text-generation-webui で RWKV を試す

「text-generation-webui」で「RWKV」を試してみたので、まとめました。
・Windows 11
【最新版の情報は以下で紹介】
1. text-generation-webui
「text-generation-webui」は、大規模言語モデルのWeb UIです。LLaMA、llama.cpp、GPT-J、Pythia、OPT、GALACTICAなどの大規模言語モデルをローカルで実行できます。
2. インストール
「text-generation-webui」のインストール手順は、次のとおりです。
(1) 「oobabooga-windows.zip」をダウンロードして解凍し、C:¥直下に配置。
「ファイル名が長すぎます。」エラーがでたためC:¥直下に置いてます。

(2) 「start_windows.bat」の実行。
インストール種別を聞かれたら、A (NVIDIA)を指定します。NVIDIAのGPUがない場合はD (CPU) で良さそうです。
A) NVIDIA
B) AMD
C) Apple M Series
D) None (I want to run in CPU mode)
Input> Aダウンロードモデルを聞かれたら、M (なし) を指定します。
A) OPT 6.7B
B) OPT 2.7B
C) OPT 1.3B
D) OPT 350M
E) GALACTICA 6.7B
F) GALACTICA 1.3B
G) GALACTICA 125M
H) Pythia-6.9B-deduped
I) Pythia-2.8B-deduped
J) Pythia-1.4B-deduped
K) Pythia-410M-deduped
L) Manually specify a Hugging Face model
M) Do not download a model
Input> Mインストール成功すると、「text-generation-webui」フォルダができてます。
3. モデルの準備
モデルの準備手順は、次のとおりです。
(1) HuggingFaceからRWKVのモデルをダウンロードし、「text-generation-webui/models」に配置。
・RWKV-4-Raven-7B-v10-Eng89%-Jpn10%-Other1%-20230420-ctx4096
(2) 「20B_tokenizer.json」をダウンロードし、「text-generation-webui/models」に配置。
4. 実行
実行手順は、次のとおりです。
(1) 「cmd_windows.bat」の実行。
(2) 「server.py」を実行。
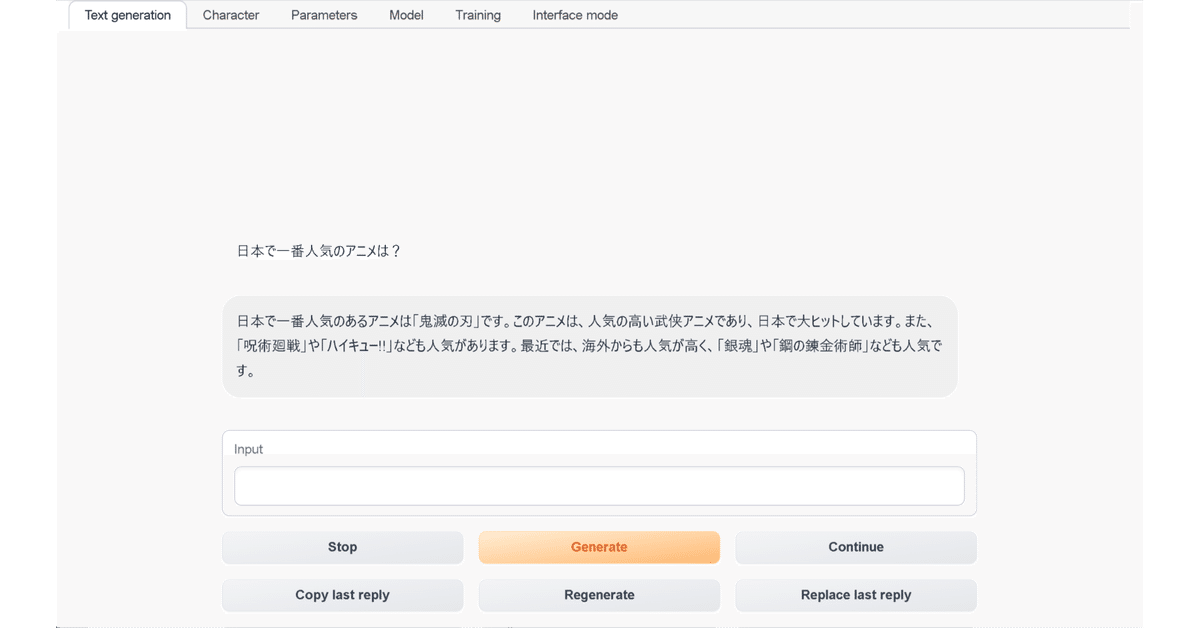
$ python server.py --chat --model-menu(3) URLが表示されたらブラウザで開く。
Running on local URL: http://127.0.0.1:7860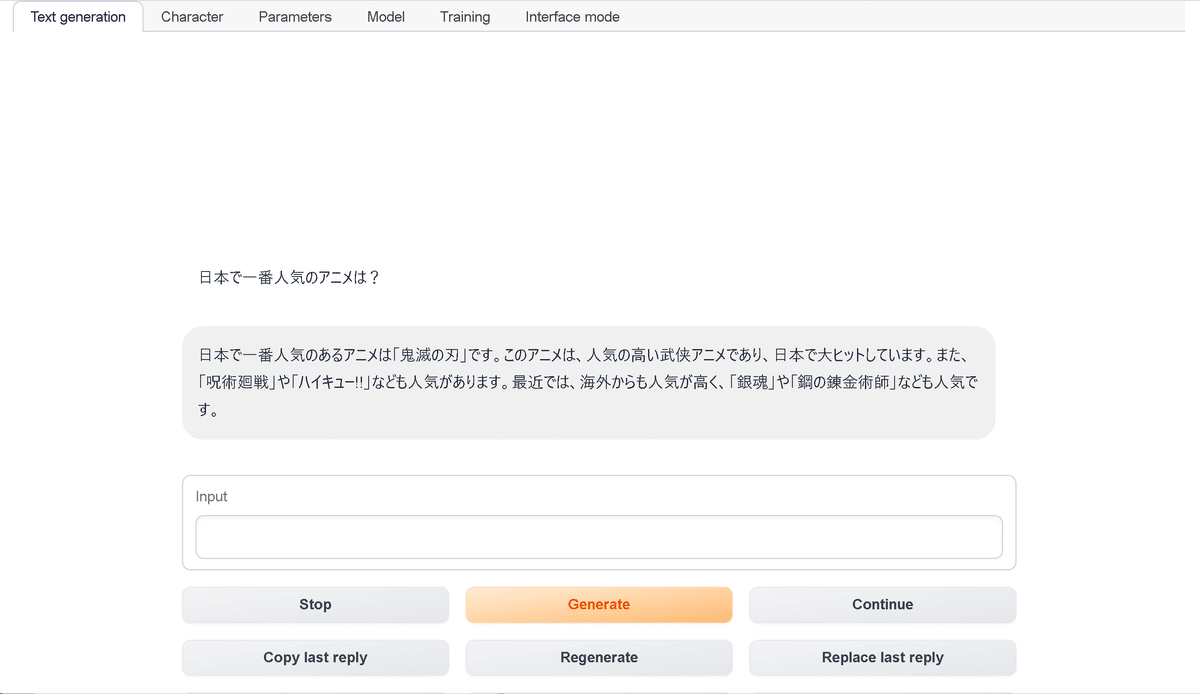
【おまけ】 server.py のパラメータ
server.py のパラメータは、次のとおりです。
・-h, --help : ヘルプ
