
text-generation-webui の 設定項目まとめ

「text-generation-webui」にどんな設定項目があるのかをまとめました。
前回
1. Text generation タブ
「Text generation タブ」は、テキスト生成を行うタブです。
以下の3つのモードがあり、「Inference mode タブ」で切り替えます。
・chatモード : チャットアプリ風のモード
・notebookモード : Playground風のモード
・defaultモード : 入出力が別れているモード
1-1. chatモード

・Input : メッセージ入力
・Stop : テキスト生成の停止
・Generate : テキスト生成
・Continue : テキスト生成の続きの生成
・Impersonate : なりすまし
・Regenerate : テキスト再生成
・Remove last : 最後の会話ペアの削除
・Copy last reply : 最後の返信のコピー (最後の返信→Input)
・Replace last reply : 最後の返信の置換 (Input ←→ 最後の返信)
・Send dummy message : ダミーメッセージの送信
・Send dummy reply : ダミー返信の送信
・Clear history : チャット履歴のクリア
・Start reply with : 返信の開始文字の指定
・Mode : モード
・chat : チャットUI
・chat-instruct : チャットUI + Instructionテンプレート使用
・instruct : Instructテンプレート使用
※「chat」はキャラクター、「instruct」はInstructionテンプレートを「Chat settings」で設定する必要があります。
・Chat style : チャットUIのCSS (デザイン指定)
・cai-chat
・messenger
・TheEncrypted777
