LLMアプリケーションの記録・実験・評価のプラットフォーム Weave を試す

LLMアプリケーションの記録・実験・評価のプラットフォーム「Weave」がリリースされたので、試してみました。
この入門記事は、「Weights & Biases」のご支援により提供されています。Weights & Biases JapanのNoteでは他にも多くの有用な記事が掲載されていますので是非ご覧ください。

1. Weave
「Weave」は、LLMアプリケーションの記録、実験、評価のためのツールです。「Weights & Biases」が提供する機能の1つになります。
主な機能は、次のとおりです。
・記録 : LLMとのあらゆるやり取りを記録。
・実験 : 様々なパラメータを試して結果を確認。
・評価 : 評価を実行してモデルが改善されたかどうかを測定。
2. Weave の準備
今回は、「Google Colab」で「Weave」を使って「OpenAI」のモデルの記録・実験・評価を行います。
(1) パッケージのインストール。
# パッケージのインストール
!pip install weave(2) Weaveの初期化。
実行すると、wandbのAPIキー要求されるので入力してください。はじめてwandbを使用する場合はアカウント登録も必要になります。
import weave
# weaveの初期化
weave.init("hello-weave")
(3) 環境変数の準備。
左端の鍵アイコンで「OPENAI_API_KEY」を設定してから、以下のセルを実行してください。

import os
from google.colab import userdata
# 環境変数の準備 (左端の鍵アイコンでOPENAI_API_KEYを設定)
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")(4) Colabでのasyncio利用の有効化。
次のコードを実行することで、Colabノートブックでasyncioを使用した非同期プログラミングが可能になります。
# Colabでのasyncio利用の有効化
import nest_asyncio
nest_asyncio.apply()3. Weaveの基本的な使い方
はじめに、シンプルなコードで、Weaveの基本的な使い方を試してみます。
3-1. 記録
(1) モデルの実装。
今回は、文章からフルーツ情報を抽出するタスクを定義しています。
import json
import openai
# モデルの実装
class ExtractFruitsModel(weave.Model):
model_name: str # モデル名
# 推論
@weave.op()
async def predict(self, sentence: str) -> dict:
# モデルの準備
client = openai.AsyncClient()
# プロンプトテンプレートの準備
prompt_template='Extract fields ("fruit": <str>, "color": <str>, "flavor": <str>) from the following text, as json: {sentence}'
# モデルの呼び出し
response = await client.chat.completions.create(
model=self.model_name,
messages=[
{
"role": "user",
"content": prompt_template.format(sentence=sentence)
}
],
response_format={"type": "json_object"},
)
return response.choices[0].message.content
# return json.loads(response.choices[0].message.content)weave.Modelでモデルを実装します。weave.Modelは、LLMタスクを定義してバージョン管理することで、実験を追跡できるようになります。モデルには、次のものが含まれています。
・weave.Model を継承するクラス
・すべての属性の型定義
・@weave.op()を使用した型付きpredict関数
@weave.op()で任意の関数をラップすると、その関数をバージョン管理し、すべての入出力を記録します。
(2) モデルの準備と実行。
出力結果に、Weaveのサイトへのリンクも出力されます。
import asyncio
# モデルの準備
model = ExtractFruitsModel(
model_name="gpt-3.5-turbo",
)
# モデルの実行
sentence = "真っ赤なリンゴは、かじると甘酸っぱい味が口いっぱいに広がります。"
print(asyncio.run(model.predict(sentence)))
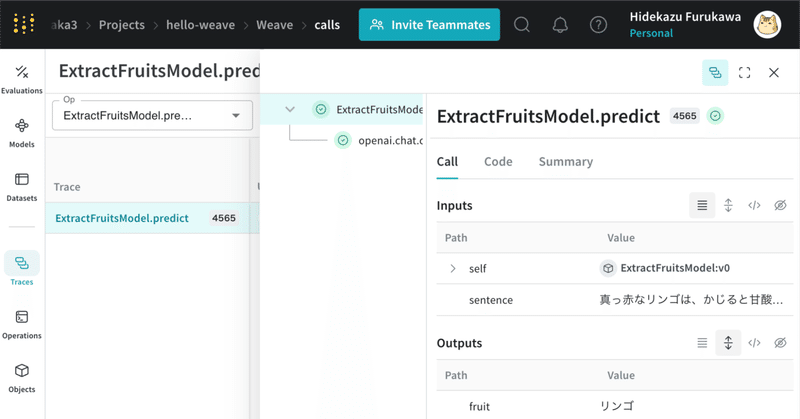
(3) Weaveのサイトへのリンクをクリックして記録を確認。
@weave.op()でラップした関数 (predict()) の入出力が記録されています。openaiの呼び出し (openai.chat.completions.create())は自動的に追跡されます。

