
HuggingFace での Llama 2 の使い方

以下の記事が面白かったので、軽くまとめました。
1. Llama 2
「Llama 2」は、Metaが開発した、7B・13B・70B パラメータのLLMです。
長いコンテキスト長 (4,000トークン) や、70B モデルの高速推論のためのグループ化されたクエリアテンションなど、「Llama 1」と比べて大幅な改善が加えられています。
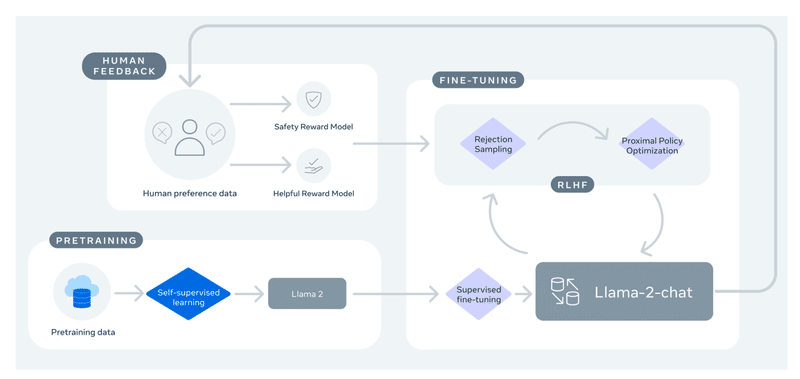
そして、このリリースの最もエキサイティングな部分は、「RLHF」を使用して対話用に最適化されたモデル「Llama 2-Chat」です。 有用性と安全性の幅広いベンチマークにおいて、「Llama 2-Chat」ほとんどのオープンモデルよりも優れたパフォーマンスを示し、人間の評価によるとChatGPTと同等のパフォーマンスを達成しています。
2. デモ
以下のスペースで、「Llama 2」 (70B) を簡単に試すことができます。
3. 推論
「Llama2」の推論には様々な方法があります。
3-1. 利用申請
これらのモデルを使用する前に、「Meta Llama 2」リポジトリ内の使用するモデルへの利用申請していることを確認してください。公式のMetaのフォームにも必ず記入してください。両方のフォームに入力すると、 数時間後にリポジトリへのアクセスが許可されます。
3-2. transformers での使い方
「transformers v4.31」では、すでに「Llama 2」を使用できます。
・学習および推論のスクリプトと例
・セーフファイル形式 (safetensors)
・bitsandbytes (4bit量子化) や PEFT との統合
・ユーティリティとヘルパー
・デプロイ
最新の「transformers」を使用し、HuggingFace アカウントにログインしてください。
pip install transformers
huggingface-cli login「transformers」による推論の例は、次のとおりです。
from transformers import AutoTokenizer
import transformers
import torch
model = "llamaste/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, explモデルにはコンテキストのトークンが4Kしかありませんが、rotary position embedding scaling (tweet) などのtransformersでサポートされているテクニックを使用することで、モデルをさらに推し進めることができます。
3-3. Text Gneration Inference と Inference Endpoints での使い方
「Text Generation Inference」 は、HuggingFace によって開発された実稼働用の推論コンテナです。LLMを簡単にデプロイできます。 連続バッチ処理、トークン ストリーミング、複数のGPU での高速推論のためのTensor並列処理、本番環境に対応したロギングとトレースなどの機能を備えています。
独自のインフラで「Text Gneration Inference」を試すことも、Hugging Face の「Inference Endpoints」を使用することもできます。「Llama 2」をデプロイするには、model pageに移動し、Deploy -> Inference Endpoints ウィジェットをクリックします。
・7B モデル : "GPU [medium] - 1x Nvidia A10G" 推奨
・13B モデル : "GPU [xlarge] - 1x Nvidia A100" 推奨
・70B モデル : "GPU [xxlarge] - 8x Nvidia A100" 推奨
注: A100 にアクセスするには、メールで api-enterprise@huggingface.co にquota upgrade をリクエストする必要があります。
3-4. PEFTによるファインチューニング
HuggingFaceエコシステムで利用できるツールを使うことで、単一の NVIDIA T4 (16GB - Google Colab) で「Llama 2」の 7B をファインチューニングすることができます。詳しくは、「Making LLMs even more accessible blog」を参照してください。
「QLoRA」と「SFTTrainer」(trl)を使用して「Llama 2」の指示チューニングするスクリプトも提供されています。
「timdettmers/openassistant-guanaco」で 「Llama 2 7B」 をファインチューニングるコマンドの例を以下に示します。 スクリプトは、merge_and_push 引数を指定することで、LoRA の重みをモデルの重みにマージし、それらを safetensor の重みとして保存できます。
python finetune_llama_v2.py \
--model_name llamaste/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--use_4bit \
--merge_and_push4. 追加リソース
・HuggingFace Hub - Llama 2 モデル
・Leaderboard
・Llamaモデルのコード例とレシピ
この記事が気に入ったらサポートをしてみませんか?