・wpp
・gallery : キャラクターの選択
1-2. notebookモード

・TextBox : 入力 + 出力
・Generate : テキスト生成
・Stop : テキスト生成の停止
・Undo : アンドゥ
・Regenerate : テキスト再生成
・Max new tokens : 最大新規トークン数
・Prompt : プロンプト選択
・Count Tokens : トークンのカウント
1-3. defaultモード
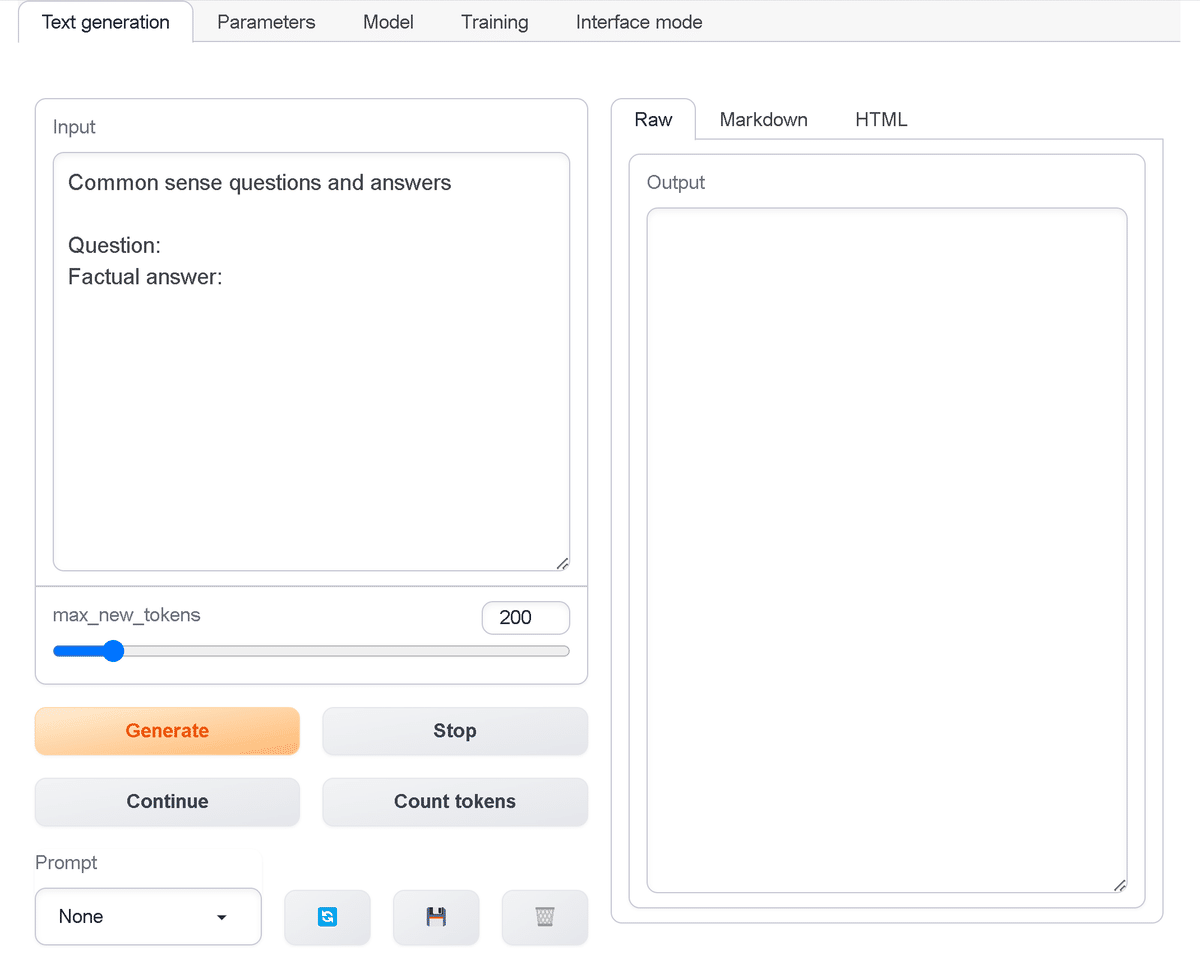
・Input : 入力
・Output : 出力
・Max new tokens : 最大新規トークン数
・Generate : テキスト生成
・Stop : テキスト生成の停止
・Regenerate : テキスト再生成
・Count Tokens : トークンのカウント
・Prompt : プロンプト選択
2. Chat settings タブ
「Chat settings タブ」は、チャット設定を行うタブです。

「Character」では、「chat」で使用するキャラクターを設定します。
・Your name : ユーザー名
・Character's name : キャラクター名
・Context : プロンプトのはじめじ記述する文字列 (キャラクターの性格説明など)
・Greeting : 新しい会話を始める時のキャラクターのオープニングメッセージ
・Character picture : キャラクター画像
・Your picture : ユーザー画像
「Instruction tempate」では、「instruct」で使用するテンプレートを設定します。
・User string : ユーザーを示す文字列
・Bot string : キャラクターを示す文字列
・Context : 文脈
・Turn template : キャラクターの返信のためのプロンプトテンプレート
