Google Colab で Xwin-LM-70B-V0.1-GPTQ を試す。

「Google Colab」で「Xwin-LM-70B-V0.1-GPTQ」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で70Bを動作確認しています。
1. Xwin-LM-70B-V0.1-GPTQ
「Xwin-LM」は、ベンチマーク「AlpacaEval」で「GPT-4」を追い抜き1位を獲得したモデルです。
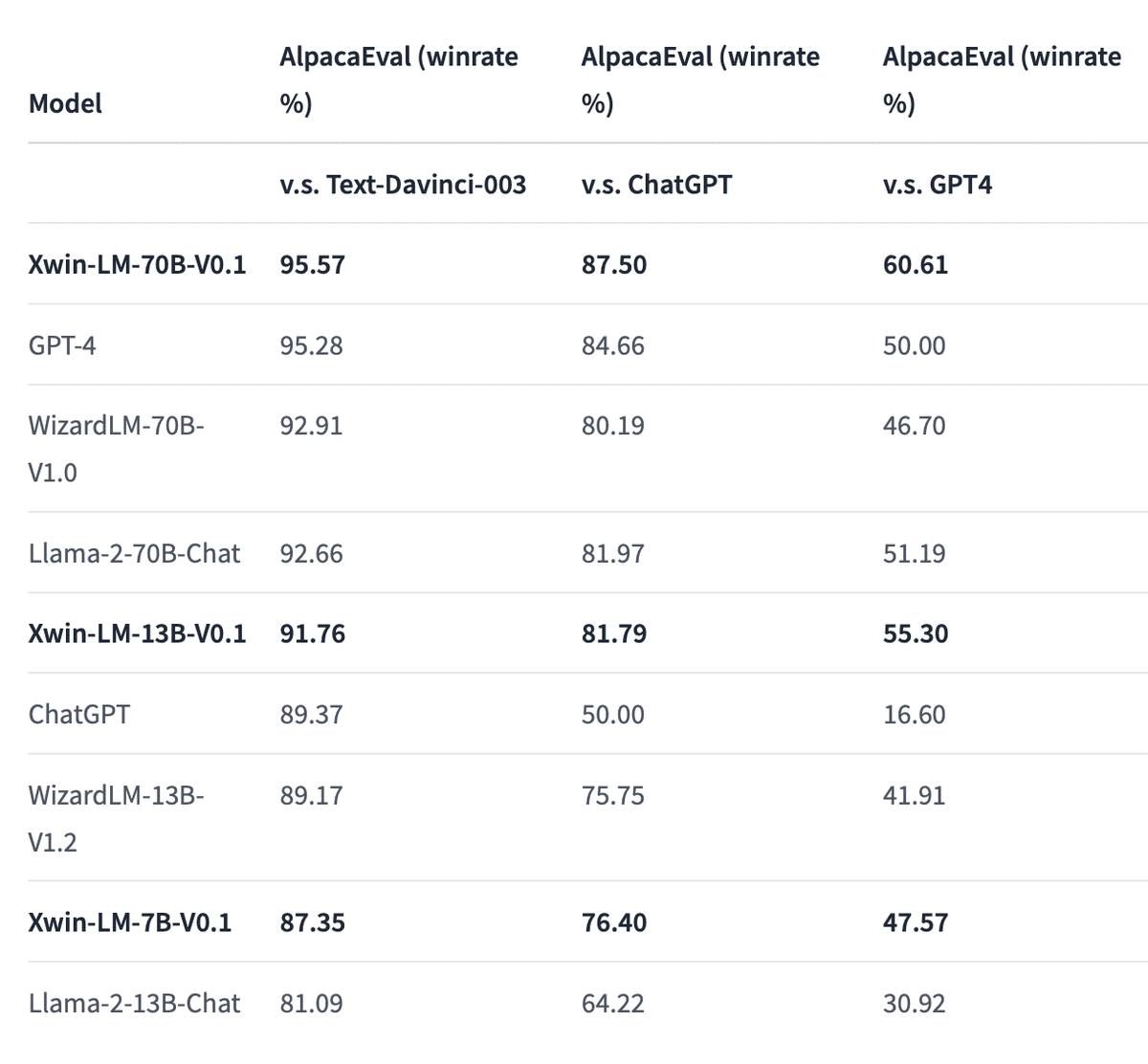
今回は、「TheBloke/Xwin-LM-70B-V0.1-GPTQ」を利用します。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
GPTQを利用するため、「auto-gptq 」もインストールしています。
# パッケージのインストール
!pip install transformers>=4.32.0 optimum>=1.12.0
!pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7(3) トークナイザーとモデルの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"TheBloke/Xwin-LM-70B-V0.1-GPTQ",
use_fast=True
)
