
TensorFlow 3Dによる3Dシーン理解

以下の記事を参考に書いてます。
・3D Scene Understanding with TensorFlow 3D
1. TensorFlow 3D
近年、3Dセンサー(Lidar、深度検知カメラ、レーダーなど)の普及が進んでいます。それに伴い、3Dキャプチャしたデータを処理するための「3Dシーン理解」(3D scene understanding)のニーズも高まっています。
これら技術は、モバイルによるAR体験の向上に役立ちます。モバイルのコンピュータビジョンは、「3D物体検出」「透明物体検出」など「3Dシーン理解」において順調に進歩していますが、利用可能なツールとリソースが限られているため、この分野への参入は困難な場合が多いです。
そこで私たちは、「3Dシーン理解」をさらに向上させ、関心ある研究者の参入障壁を減らすために、3Dの深層学習をTensorFlowに組み込んだ「TensorFlow 3D」(TF3D)をリリースしました。「TF3D」は、一般的なオペレーション、損失関数、データ処理ツール、モデル、メトリックのセットを提供します。これにより、様々な研究コミュニティで、最先端の「3Dシーン理解」のモデルの開発、学習、およびデプロイが可能になります。
「TF3D」には、分散学習をサポートする、最先端の「3Dセマンティックセグメンテーション」「3Dインスタンスセグメンテーション」「3D物体検出」の学習・評価パイプラインが含まれています。また、「3D物体の形状予測」「点群の登録」「点群の高密度化」など、他の潜在的アプリも可能にします。さらに、標準的な「3Dシーン理解」のデータセットの学習・評価のための、「統一データセット仕様」も提供します。
現在、「Waymo Open」「ScanNet」「Rio」のデータセットをサポートしています。ただし、ユーザーは「NuScenes」や「Kitti」などの他の一般的なデータセットを、同様の形式に変換して利用することも可能です。

「Waymo Open」を使った「3D物体検出」モデルの出力例を左、「ScanNet」を使った「3Dインスタンスセグメンテーション」モデルの出力例を右に示します。
2. 3Dスパース畳み込みネットワーク
センサーによってキャプチャされた3Dデータは、多くの場合、関心のある物体のセット(車、歩行者など)を含むシーンで構成されます。そのため、3Dデータは本質的にまばらです。このような環境では、畳み込みの標準的な実装は計算量が多く、大量のメモリを消費します。そのため、「TF3D」では、3Dスパースデータをより効率的に処理するように設計された「スパース畳み込み」および「プーリング」を使用します。「スパース畳み込みモデル」は、ほとんどの屋外自動運転(Waymo、NuScenesなど)および屋内ベンチマーク(ScanNetなど)に適用される、最先端の方法の中核です。
また、CUDAのハッシュ、共有メモリでのフィルタのパーティション化/キャッシュ、ビット演算などの手法によって、計算を高速化しています。「Waymo Open」での実験によると、既存のTensorFlowオペレーションで適切に設計された実装よりも約20倍高速です。
次に「TF3D」は、「U-Net」アーキテクチャを使用して、各ボクセルの特徴を抽出します。「U-Net」アーキテクチャは、ネットワークに粗い特徴と細かい特徴の両方を抽出させ、それらを組み合わせて予測を行うことにより、効果的であることが証明されています。「U-Net」ネットワークは、エンコーダー、ボトルネック、デコーダーの3つのモジュールで構成され、各モジュールは、プールまたはアンプールが可能な多数のスパース畳み込みブロックで構成されます。
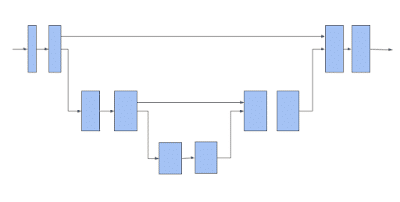
3DスパースボクセルU-Netアーキテクチャ。水平矢印はボクセル特徴を取り込み、部分多様体のスパース畳み込みを適用することに注意してください。下に移動している矢印は、部分多様体のスパースプーリングを実行します。 上に移動する矢印は、プールされた特徴を収集し、それらを水平矢印からの特徴と連結し、連結された特徴に対して部分多様体のスパース畳み込みを実行します。
上記のスパース畳み込みネットワークは、「TF3D」で提供される3Dシーン理解パイプラインのバックボーンです。以下で説明する各モデルは、このバックボーンを使用してスパースボクセルの特徴を抽出し、1つまたは複数の追加の予測ヘッドを追加して対象のタスクを推測します。ユーザーは、エンコーダー/デコーダーレイヤーの数と各レイヤーの畳み込みの数を変更し、畳み込みフィルタのサイズを変更することで「U-Net」ネットワークを構成できます。これにより、様々な速度と精度のトレードオフを検討できます。
3. 3Dセマンティックセグメンテーション
「3Dセマンティックセグメンテーション」のモデルには、ボクセルごとのセマンティックスコアを予測するための出力ヘッドが1つだけあります。これらのスコアはポイントにマッピングされ、ポイントごとのセマンティックラベルを予測します。