・Coimmand for chat-instruction mode : プロンプトに付加する指示
・Chat history : チャット履歴のアップロード・ダウンロード
・Upload character : キャラクターのアップロード・ダウンロード
3. Parameters タブ
「Parameters タブ」は、generate()のパラメータ設定を行うタブです。
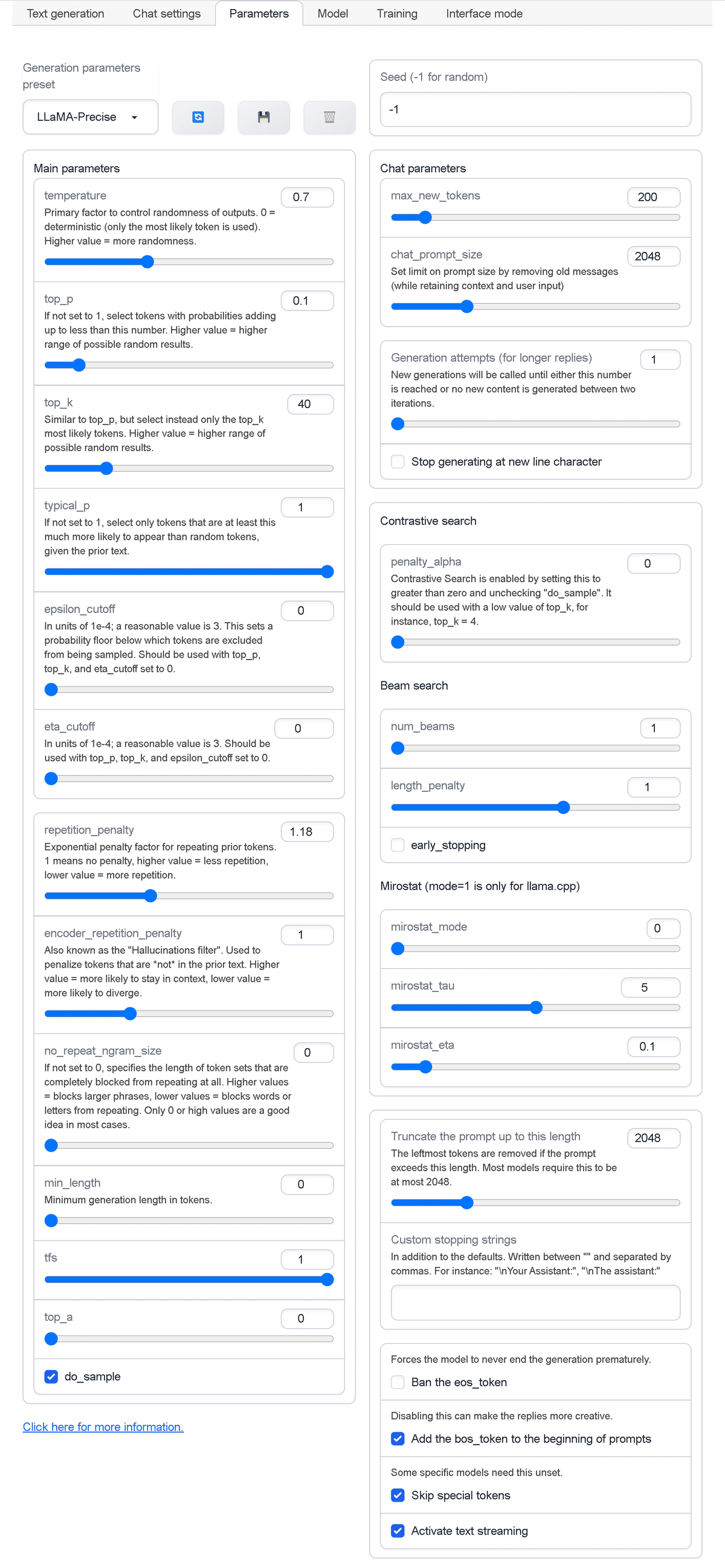
・Generation parameters preset : テキスト生成のパラメータのプリセット
・Seed : 乱数シード
メインパラメータは、次のとおりです。
・temperature : 出力のランダムさ。0=決定的。値が大きいほどランダム性が高くなる
・top_p : 1でない場合、合計がこの値より小さくなる確率を持つトークンを選択。値が高いほど出力がランダム
・top_k : top_pと似ているが、代わりに最も可能性の高いtop_kトークンのみを選択。値が高いほど出力がランダム
・typical_p : 1でない場合、前述のテキストを考慮して、ランダムなトークンよりも出現する可能性がこの値より高いトークンのみ選択。
・epsilon_cutoff : 1e-4の単位。適切な値は3。トークンがサンプリングから除外される確率の下限を設定。top_p、top_k、eta_cutoffを0に設定して使用する必要がある
・eta_cutoff : 1e-4の単位。適切な値は3。top_p、top_k、eta_cutoffを0に設定して使用する必要がある
・repetition_penalty : 前のトークンを繰り返す場合の指数ペナルティ係数。1はペナルティがないことを意味し、値が高いほど繰り返しが少なくなり、値が低いほど繰り返しが多くなる
・encoder_repetition_penalty : ハルシネーションフィルター。前のテキストに存在しないトークンにペナルティを与える。値が高いほどコンテキスト内にとどまる可能性が高く、値が低いほど発散する可能性が高くなる
