Stable Diffusion と Google Colab によるテキストからのテクスチャ生成

「Stable Diffusion」と「Google Colab」によるテキストからのテクスチャ生成の方法をまとめました。
・Stable Diffusion v1.4
・diffuser v4.1
1. Stable Diffusion
「Stable Diffusion」は、テキストから画像を生成する、高性能な画像生成AIです。
2. ライセンスの確認
以下のサイトでライセンスを確認し、「Access Repository」を押し、「HuggingFace」にログインして(アカウントがない場合は作成)、同意します。
3. テクスチャの生成
テクスチャの生成手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」に「GPU」を選択。
(2) 「Stable Diffusion」のインストール。
# パッケージのインストール
!pip install --upgrade diffusers==0.4.1 transformers scipy(3) HuggingFaceにログイン。
リンク先のHuggingFaceのトークンをコピーして、テキストボックスに入力して、Loginボタンを押します。
# HuggingFaceにログイン
from huggingface_hub import notebook_login
notebook_login()(4) シームレスなテクスチャを作成するための設定。
以下のコードを実行することで、シームレスな (上下・左右がつながっている) テクスチャを作成できるようになります。
import torch
def patch_conv(cls):
init = cls.__init__
def __init__(self, *args, **kwargs):
return init(self, *args, **kwargs, padding_mode='circular')
cls.__init__ = __init__
patch_conv(torch.nn.Conv2d)(5) 「Stable Diffusion」パイプラインの準備。
from diffusers import StableDiffusionPipeline
# StableDiffusionパイプラインの準備
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4"
).to("cuda")(6) テクスチャの生成の実行。
from torch import autocast
# テキストからのテクスチャ生成
prompt = "green ground texture"
with autocast("cuda"):
images = pipe(prompt).images
images[0].save("output.png")(7) 生成した画像の確認。
左端のフォルダアイコンでファイル一覧を表示し、output.pngをダブルクリックします。

512x512のテクスチャが生成されます。
解像度が足りないときは、「Real-ESRGAN」で画像の解像度をアップコンバートすることもできます。
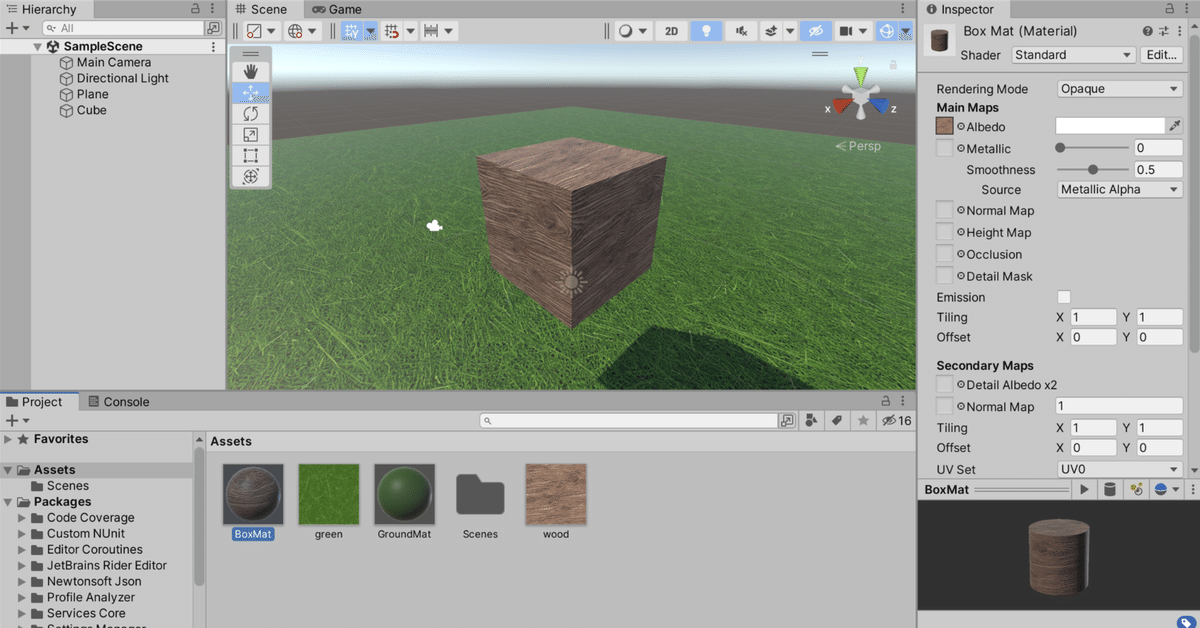
4. Unityでのテクスチャ画像の配置
Unityでテクスチャ画像を配置する手順は、以下のようになります。
(1) UnityプロジェクトのAssetsにテクスチャ画像を配置。
(2) Materialを作成して、Albedoに追加したテクスチャを指定し、Tilingにリピート回数を指定。

(3) 3DオブジェクトのMeshRendererのMaterialsに作成したMaterialを指定。

配置結果は、次のようになります。
・green ground texture
・wood plank texture

"CompVis/stable-diffusion-v1-4" を "hakurei/waifu-diffusion" に変更することで、「Waifu Diffusion」のモデルでテクスチャを作成することもできます。
・cute hatsune miku wallpaper
・cute floral wallpaper

5. 参考
この記事が気に入ったらサポートをしてみませんか?