3-2. 実験
(1) 別パラメータでのモデルの実行。
「gpt-3.5-turbo」から「gpt-4-turbo」に変更しています。
import asyncio
# モデルの準備
model = ExtractFruitsModel(
model_name="gpt-4-turbo",
)
# モデルの実行
sentence = "真っ赤なリンゴは、かじると甘酸っぱい味が口いっぱいに広がります。"
print(asyncio.run(model.predict(sentence)))
(2) Weaveのサイトへのリンクをクリックして記録を確認。
実験ごとの出力と待ち時間の違いを一覧で確認することができます。
今回は、「真っ赤な」と「赤」の違いがあることがわかります。

3-3. 評価
(1) 評価するモデルの準備。
# モデルの準備
model = ExtractFruitsModel(
model_name="gpt-3.5-turbo",
)(2) データセットの準備。
評価にはテスト用のデータセットが必要です。
今回は、「ID」「入力プロンプト」「正解ラベル」を持つデータセットを準備します。
# 入力プロンプトの準備
sentences = [
"真っ赤なリンゴは、かじると甘酸っぱい味が口いっぱいに広がります。",
"一方、黄色いバナナは、熟すと甘みが増します。",
"最後に、オレンジ色のオレンジは、爽やかな酸味が絶妙です。",
]
# 正解ラベルの準備
labels = [
{"fruit": "リンゴ", "color": "赤", "flavor": "酸っぱい"},
{"fruit": "バナナ", "color": "黄色", "flavor": "甘い"},
{"fruit": "オレンジ", "color": "オレンジ色", "flavor": "爽やかな酸味"}
]
# データセットの準備
examples = [
{"id": "0", "sentence": sentences[0], "target": labels[0]},
{"id": "1", "sentence": sentences[1], "target": labels[1]},
{"id": "2", "sentence": sentences[2], "target": labels[2]}
](3) 評価の実装。
from weave.flow.scorer import MultiTaskBinaryClassificationF1
# フルーツ名のスコアリング関数
@weave.op()
def fruit_name_score(target: dict, model_output: dict) -> dict:
return {"correct": target["fruit"] == model_output["fruit"]}
# 評価の実装
evaluation = weave.Evaluation(
dataset=examples,
scorers=[
MultiTaskBinaryClassificationF1(
class_names=["fruit", "color", "flavor"]
),
fruit_name_score
],
)weave.Evaluationで評価を実装します。weave.Evaluationは、データセットとスコアリング関数を使用して、モデルの性能を評価します。
・dataset : データセット
・scores : スコアリング関数
今回は、次の2つのスコアリング関数を使用しました。
・MultiTaskBinaryClassificationF1 : 二値分類のF1スコア
・fruit_name_score : フルーツ名の正解率
(4) 評価の実行。
# 評価の実行
print(asyncio.run(evaluation.evaluate(model)))
MultiTaskBinaryClassificationF1はflavorは間違いがありますがその他は正解、fruit_name_scoreは全正解であることがわかります。
(5) Weaveのサイトへのリンクをクリックして記録を確認。
より詳細な情報を確認できます。

