
OpenAI Gym入門 / Gymインタフェース

1. Gymインタフェース
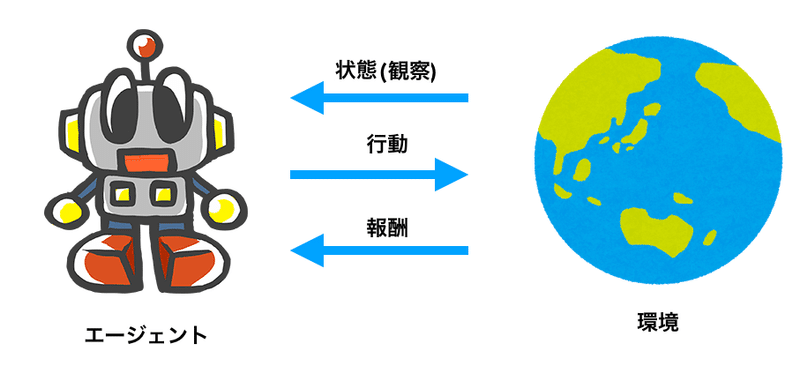
「環境」と「エージェント」の間のGymインターフェースを解説します。
2. 環境の生成
「環境」の生成は次の通りです。
env = gym.make("環境ID")ここで、「環境ID」は、インストールされている環境のリスト内にある環境IDです。
3. 環境のリセット
Gymインターフェイスの最初の矢印は、「環境」から「エージェント」への矢印で、「状態(観察)」を渡すことがわかります。
env.reset()によって、「環境」から最初の「状態(観察)」を取得します。
state = env.reset()「状態」は環境のもつ情報、「観察」はエージェントが取得できる情報を示します。「完全観測環境」ではエージェントが全ての情報「状態」を取得できます。「部分観測環境」ではエージェントは部分的な情報「観測」のみ取得できます。
部分観測環境:観察(Observation) ⊂ 状態(State)
完全観測環境:観察(Observation) = 状態(State)4. 1ステップの実行
「エージェント」が「行動」を選択し、その「行動」を「環境」に送って何が起こるかを確認します。これは、エージェント用に開発した学習アルゴリズムが処理すべき部分になります。
実行する行動を決選択したら、env.step()を使って環境に送信します。
このメソッドは、「次の状態(state)」「報酬(reward)」「エピソード完了(done)」「情報(info)」の4つの値を返します。
・次の状態(state):Object
行動が実行された後の「次の状態」を示します。
・報酬(reward):Float
採った行動がどれだけ価値があるかを示す即時報酬です。
・エピソード完了(done):Boolean
エピソード完了時はTrueが返されます。
その場合は、環境をリセットします。
・情報(info):Dict
デバッグ目的の追加情報です。
この情報はエージェントの行動選択には利用しません。
※「次の状態」は正確には「観察」の場合もありますが、両方書くとわかりにくいので、「次の状態」として説明します。
5. 強化学習サイクルをコードで記述
強化学習サイクルをコードで記述すると次のようになります。学習アルゴリズムはまだないので、ランダム行動を指定しています。
このコードは学習アルゴリズムの実装の出発点になります。
#!/usr/bin/env python
import gym
# 定数
NUM_EPISODES = 10 # 学習するエピソード数
MAX_STEPS = 500 # 1エピソードの最大ステップ数
# 環境の生成
env = gym.make("MountainCar-v0")
# 学習ループ
for episode in range(NUM_EPISODES):
# 環境のリセット
state = env.reset()
# 1エピソードのループ
for step in range(MAX_STEPS):
# 環境のリセット
env.render()
# 行動の取得
action = env.action_space. sample()
# 1ステップの実行
state, reward, done, info = env.step(action)
# エピソード完了時
if done is True:
print("episode:{} step:{}".format(episode, step+1))
breakこの記事が気に入ったらサポートをしてみませんか?