・--notebook : notebookモードでWeb UIを起動。入出力が同じテキストボックスに書き込まれる
・--chat : chatモードでWeb UIを起動。Character.AIに似たスタイル
・--character <CHARACTER> : chatモードでロードするキャラクター名
・--model <MODEL> : デフォルトでロードするモデル
・--lora <LORA> [LORA ...] : ロードするLoRAのリスト。複数の場合は、名前をスペースで区切る。
・--model-dir <MODEL_DIR> : modelディレクトリのパス
・--lora-dir <LORA_DIR> : loraディレクトリのパス
・--model-menu : 初回起動時にターミナルにモデルメニューを表示
・--no-stream : テキスト出力のストリーミングを使用しない
・--settings <SETTINGS> : インタフェース設定のjsonを指定。例はsettings-template.jsonを参照。settings.jsonというファイル名にすると--settingsの指定なしに読み込まれる
・--extensions <EXTENSIONS> [EXTENSIONS ...] : ロードする拡張機能のリスト。複数の場合は、名前をスペースで区切る。
・--verbose : 詳細情報の出力
・--cpu : CPUの使用 (低速)
・--auto-devices : 利用可能なGPUとCPU間でモデルを自動分割。
・--gpu-memory <GPU_MEMORY> [GPU_MEMORY ...] : GPUごとに割り当てるGiB単位の最大GPUメモリ (例: --gpu-memory 10 5)
・--cpu-memory <CPU_MEMORY> : オフロードされた重みに割り当てるGiB単位の最大CPU メモリ
・--disk : GPUとCPUを組み合わせるにはモデルが大きすぎる場合は、残りのレイヤーをディスクに送信
・--disk-cache-dir <DISK_CACHE_DIR> : キャッシュを保存するディレクトリパス
・--load-in-8bit : モデルを8bit精度で読み込む
・--bf16 : モデルをbfloat16精度で読み込む (NVIDIA Ampere GPUが必要)
・--no-cache : キャッシュを利用しない (VRAMの使用量が少し減るが、パフォーマンスは低下)
・--xformers : xformerのメモリ効率のAttensionを使用 (トークン/秒が増加)
・--sdp-attention : torch 2.0のsdp attensionの使用
・--trust-remote-code : モデルのロード中に trust_remote_code=True を指定。ChatGLMで必要
・--threads <THREADS> : 使用するスレッド数
・--n_batch <N_BATCH> : llama_evalを呼び出すときにまとめてバッチ処理するプロンプトトークンの最大数。
・--no-mmap : mmapを使用しない
・--mlock : システムがモデルをRAMに保持するように強制
・--wbits <WBITS> : ビット単位で指定された精度で事前に量子化されたモデルを読み込む (2、3、4、8をサポート)