・no_repeat_ngram_size : 0でない場合は、反復が完全にブロックされるトークンの長さを指定。値が高いほど大きなフレーズがブロックされ、値が低いほど単語や文字の繰り返しがブロックされる。ほとんどの場合、0または高い値のみ使用することを推奨
・min_length : トークンの最小長
・tfs
・top_a
・do_sample
チャットパラメータは、次のとおりです。
・max_new_tokens : 新規トークンの最大数
・chat_prompt_size : (コンテキストとユーザー入力を保持しながら)古いメッセージを削除して、プロンプトサイズの制限を設定
・Generation attempts (for longer replies) : この数に達するか、2つの反復の間に新しいコンテンツが生成されなくなるまで、新しい世代が呼び出される
・Stop generating at new line character : 改行文字の生成の停止
「Contrastive serch」のパラメータは、次のとおりです。
・penalty_alpha : 「Contrastive serch」は、これを0より大きく設定し、do_sampleのチェックを外すと有効になる。top_kの低い値(4など)で使用する必要がある
「Beam search」のパラメータは、次のとおりです。
・num_beams
・length_penalty
・early_stopping
「Mirostat」のパラメータは、次のとおりです。
・mirostat_mode
・mirostat_tau
・mirostat_eta
その他のパラメータは、次のとおりです。
・Truncate the prompt up to this length : プロンプトが長さを超える場合、左端のトークンを削除。ほどんどのモデルで2048、