4. WeaveのRAGでの使い方
次に、シンプルなRAGを構築して、より実践的なWeaveの使い方を試してみます。
4-1. 記録
(1) プロジェクト名の変更。
前プロジェクトと記録を分けるため、プロジェクト名を変更します。
# weaveの初期化
weave.init("rag-qa")(2) ドキュメントの準備。
RAGを行うためのドキュメントを準備しました。
# ドキュメントの準備
documents = [
"OpenAIは、イーロン・マスク氏らが設立した研究機関で、汎用人工知能の開発を目指しています。GPT-4やDALLEなどの言語モデルや画像生成モデルを開発しました。",
"DeepMindは、Google傘下の人工知能研究企業です。強化学習や深層学習の研究で知られ、AlphaGoやAlphaFoldなどの画期的なプロジェクトを手がけています。",
"Anthropicは、「Constitutional AI」という概念を提唱し、安全で倫理的な人工知能の開発を目指すスタートアップです。言語モデルのClaudeを開発しました。",
"Hugging Faceは、自然言語処理に特化したオープンソースのライブラリやモデルを提供するスタートアップです。Transformersライブラリが有名で、多くの研究者や開発者に利用されています。",
"Stability AIは、Stable Diffusionなど高品質な画像生成モデルを開発し、オープンソースで公開することで知られるAIスタートアップです。",
"Cohereは、自然言語処理技術を利用してテキスト生成や理解を可能にするAIモデルを提供する企業です。Command R plusやRerankなどが有名です。"
](3) ドキュメントからの埋め込みの生成。
from openai import OpenAI
# ドキュメントからの埋め込みの生成の関数
def docs_to_embeddings(docs: list) -> list:
openai = OpenAI()
document_embeddings = []
for doc in docs:
response = (
openai.embeddings.create(
input=doc,
model="text-embedding-3-small"
)
.data[0]
.embedding
)
document_embeddings.append(response)
return document_embeddings
# ドキュメントからの埋め込みの生成
docs_embeddings = docs_to_embeddings(documents)(4) 最も関連性の高いドキュメントの取得する関数の準備。
import numpy as np
# 最も関連性の高いドキュメントの取得
@weave.op()
def get_most_relevant_document(query):
# クエリからの埋め込みの生成
openai = OpenAI()
query_embedding = (
openai.embeddings.create(
input=query,
model="text-embedding-3-small"
)
.data[0]
.embedding
)
# 類似評価の実行
similarities = [
np.dot(query_embedding, doc_emb)
/ (np.linalg.norm(query_embedding) * np.linalg.norm(doc_emb))
for doc_emb in docs_embeddings
]
# 類似評価最大のドキュメントを返す
most_relevant_doc_index = np.argmax(similarities)
return documents[most_relevant_doc_index](5) モデルの実装。
RAGを行うpredict()を実装します。入出力は記録されるので、回答(answer)だけでなくコンテキスト(context)も出力しています。
# モデルの実装
class RAGModel(weave.Model):
model_name: str = "gpt-3.5-turbo"
# モデルの呼び出し
@weave.op()
def predict(self, question: str) -> dict:
# 最も関連性の高いドキュメントの取得
context = get_most_relevant_document(question)
# 回答の生成
client = OpenAI()
query = f"""Use the following information to answer the subsequent question. If the answer cannot be found, write "わかりません"
Context:"
Context:
\"\"\"
{context}
\"\"\"
Question: {question}"""
response = client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "user", "content": query},
],
temperature=0.0,
response_format={"type": "text"},
)
answer = response.choices[0].message.content
return {"answer": answer, "context": context}(6) モデルの準備と実行。
# モデルの準備
model = RAGModel(
model_name="gpt-3.5-turbo"
)
# モデルの実行
model.predict("GPT-4を開発したのは?")🍩 https://wandb.ai/npaka3/rag-qa/r/call/XXXXXXXXXXXX
{
'answer': 'OpenAI',
'context': 'OpenAIは、イーロン・マスク氏らが設立した研究機関で、汎用人工知能の開発を目指しています。GPT-4やDALLEなどの言語モデルや画像生成モデルを開発しました。'
}(7) Weaveのサイトへのリンクをクリックして記録を確認。
@weave.op()でラップした関数 (predict()とget_most_relevant_document()) の入出力が記録されています。
質問に応じて取得したドキュメントと回答を確認することができます。