「ScanNet」データセットからの屋内シーンの3Dセマンティックセグメンテーション。
4. 3Dインスタンスセグメンテーション
「3Dインスタンスセグメンテーション」では、セマンティクスの予測に加えて、同じオブジェクトに属するボクセルをグループ化することが目標です。「TF3D」で使用される3Dインスタンスセグメンテーションのアルゴリズムは、ディープメトリック学習を使用した2D画像セグメンテーションに関する以前の作業に基づいています。モデルは、ボクセルごとのインスタンス埋め込みベクトルと、各ボクセルのセマンティックスコアを予測します。インスタンス埋め込みベクトルは、ボクセルを埋め込みスペースにマップします。埋め込みスペースでは、同じオブジェクトインスタンスに対応するボクセルは互いに近く、異なるオブジェクトに対応するボクセルは遠く離れています。この場合、入力は画像ではなく点群であり、2D画像ネットワークではなく3Dスパースネットワークを使用します。推論時に、Greedyアルゴリズムは一度に1つのインスタンスシードを選択し、ボクセル埋め込み間の距離を使用してそれらをセグメントにグループ化します。
5. 3D物体検出
「3D物体検出」のモデルは、ボクセルごとのサイズ、中心、回転行列、およびオブジェクトのセマンティックスコアを予測します。推論時に、ボックス提案メカニズムを使用して、数十万のボクセルごとのボックス予測をいくつかの正確なボックス提案に減らし、学習時に、ボックス予測と分類損失をボクセルごとの予測に適用します。予測ボックスのコーナーとグラウンドトゥルースボックスのコーナーの間の距離にHuber損失を適用します。サイズ、中心、回転行列からボックスの角を推定する関数は微分可能であるため、損失は自動的にそれらの予測されたオブジェクトのプロパティに伝播します。グラウンドトゥルースと強くオーバーラップするボックスをポジティブとして分類し、オーバーラップしないボックスをネガティブとして分類する動的ボックス分類損失を使用します。

ScanNetデータセットでの3Dオブジェクト検出結果。
最近の論文「DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes」では、「TF3D」での物体検出に使用される単一ステージの弱教師あり学習アルゴリズムについて詳しく説明します。さらに、フォローアップ作業では、スパースLSTMベースのマルチフレームモデルを提案することにより、時間情報を活用するために3D物体検出モデルを拡張しました。さらに、この時間モデルが「Waymo Open」でフレームごとのアプローチを7.5%上回っていることを示します。
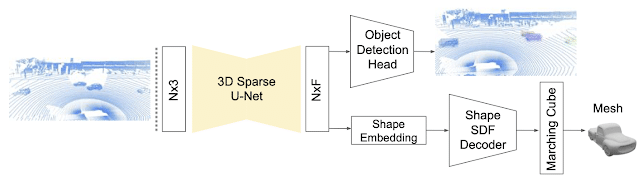
DOPSの論文で紹介された3D物体検出および形状予測モデル。3DスパースU-Netを使用して、各ボクセルの特徴ベクトルを抽出します。物体検出モジュールは、これらの機能を使用して3Dボックスとセマンティックスコアを提案します。同時に、ネットワークの他のブランチは、各オブジェクトのメッシュを出力するために使用される形状の埋め込みを予測します。
この記事が気に入ったらサポートをしてみませんか?