・Customstopping strings : デフォルトに加えて、カンマで区切って記述 (「\nAssistant:」など)
・Forces the model to never end the generation prematurely : EOSトークンの禁止
・Disabling this can make the replies more creative : プロンプト先頭にbosトークンを追加
・Skip special tokens : スペシャルトークンのスキップ
・Activate text streaming : ストリーミングの有効化
4. Model タブ
「Model タブ」は、モデルの設定を行うタブです。
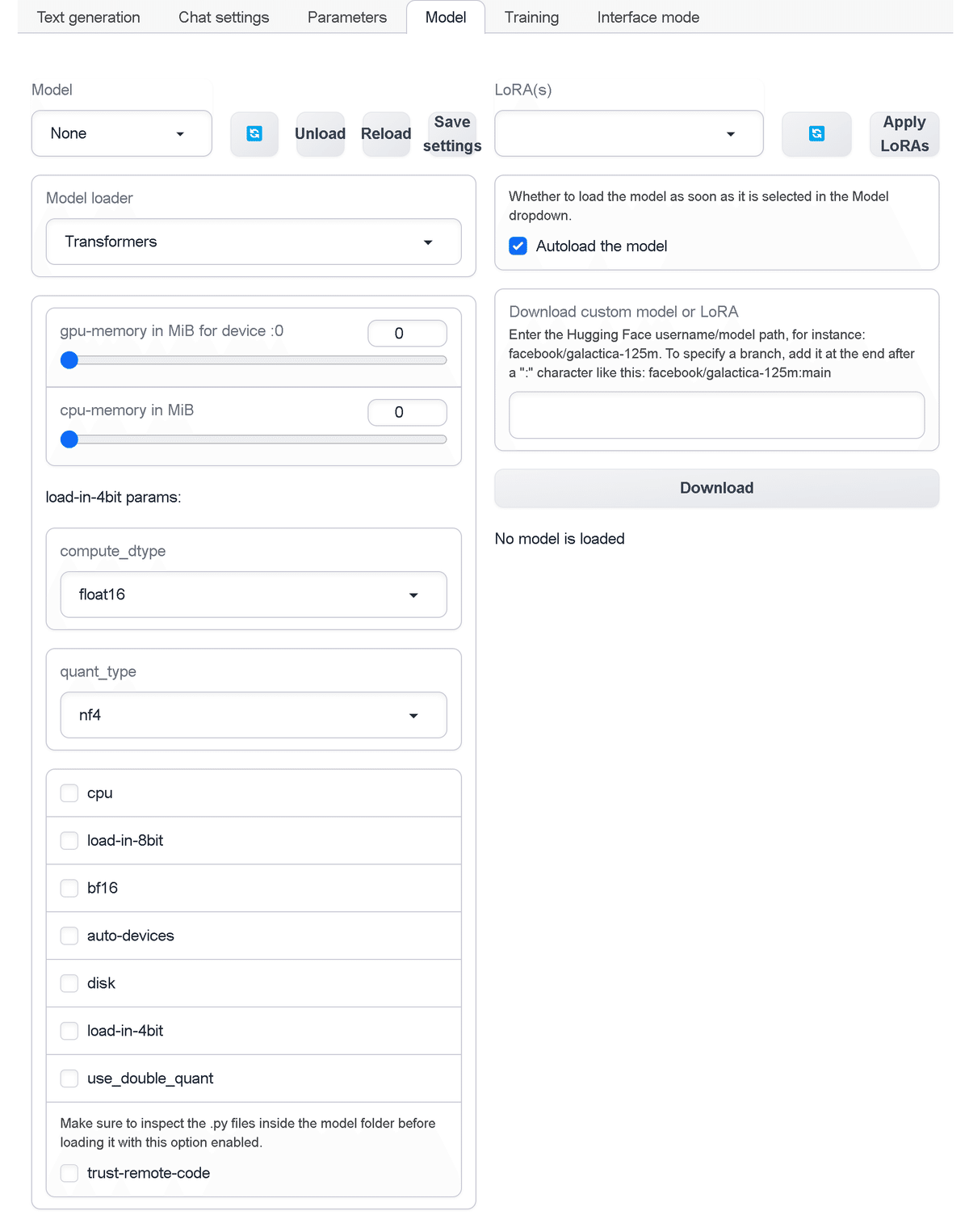
・Model : モデルを選択
・Model loader : モデルローダー
・Transformers
・AutoGPTQ
・GPTQ-for-LLaMa
・ExLlama
・llama.cpp
・gpu-memory in MiB : GPUメモリ (MiB)
・cpu-memory in MiB : CPUメモリ (MiB)
・compute_dtype : PyTorchのデータ型
・bfloat16
・float16
・float32
・quant_type : 量子化のデータ型
・nf4
・np4
・cpu
・load-in-8bit
・bf16
・auto-devices
・disk
・load-in-4bit
・use_double_quant
・trust-remote-code : modelフォルダのpyファイルを検査
・LoRA(s) : LoRAモデルの選択
・Autoload the model : LoRAモデルを選択したらすぐにロードするか
・Download custom model or LoRA : カスタムモデル or LoRAのダウンロード (HuggingFaceのユーザー名/モデル名を入力)
5. Training タブ
