
マルコフ決定過程とベルマン方程式

1. マルコフ決定過程
「マルコフ決定過程」(MDP)は、「環境」を表す「数理モデル」です。「数理モデル」は、現実の世界で起きるさまざまな問題を方程式などの数学的な形で表現することになります。
強化学習の「環境」を図で表すと、次のようになります。「次の状態」(St+1)は、現在の「状態」(St)と「行動」(At)によって確定します。
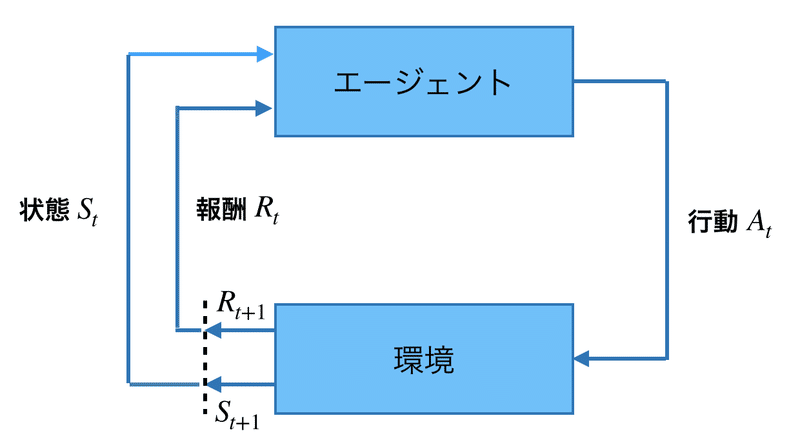
これを数式で表現したものが「マルコフ決定過程」になります。そしてその数式を使って、もらえる報酬が最大になる「方策」を得ることが強化学習の目的になります。
2. マルコフ決定過程の構成要素
「マルコフ決定過程」は、「状態」「行動」「遷移確率」「報酬」の4つの構成要素で構成されます。
◎状態
s ∈ S = {s1, s2, …, sn}全てのとりうる「状態」を集めたものが「S」です。Atariゲームでは、画面イメージが「状態」になります。
◎行動
a ∈ A = {a1, a2, …, an}全てのとりうる「行動」を集めたものが「A」です。Atariゲームでは、上下左右とFireボタンなどが「行動」になります。
◎遷移確率
P(s'|s,a)状態「s」において行動「a」をとって次の状態「s'」になる遷移確率を「P(s,a,s')」で表現します。Atariゲームで、ゲーム開始前にFireを押すことで1(100%)の確率でゲーム開始に遷移することを、P(s,a,s')=1と表記します。
◎報酬
R(s,a,s')状態「s」において行動「a」をとって次の状態「s'」になった時の「報酬」を「R(s,a,s′)」で表現します。Atariゲームでは、敵を倒した時に報酬1をもらうことを、R(s,a,s')=1と表記します。
3. 方策
π(s,a)「方策」(ポリシー)とは、各状態にいるときに、どのような行動をとるのかを表す規則です。例えば、状態「s1」にいる時には行動「a1」をとる、状態「s2」にいる時には行動「a2」とる、という規則です。方策「π」の元に状態「s」において行動「a」を選択する確率を「π(s,a)」で表現します。
「行動」に応じて「次の状態」が1つに決まっている(状態遷移確率が常に1)方策を「決定論的方策」と呼びます。そうでない方策を「確率論的方策」と呼びます。
4. 収益
「強化学習」では、即時報酬だけでなく、あとで発生するすべての遅延報酬を含めた報酬和を最大化することが求められます。これを「収益」と呼びます。

エージェントの考え方によって収益の計算式は変わってきます。未来の報酬を割引いた「割引報酬和」は、収益の計算によく使われます。

5. 価値関数
価値関数には、「状態価値関数」と「行動価値関数」の2種類があります。
◎状態価値関数
状態「s」にいることの価値を計算する関数です。

◎行動価値関数
状態「s」にいて行動「a」を取る価値を計算する関数です。

6. ベルマン方程式
強化学習の目的は、価値関数「v_π(s)」を全ての状態「s」において最大化する「方策」を見つけることです。これを効率的に計算するには、価値関数を再帰的に計算する必要があります。これには、ある状態「s」における価値関数を、次の状態「s'」と関連づける方程式が必要になります。この方程式を「ベルマン方程式」と呼びます。
◎状態価値関数のベルマン方程式
「状態価値関数のベルマン方程式」は次のとおりです。

◎行動価値関数のベルマン方程式
「行動価値関数のベルマン方程式」は次のとおりです。

7. 行動価値関数の更新式
「行動価値関数」を更新式には、「Sarsa」と「Q学習」があります。
◎Sarsaの更新式
「Sarsaの更新式」は次のとおりです。「Rt+1+γ*Q(st+1,at+1)-Qπ(st,at)」は、予測した行動価値と正しい行動価値の差分「TD誤差」で、予測の制度が高いほど0に近くなります。

◎Q学習の更新式
「Q学習の更新式」は次のとおりです。「Rt+1+γ*max Q(st+1,a)-Qπ(st,at)」は、予測した行動価値と正しい行動価値の差分「TD誤差」で、予測の制度が高いほど0に近くなります。

これら更新式によって「経験」から「行動価値」を計算できるようになります。これを使って、行動価値の高い行動を選ぶことで、もらえる報酬が最大になる「方策」を得ることができます。
この記事が気に入ったらサポートをしてみませんか?