
Llama 3.2 の概要

以下の記事が面白かったので、簡単にまとめました。
・Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
1. Llama 3.2
「Llama 3.2 11B・90B」は、チャートやグラフを含むドキュメントレベルの理解、画像キャプション、自然言語の説明に基づいて画像内のオブジェクトの方向を正確に特定するなど、画像推論のユースケースをサポートします。
「Llama 3.2 1B・3B」は、多言語テキスト生成とツール呼び出し機能に非常に優れています。これらのモデルにより、開発者は、データがデバイスから外に出ることのない強力なプライバシーを備えた、パーソナライズされたオンデバイスエージェントアプリケーションを構築できます。
2. モデル評価
「Llama 3.2 11B・90B」の視覚モデルは、画像認識やさまざまな視覚理解タスクにおいて、主要な基礎モデルである「Claude 3 Haiku」「GPT4o-mini」と競合しています。
「Llama 3.2 3B」は、指示に従う、要約する、プロンプトを書き直す、ツールを使用するなどのタスクで「Gemma 2 2.6B」「Phi 3.5-mini」よりも優れており、「Llama 3.2 1B」は「Gemma」と競合しています。
幅広い言語にまたがる 150を超えるベンチマークデータセットでパフォーマンスを評価しました。「Vision LLM」については、画像理解と視覚推論のベンチマークでパフォーマンスを評価しています。