「Training タブ」は、モデルのLoRA学習および評価を行うタブです。
5-1. Train LoRA
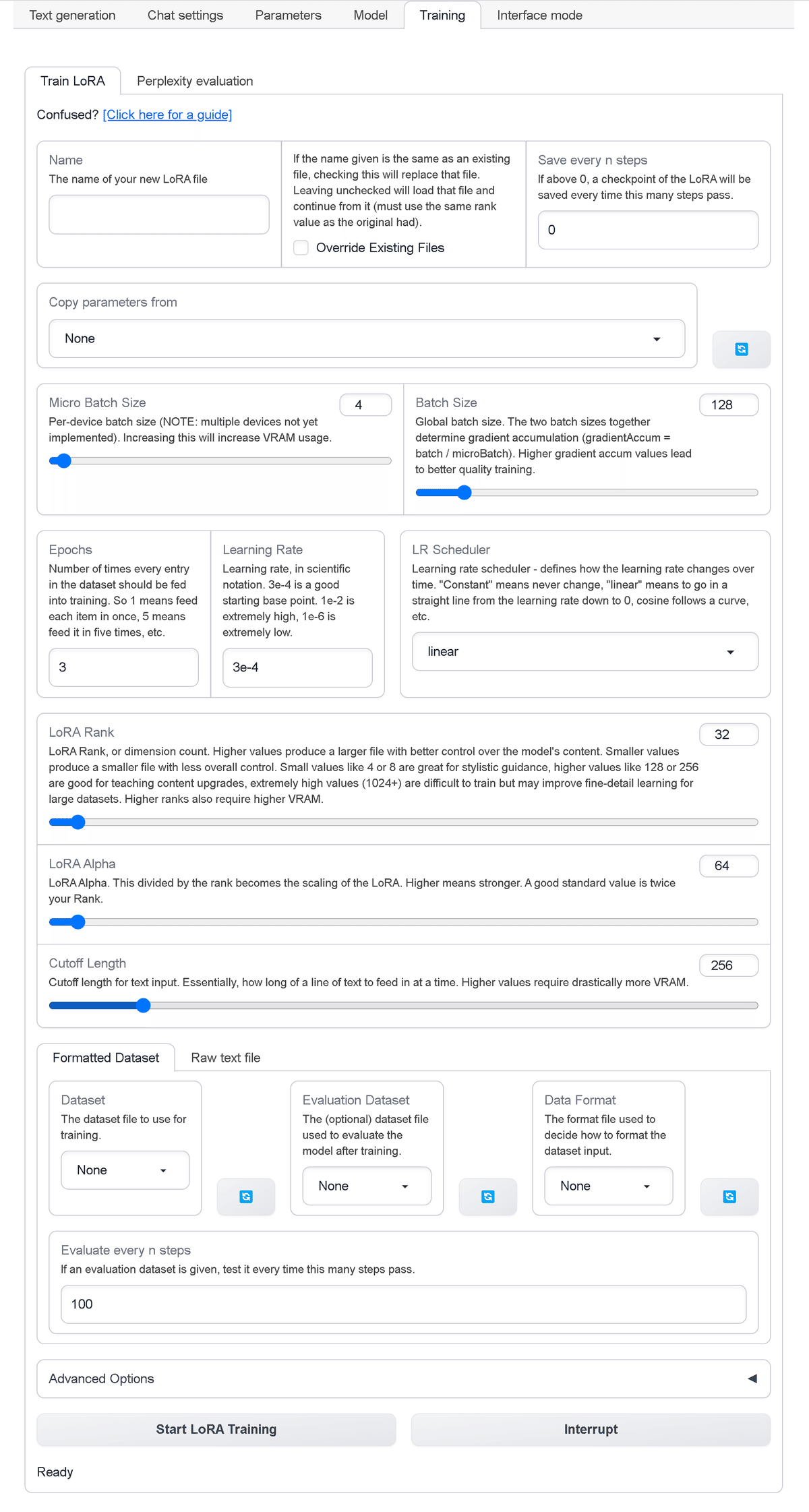
・Name : LoRAモデル名
・Overide Existing Files : 既存のファイルを上書きするか
・Save even n steps : LoRAチェックポイントを何Step毎に保存するか
・Copy parameters from : 設定ファイルからのパラメータのコピー
・Micro Batch Size : デバイス毎のバッチサイズ (複数デバイスはまだ未実装)。これを増やすとVRAM使用量が増加
・Batch Size : グローバルバッチサイズ。2つのバッチサイズをあわせて、勾配の累積 (gradientAccume=batch/microBatch) が決定される。勾配の累積値が高いほど、学習の質が向上
・Epochs : エポック数。1エポックはデータセットの要素を1回フィード
・Learning Rate : 学習率。1e-2は非常に高く、1e-6は非常に低い
・LR Scheduler : 学習率スケジューラ。学習率が時間n経過とともにどのように変化するかを定義
・linear : 0まで直線的に進む
・constant : 変換しない。
・constant_with_warmup
・cosine
・cosine_with_restarts
・polynomial
・inverse_sqrt
・LoRA Rank : 値を大きくすると、モデルのコンテンツをより適切に制御できる大きなファイルが生成される。値を小さくすると、全体的な制御が少なくなり、ファイルが小さくなる。小さな値 (4や8) はスタイル指導に適しており、高い値 (128や256) はコンテンツのアップグレードに適しており、非常に高い値 (1024以上) は大規模データセットを詳細に学習できる可能性がある。Rankが高くなると、より多くのVRAMが必要。
