
text-embedding-ada-002 の概要

新しい埋め込みモデル「text-embedding-ada-002」についてまとめました。
1. text-embedding-ada-002
OpenAIから新しい埋め込みモデル「text-embedding-ada-002」がリリースされました。性能が大幅に向上し、以前の最も高性能なモデル「davinci」よりも多くのタスクで上回っています。adaの費用はdavinciの0.2%になります。
2. 埋め込み
「埋め込み」は、概念を数列に変換したもので、コンピュータがそれらの概念間の関係を理解しやすくするための使います。パーソナライズ、レコメンド、検索などに使うことができます。
「OpenAI API」で埋め込みを取得するコードは、次のとおりです。
import openai
response = openai.Embedding.create(
input="porcine pals say",
model="text-embedding-ada-002"
)3. 以前のモデルとの比較
◎ テキスト検索

◎ コード検索
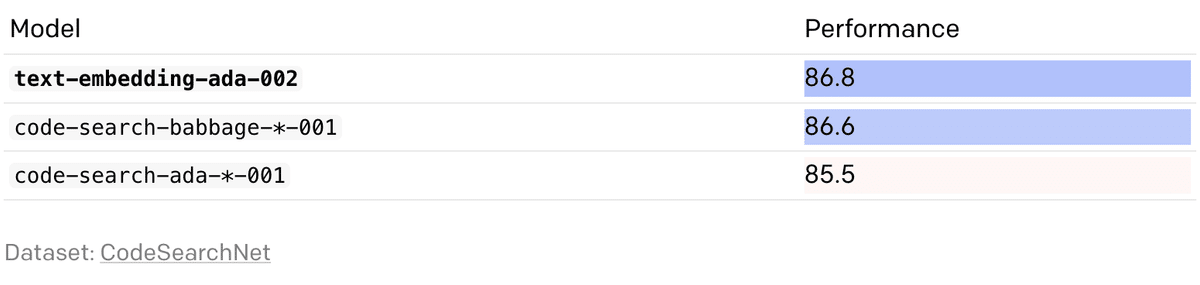
◎ 文の類似性

◎ テキスト分類

以前のモデルとの違いは、次のとおりです。
◎ モデルの統合
機能別のモデル (text-similarity、text-search-query、text-search-doc、code-search-text、code-search-code)を1つに統合しました。
◎ コンテキストの長さの増加
コンテキストの長さが 2048 から 8192 に増えました。
◎ 埋め込みのサイズの減少
埋め込みのサイズは、davinci-001の8分の1になりました。
◎ 価格の値下げ
以前の同じサイズのモデルと比べ、価格を90%値下げしました。 新モデルは、以前のdavinci以上のパフォーマンスで、99.8%低い価格を実現しています。
ただし、SentEval線形プローブ分類ベンチマークでは、新モデルはtext-similarity-davinci-001 を下回っていました。分類予測の場合は、比較して最適なモデルを選択することを推奨されています。