4-2. 実験
(1) ドキュメントに含まれない質問でモデルを実行。
ドキュメントに含まれてないので「わかりません」と答えてくれました。
# ドキュメントに含まれない質問でモデルを実行
model.predict("Windowsを開発したのは?")🍩 https://wandb.ai/npaka3/rag-qa/r/call/XXXXXXXXXXXX
{
'answer': 'わかりません',
'context': 'Anthropicは、「Constitutional AI」という概念を提唱し、安全で倫理的な人工知能の開発を目指すスタートアップです。言語モデルのClaudeを開発しました。'
}(2) 別パラメータでのモデルの実行。
「gpt-3.5-turbo」から「gpt-4-turbo」に変更しています。
# モデルの準備
model = RAGModel(
model_name="gpt-4-turbo"
)
# モデルの実行
model.predict("GPT-4を開発したのは?")🍩 https://wandb.ai/npaka3/rag-qa/r/call/XXXXXXXXXXXX
{
'answer': 'OpenAI',
'context': 'OpenAIは、イーロン・マスク氏らが設立した研究機関で、汎用人工知能の開発を目指しています。GPT-4やDALLEなどの言語モデルや画像生成モデルを開発しました。'
}(3) Weaveのサイトへのリンクをクリックして記録を確認。
「gpt-3.5-turbo」(v0)と「gpt-4-turbo」(v1)を比較すると、待ち時間以外は同じでした。

左上のコンボボックスで関数(今回はpredict())を選択し、カラム名 (今回はquestion)をクリックすることで、同じカラム値ごとでまとめます。パラメータを変更すると別バージョン (v0とv1) になります。
4-3. 評価
(1) 評価するモデルの準備。
# モデルの準備
model = RAGModel(
model_name="gpt-3.5-turbo"
)(2) コンテキスト精度スコアを計算する関数の準備。
GPT-4にコンテキストが回答に到達するのに役立つかどうかを 0 or 1 で採点してもらいます。
from openai import OpenAI
import weave
import asyncio
import json
# コンテキスト精度スコアの計算
@weave.op()
async def context_precision_score(question, model_output):
context_precision_prompt = """Given question, answer and context verify if the context was useful in arriving at the given answer.
Give verdict as {{verification: 1}} if useful and {{verification: 0}} if not with json output.
Output in only valid JSON format.
question: {question}
context: {context}
answer: {answer}
"""
client = OpenAI()
prompt = context_precision_prompt.format(
question=question,
context=model_output["context"],
answer=model_output["answer"],
)
response = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[{"role": "user", "content": prompt}],
response_format={ "type": "json_object" }
)
response_message = response.choices[0].message
response = json.loads(response_message.content)
return {
"verdict": int(response["verification"]) == 1,
}(3) 質問の準備。
# 質問の準備
questions = [
{"question": "GPT-3を開発したのは?"},
{"question": "Google傘下の人工知能研究企業は?"},
{"question": "「Constitutional AI」という理念を提唱しているのは?"},
{"question": "Hugging Faceが開発したライブラリは?"},
{"question": "Stable Diffusionで有名なスタートアップは?"},
{"question": "Cohereはどんな会社?"}
](4) 評価の実装。
import asyncio
# 評価の実行
evaluation = weave.Evaluation(
dataset=questions,
scorers=[context_precision_score]
)(5) 評価の実行。
asyncio.run(evaluation.evaluate(model))Evaluated 1 of 6 examples
Evaluated 2 of 6 examples
Evaluated 3 of 6 examples
Evaluated 4 of 6 examples
Evaluated 5 of 6 examples
Evaluated 6 of 6 examples
Evaluation summary
{
'context_precision_score': {
'verdict': {
'true_count': 6,
'true_fraction': 1.0
}
},
'model_latency': {
'mean': 3.3273427486419678
}
}
🍩 https://wandb.ai/npaka3/rag-qa/r/call/XXXXXXXXXXXX
{
'context_precision_score': {
'verdict': {
'true_count': 6,
'true_fraction': 1.0
}
},
'model_latency': {
'mean': 3.3273427486419678
}
}(6) 同様に、「gpt-4-turbo」に対して評価を実行。
# モデルの準備
model = RAGModel(
model_name="gpt-4-turbo"
)
# 評価の実行
asyncio.run(evaluation.evaluate(model))(7) Weaveのサイトへのリンクをクリックして記録を確認。
たまたまと思いますが、「gpt-3.5-turbo」が満点なのに対して、「gpt-4-turbo」は1つミスしました。

中身を確認してみると、1つ「わかりません」と答えていたことがわかります。

この記事が気に入ったらサポートをしてみませんか?