3. ビジョンモデル
「Llama 3.2 11B・90B」には、画像推論をサポートするまったく新しいモデル アーキテクチャが必要でした。画像入力サポートを追加するために、事前学習済みの画像エンコーダーを事前学習済みの言語モデルに統合する一連のアダプター重みを学習しました。アダプターは、画像エンコーダー表現を言語モデルに取り込む一連のクロスアテンションレイヤーで構成されています。テキストと画像のペアでアダプターを学習して、画像表現を言語表現に合わせました。アダプターの学習中に、画像エンコーダーのパラメータも更新しましたが、言語モデルのパラメータは意図的に更新しませんでした。そうすることで、テキストのみの機能はすべてそのまま維持され、開発者に「Llama 3.1」の代替品を提供します。
学習パイプラインは、事前学習済みの「Llama 3.1」テキストモデルから始まる複数のステージで構成されています。まず、画像アダプターとエンコーダーを追加し、大規模なノイズの多い (画像、テキスト) ペアデータで事前学習します。次に、中規模の高品質のドメイン内および知識強化された (画像、テキスト) ペア データで学習します。
学習後では、テキストモデルと同様のレシピを使用して、教師ありファインチューニング、拒否サンプリング、直接的な好みの最適化を数回実行します。「Llama 3.1」を使用してドメイン内の画像の上に質問と回答をフィルタリングおよび拡張し、報酬モデルを使用してすべての候補回答をランク付けして高品質のファインチューニングデータを提供することで、合成データ生成を活用します。また、安全性緩和データを追加して、モードの有用性を維持しながら、高いレベルの安全性を備えたモデルを作成します。
最終的な結果は、画像とテキストの両方のプロンプトを取り込み、その組み合わせを深く理解して推論できるモデルのセットです。これは、「Llama」がさらに豊富なエージェント機能を備えるためのもう1つのステップになります。
4. 軽量モデル
「Llama 3.2 1B・3B」では、プルーニングと蒸留という2つの手法を採用し、デバイスに効率的に適合する初の高性能軽量Llamaを実現しました。
剪定により、Llama群の既存モデルのサイズを縮小しながら、可能な限り多くの知識とパフォーマンスを回復することができました。「1B・3B」では、「Llama 3.1 8B」からの構造化された剪定を 1 回限りの方法で実行するアプローチを採用しました。これには、ネットワークの一部を体系的に削除し、重みと勾配の大きさを調整して、元のネットワークのパフォーマンスを維持しながら、より小さく効率的なモデルを作成することが含まれます。
知識蒸留は、より小さなモデルが最初から作成するよりも教師を使用した方が優れたパフォーマンスを達成できるという考えのもと、より大きなネットワークを使用してより小さなネットワークに知識を伝達します。「Llama 3.2 1B・3B」では、「Llama 3.1 8B・70B」のロジットをモデル開発の事前学習段階に組み込み、これらのより大きなモデルからの出力 (ロジット) をトークン レベルのターゲットとして使用しました。知識蒸留は、パフォーマンスを回復するために剪定後に使用されました。
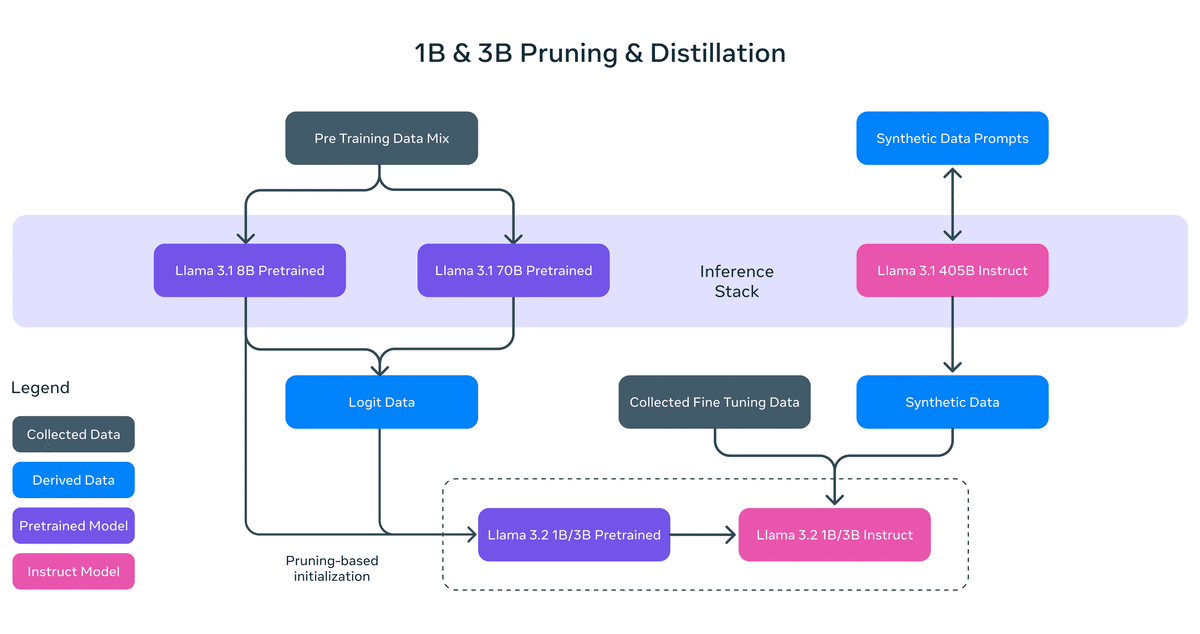
学習後では、「Llama 3.1」と同様のレシピを使用し、事前学習済みモデルに対して複数回の調整を行って最終的なチャット モデルを作成します。各ラウンドには、「SFT」「RS」「DPO」が含まれます。
学習後、事前学習済みモデルと同じ品質を維持しながら、コンテキスト長のサポートを128Kトークンに拡張します。また、高品質を確保するために、慎重なデータ処理とフィルタリングを経た合成データ生成にも取り組んでいます。要約、書き直し、指示の追跡、言語の推論、ツールの使用など、複数の機能にわたって高品質になるようにデータを慎重にブレンドして最適化します。
コミュニティがこれらのモデルを革新できるように、世界トップ2のモバイルSoC企業である Qualcomm と Mediatek、そしてモバイルデバイスの99%に基礎的なコンピューティングプラットフォームを提供する Arm と緊密に連携しました。本日リリースされる重みは、BFloat16 数値に基づいています。さらに高速に実行される量子化されたバリアントを積極的に調査しており、その詳細については近日中にお知らせする予定です。
5. Llama Stack Distribution
7月に、 Llamaをカスタマイズしてエージェントアプリケーションを構築するための標準的なツールチェーン コンポーネント (ファインチューニング、合成データ生成) の標準化されたインターフェイス「Llama Stack API」に関するコメントのリクエストをリリースしました。
それ以来、API を現実のものにする作業に取り組み、推論、ツールの使用、RAG用のAPIのリファレンス実装を構築し、さらに、パートナーと協力して、APIのプロバイダーになるように調整しました。最後に、連携して機能する複数のAPIプロバイダーをパッケージ化して、開発者に単一のエンドポイントを提供する方法として、「Llama Stack Distribution」を導入しました。
現在、オンプレミス、クラウド、単一ノード、デバイス上など、複数の環境で Llamaを操作できるようにする、シンプルで一貫性のあるエクスペリエンスをコミュニティと共有しています。

リリースの全セットには以下が含まれます:
(1) Llama Stack Distribusionを構築、構成、実行するための Llama CLI (コマンドラインインターフェイス)
(2) Python、Node、Kotlin、Swift を含む複数の言語でのクライアントコード
(3) Llama Stack DistributionサーバーおよびエージェントAPIプロバイダー用の Docker コンテナ
(4) 複数の配布
(4-1) Meta内部実装とOllamaによる単一ノードLlamaスタック分散
(4-2) AWS、Databricks、Fireworks、Together 経由の Cloud Llama Stack Distribution
(4-3) PyTorch ExecuTorch を介して実装された iOS 上のオンデバイス Llama スタック配布
(4-4) DellがサポートするオンプレミスのLlama Stack Distribution

6. システムレベルの安全性
セーフガードファミリーに新たなアップデートを追加しました。
、「Llama 3.2 11B・90B」の画像理解機能の入出力をフィルタリングするように設計された「Llama Guard 3 11B Vision」をリリースしました。
デバイス上などのより制約の多い環境で使用できるように「Llama 3.2 1B・3B」をリリースするとともに、「Llama Guard」を最適化して導入コストを大幅に削減しました。
これらの新しいソリューションは、Metaのリファレンス実装、デモ、アプリケーションに統合されており、オープンソースコミュニティが初日から使用できる状態になっています。