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Xwin-LM-70B-V0.1-GPTQ",
device_map="auto",
trust_remote_code=False,
revision="main"
)(4) 質問応答。
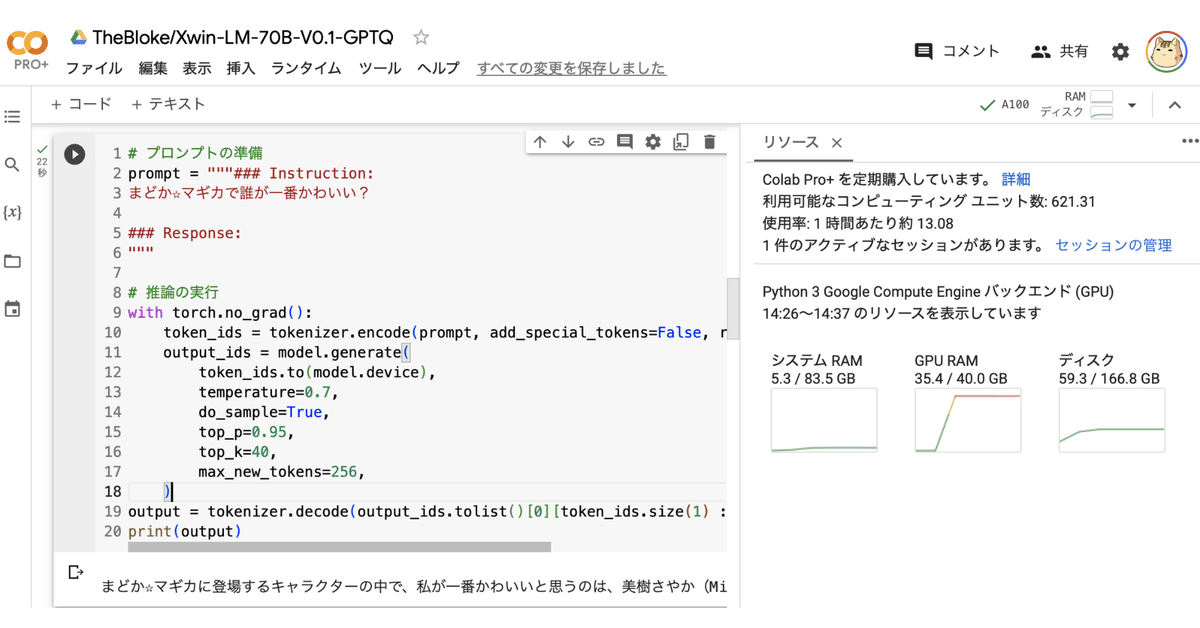
# プロンプトの準備
prompt = """### Instruction:
まどか☆マギカで誰が一番かわいい?
### Response:
"""
# 推論の実行
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
temperature=0.7,
do_sample=True,
top_p=0.95,
top_k=40,
max_new_tokens=256,
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)まどか☆マギカに登場するキャラクターの中で、私が一番かわいいと思うのは、美樹さやか(Miki Sayaka)です。彼女は魔法少女になることを目指し、強い意志と優しさを持っています。また、彼女のキャラクターデザインが独特で、他のキャラクターに比べてかわいいと感じます。ただし、この見解は個人的な好みに基づいたものであり、他のファンが異なる意見を持っていることを理解しています。
この記事が気に入ったらサポートをしてみませんか?