Dreamer
Googleの「Dreamer」は、特定の環境で長期視点の「行動」を学習できるDRLエージェントです。「Dreamer」の主な革新の1つは、エージェントが画像から「世界モデル」を学習し、それを使って長期視点の「行動」を学習できることです。「Dreamer」は「世界モデル」を活用して、モデル予測による逆伝播を介して「行動」を効率的に学習します。
詳細を詳しく見てみましょう。
アーキテクチャの観点から見ると、「Dreamer」は他の「モデルベース」のDRLと変わりません。機能的には、「Dreamer」アーキテクチャは3つの基本的なステップに基づいています。
1つ目のステップでは、モデルは過去の経験を学習することで「世界モデル」を推測し、「観測」と「行動」をコンパクトな潜在状態にエンコードすることを学習します。
2番目のステップでは、「学習価値」と「アクターネットワーク」に焦点を当てます。このステップでは、「Dreamer」は、勾配を想像された軌道に伝播して、将来の値の予測を最大化する状態と行動を予測します。
3番目のステップで、環境との相互作用が可能になります。このステップでは、エージェントはエピソードの履歴をエンコードして、現在のモデルの状態を計算し、環境で実行する次の行動を予測します。

これらの手順を詳しく見てみましょう。
4. ステップ1 : 世界モデルの学習
正確な「世界モデル」を構築するために、「Dreamer」はGoogleとDeepMindの別の革新的なプロジェクトを活用しています。Googleの「Deep Planning Network」(PlaNet)は、学習した潜在空間での効率的な計画により画像から制御タスクを解決する、純粋な「モデルベース」の強化学習アルゴリズムです。
「PlaNet」は画像を使用する環境について学習し、その知識を画像制御タスクのログターム計画に使用します。画像を使用して長期タスクを効率的に計画するために、「PlaNet」は、オブジェクトの速度や位置などの表現を記述する画像内の「潜在状態」のコンパクトな表現である「潜在ダイナミクスモデル」の概念を導入します。他の画像ベースの計画モデルのように、特定の画像から次の画像を予測する代わりに、「PlaNet」は次の潜在状態を予測し、その情報を使用して将来の画像を予測します。
「Dreamer」は「PlanNet」を活用して、ある画像から次の画像に直接予測するのではなく、入力画像から計算される一連のコンパクトなモデル状態に基づいて結果を予測します。オブジェクトの種類、オブジェクトの位置、オブジェクトとその周囲との相互作用など、将来の結果を予測するのに役立つ概念を表すモデル状態の生成を自動的に学習します。エージェントの過去の経験から一連の画像、行動、および報酬が与えられると、「Dreamer」は「世界モデル」を学習します。

「PlaNet」を使用する利点の1つは、計算効率です。「Dreamer」は、単一のGPUを使用して数千の画像を予測でき、汎化を促進できます。

5. ステップ2 : 行動学習
「モデルベース」のDRLの課題の1つは、大量の計算コストをかけずに長期的な結果を予測することです。「Dreamer」は、「世界モデル」の予測によるバックプロパゲーションを介して「バリューネットワーク」と「アクターネットワーク」を学習することにより、この課題を克服します。エージェントは「アクターネットワーク」を効率的に学習し、予測された状態シーケンスを通じて報酬の勾配を逆方向に伝播することにより、成功する「行動」を予測します。これにより、「Dreamer」の「行動」へのわずかな変更が、将来の報酬の予測にどのように影響するかが決まり、報酬を最も増加させる方向に「アクターネットワーク」を改良できます。
5. ステップ3 : 環境の相互作用
「Dreamer」は、継続的な行動を持つさまざまなタスクのベンチマークを使用して評価されました。ベンチマークには、衝突を予測するのが難しい、報酬がまばらで、カオスのダイナミクス、小さくても関連性のあるオブジェクト、高い自由度、3Dパースペクティブなど、さまざまな課題が含まれていました。
ベンチマークの結果は、「PlaNet」を含む他の最先端のモデルベースのDRLモデルと比較されました。「Dreamer」はすべての選択肢よりも優れたパフォーマンスを発揮し、環境とのやり取りを少なくして関連するパフォーマンスを実現しました。

「Dreamer」は非常に興味深いプロジェクトであり、モデルベースのDRLエージェントが長期的なタスクをマスターする方法についての見通しを提供します。新しいエージェントは、競合よりも明確な改善を提供し、画像入力から関連するパフォーマンスマスタリング制御タスクを示しました。
GoogleとDeepMindは、GitHubでの「Dreamer」の初期実装をオープンソース化しています。
この記事が気に入ったらサポートをしてみませんか?