・LoRA Alpha : これをRankで割ったものが、LoRAのスケーリングになる。高いほど強いことを意味する。適切な標準値はRankの2倍
・Cutoff Length : 一度にフィードするテキスト業の長さ。値を大きくすると、大幅に多くのVRAMが必要になる。
「Formatted Dataset」の設定項目は、次のとおりです。
・Dataset : データセット
・Evaluation Dataset : 評価データセット
・Data Format : データセット入力のフォーマット方法
・None
・alpha-chatbot-format
・alpaca-format
・Evaluate every n steps : 何Steps毎に評価するか
「Raw text file」の設定項目は、次のとおりです。
・Text file : 学習する生のテキストファイル
・Hard Cut String : ハードカットする文字列 (デフォルト:\n\n\n)
・Overlap Length : チャンクをどの程度オーバーラップするか
・Prefer Newline Cut Length : チャンクカットを改行方向にシフトする最大文字数
実行ボタンは、次のとおりです。
・Start LoRA Training : LoRA学習の開始
・Interrupt : 割り込み
高度なオプションは、次のとおりです。
・Warmup Steps : トレーナーがモデルを準備し、統計を事前計算して、開始後の学習の品質を向上させるのに役立つ。
・Optimizer : 上級ユーザー向けの様々なオプティマイザー実装オプション
・adamw_torch
・adamw_torch_fused
・adamw_torch_xla
・adamw_apex_fused
・adafactor
・adamw_bnb_8bit
・adamw_anyprecision
・sgd
・adagrad
