
DPO によるLLMのPreferenceチューニング

以下の記事が面白かったので、かるくまとめました。
・Preference Tuning LLMs with Direct Preference Optimization Methods
1. 強化学習を使用しないアライメント
この記事では、「DPO」(Direct Preference Optimization)、「IPO」(Identity Preference Optimization)、「KTO」(Kahneman-Taversky Optimization) という3つの有望なLLMアライメントアルゴリズムの評価を行います。
「DPO」はLLMを人間またはAIの好みに合わせるための有望な代替手段として浮上しています。「強化学習」に基づく従来のアライメントアルゴリズムとは異なり、「DPO」はアライメントの定式化を、嗜好のデータセット上で直接最適化できる単純な損失関数として再構成します。
これにより、「DPO」は使いやすくなり、「Zephyr」や「NeuralChat」などのモデルの学習で成功しています。
「DPO」の成功により、研究者たちは2つの主要な方向でアルゴリズムを一般化する新しい損失関数を開発するようになりました。
・堅牢性
「DPO」の欠点の1つは、優先データセットにすぐに過剰適合する傾向があることです。これを回避するために、「Google DeepMind」は「IPO」を導入しました。これにより、「DPO」損失に正則化項が追加され、早期停止などのトリックを必要とせずにモデルを収束するように学習できるようになります。
・ペアのPreferenceデータを完全に不要にする
ほとんどのアライメントアルゴリズムと同様、「DPO」はペアのPreferenceデータセットを必要とし、アノテーターは有用性や有害性といった基準に従って、どちらの回答がより良いかをラベル付けします。このようなデータセットの作成には時間とコストがかかります。ContextualAIは最近、「KTO」と呼ばれる興味深い代替案を提案しました。これは、「good」または「bad」とラベル付けされた個々の例に関して損失関数を完全に定義するものです。これらのラベルは取得するのがはるかに簡単であり、「KTO」は本番環境で実行されているチャットモデルを継続的に更新する有望な方法になります。
同時に、これらの様々な方法にはハイパーパラメータが付属しています。最も重要なものは β で、参照モデルの優先度をどの程度重み付けするかを制御します。
2. 実験内容
β および学習ステップを実行し、チャットモデルの機能を測定するための一般的なベンチマークである「MT-Bench」を介して結果のモデルのパフォーマンスを評価します。
モデルは以下の2つを選択しました。
データセットは以下の2つを選択しました。
3. 実験結果
3-1. Zephyr-7b-beta-SFT
「Zephyr」では、β「0.01」の最低条件で最高のパフォーマンスが達成されることが観察されました。テストした 3 つのアルゴリズムすべてで一貫しています。「DPO」は「MT-Bench」で最高スコアを達成できますが、「KTO」は1つの設定を除くすべての設定でより良い結果を達成することがわかりました。「IPO」はより強力な理論的保証を持っていますが、1つの設定を除いてすべての設定で基本モデルよりも悪いようです。
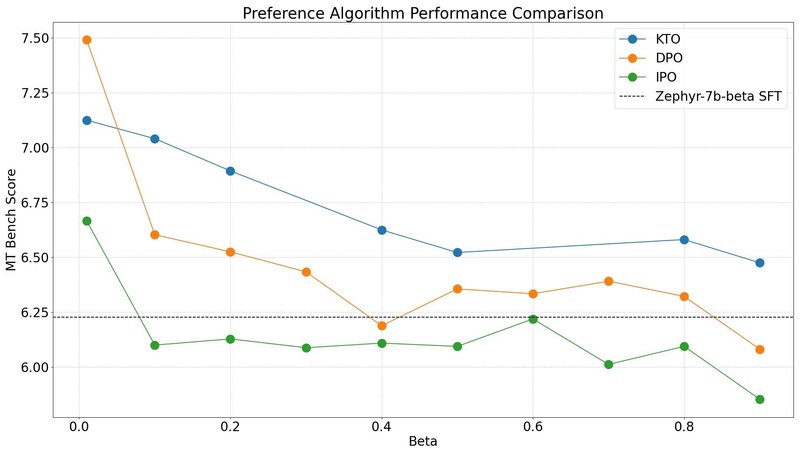
「MT-Bench」が評価するカテゴリ全体で各アルゴリズムの最良の結果を分析して、これらのモデルの長所と短所を特定できます。推論、コーディング、数学の軸には、まだ改善の余地があります。

3-2. OpenHermes-7b-2.5
各アルゴリズムに関する観察結果は DPO > KTO > IPO という点が同じです。βはアルゴリズムごとに大きく異なり、最良は DPO、KTO、IPO で 0.6、0.3、0.01 になりました。

「OpenHermes-7b-2.5」は強力なベースモデルであり、Preferenceチューニング後の「MT-Bench」のスコア改善はわずか 0.3 でした。

3-3. 洞察
「DPO」が「KTO」を上回るパフォーマンスを実証しましたが、「IPO」 はより強力な理論的保証にもかかわらずパフォーマンスが精彩を欠いているようです。
これらの結果を複製するすべてのコードと構成ファイルは、「alignment-handbook」で入手できます。
4. 今後の取り組み
「TRL」に新しいPreferenceチューニングアルゴリズムを実装し、そのパフォーマンスを評価する作業を続けます。少なくとも当面は、「DPO」が最も堅牢でパフォーマンスの高いLLMアライメントアルゴリズムであると思われます。「DPO」と「IPO」の両方がペアの選好データを必要とするのに対し、「KTO」は応答がgoodまたはbadに評価される任意のデータセットに適用できるため、「KTO」は引き続き興味深いアルゴリズムです。
この記事が気に入ったらサポートをしてみませんか?