・--model_type <MODEL_TYPE> : 事前量子化モデルのモデル種別 (LLaMA、OPT、GPT-Jをサポート)
・--groupsize <GROUPSIZE> : グループサイズ
・--pre_layer <PRE_LAYER> : GPUに割り当てるレイヤー数。このパラメータを設定すると、4ビットモデルのCPUオフロードが有効になる
・--checkpoint <CHECKPOINT> : 量子化されたチェックポイントのパス。指定しない場合は、自動検出
・--monkey-patch : 量子化されたモデルで LoRA を使用するためのモンキーパッチを適用
・--quant_attn : (triton) quant attentionの有効化
・--warmup_autotune : (triton) warmup autotuneの有効化
・--fused_mlp : (triton) fused mlpの有効化
・--flexgen : FlexGen オフロードの有効化
・--percent PERCENT [PERCENT ...] : (flexgen) 割り当てのパーセンテージを、スペースで区切られた6つの数字で指定 (デフォルト: 0, 100, 100, 0, 100, 0)
・--compress-weight : (flexgen) weight compressionの有効化
・--pin-weight [PIN_WEIGHT] : (flexgen) 重みを固定するかどうか (FalseでCPUメモリ減少)
・--deepspeed : Transformers統合を介して、推論にDeepSpeed ZeRO-3を使用
・--nvme-offload-dir <NVME_OFFLOAD_DIR> : (deepspeed) ZeRO-3 NVME オフロードに使用するディレクトリ
・--local_rank <LOCAL_RANK> : (deepSpeed) 分散セットアップのオプションの引数
・--rwkv-strategy <RWKV_STRATEGY> : (rwkv) strategy (例: "cpu fp32","cuda fp16", "cuda fp16i8")
・--listen : ローカルネットワークから Web UI にアクセスできるようにする
・--listen-host <LISTEN_HOST> : サーバーが使用するホスト名
・--listen-port <LISTEN_PORT> : サーバーが使用するポート番号
・--share : 公開URLの作成。Google Colabなどで Web UI を実行する場合に便利
・--auto-launch : 起動時にデフォルトブラウザでWeb UIを開く
・--gradio-auth-path <GRADIO_AUTH_PATH> : 勾配認証ファイルのパスを設定。このファイルには、「u1:p1,u2:p2,u3:p3」の形式で1つ以上の user:password のペアが含まれている必要がある
・--api : API拡張の有効化
・--public-api : Cloudflareを使用してAPIの公開URLを作成
この記事が気に入ったらサポートをしてみませんか?