・Train Only After : 特定のチャンク内のこの文字列より後の文字列のみを学習対象とする。Alpacaデーがセットの場合「### Response:」を使用して応答のみを学習し、入力を無視。
・Enable higher ranks : チェックすると上のRank/Alphaが変更され、さらに高くなる。これは、データセンタークラスのGPUがなければ機能しない。
5-2. Perplexity evaluation
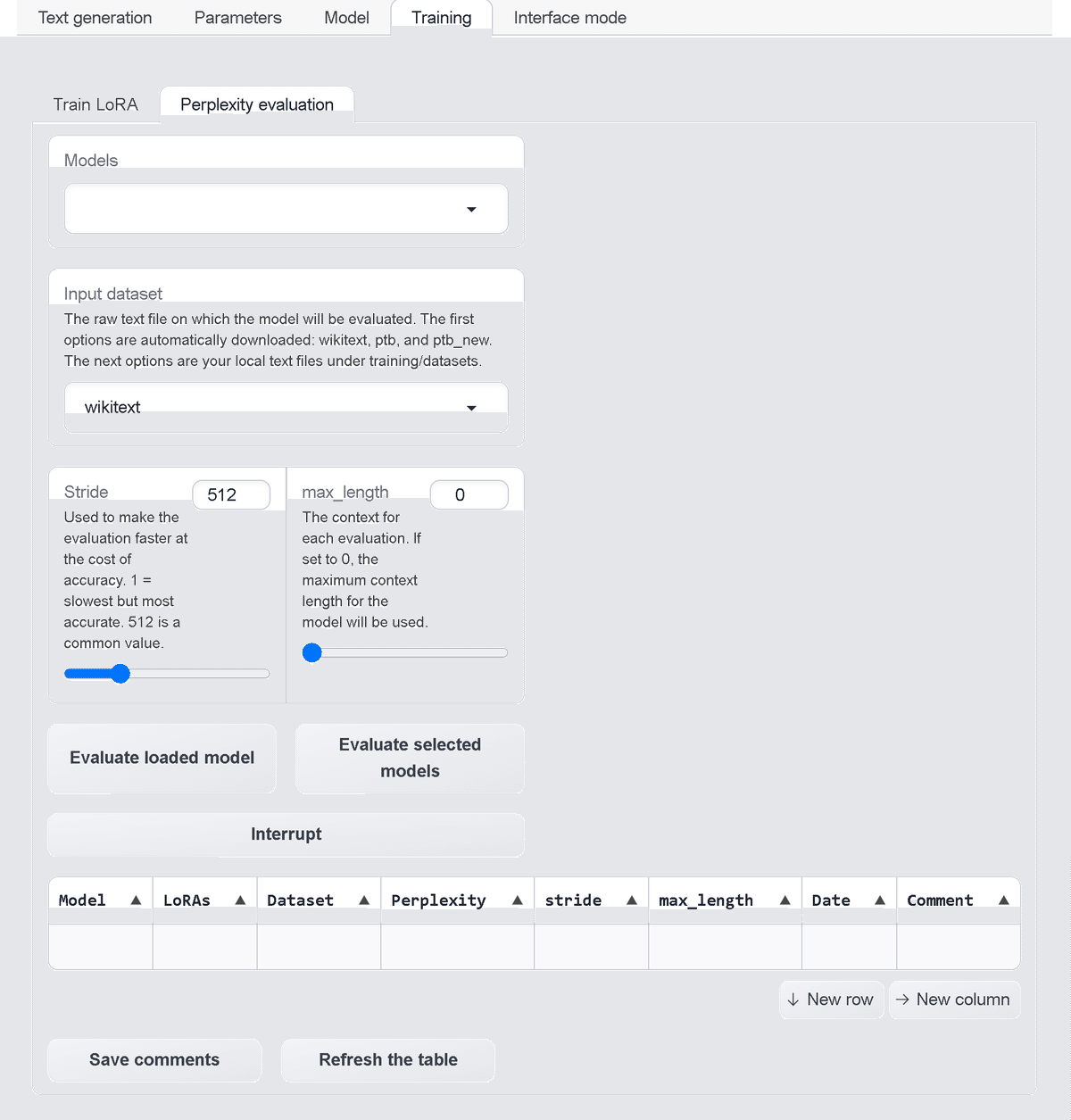
・Models : モデルの選択
・Input dataset : モデルを評価する生のテキスト (training/datasetsに配置)
・wikitext
・ptb
・ptb_new
・dataset_plain
・Stride : 精度を犠牲にして高速化するために使用。1=最も遅いが正確、512=一般的な値
・max_length : コンテキストの最大長
・Evaluate loaded model : ロードしたモデルの評価
・Evaluate selected models : 選択したモデルの評価
・Interrupt : 割り込み
6. Inference mode タブ
「Inference mode タブ」は、推論モードを設定するタブです。
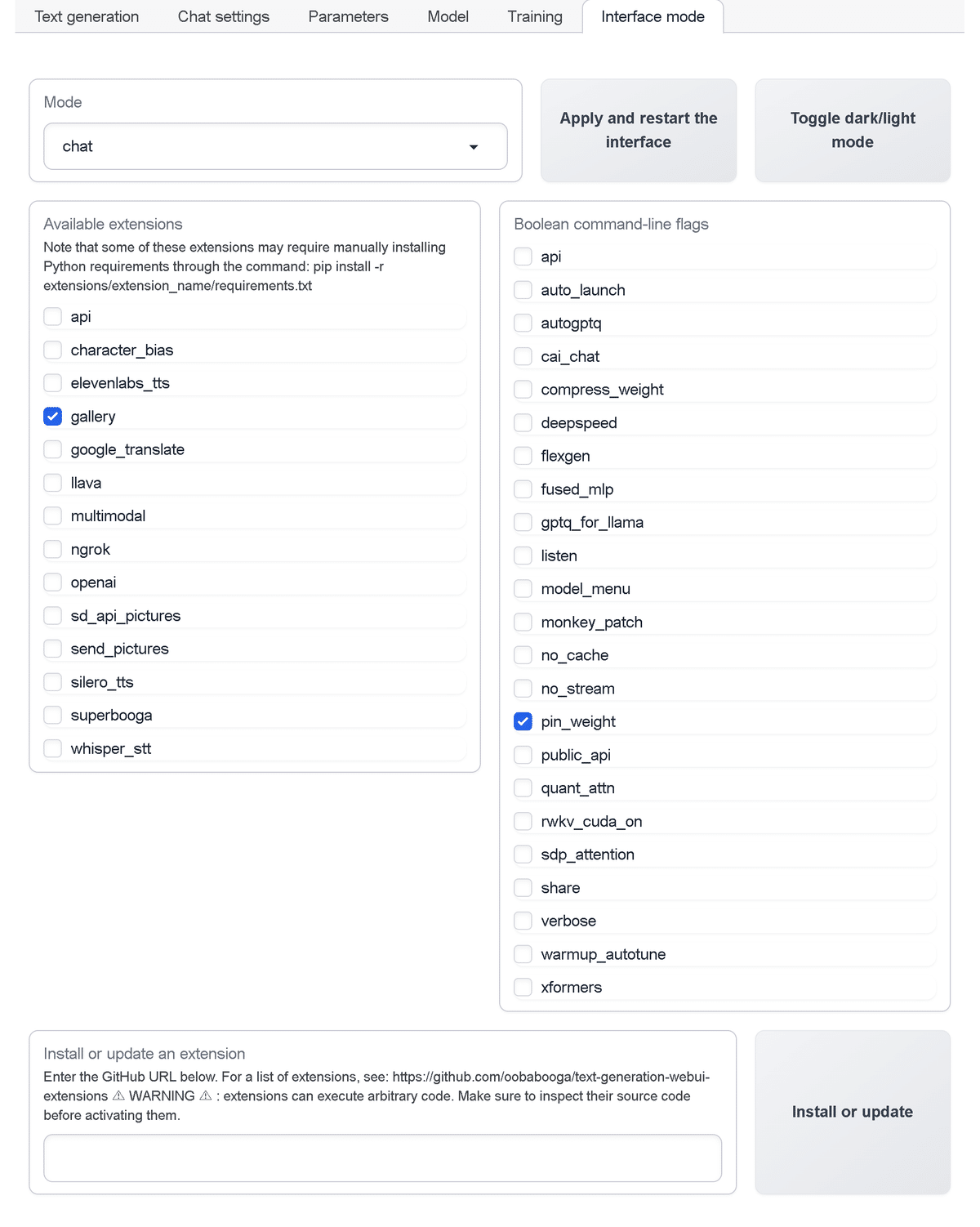
・Mode : モード (default / notebook / chat)
・Apply and restart the Interface : 再起動
・Toggle dark / light mode : ダーク / ライトの切り替え
・Available Extension : 拡張機能
・Boolean command-line flags : コマンドラインフラグ
・Install or Update Extension : 拡張機能のインストールとアップデート
次回
この記事が気に入ったらサポートをしてみませんか?