Google Colab で Llama 3 を試す

「Google Colab」で「Llama 3」を試したので、まとめました。
1. Llama 3
「Llama 3」は、Metaが開発したオープンモデルです。

2. Llama 3 のモデル
「Llama 3」では現在、次の4種類のモデルが提供されています。
・meta-llama/Meta-Llama-3-8B
・meta-llama/Meta-Llama-3-8B-Instruct
・meta-llama/Meta-Llama-3-70B
・meta-llama/Meta-Llama-3-70B-Instruct
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install -U transformers accelerate bitsandbytes(2) モデルカードで利用許諾。

(3) 「HuggingFace」からAPIキーを取得し、Colabのシークレットマネージャーの「HF_TOKEN」に登録。

(4) トークナイザーとモデルの準備。
今回は、「meta-llama/Meta-Llama-3-8B-Instruct」を使います。
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct"
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
device_map="auto",
torch_dtype="auto",
)(3) 推論の実行。
モデルカードの指示に従って eos_token_id を付加してます。
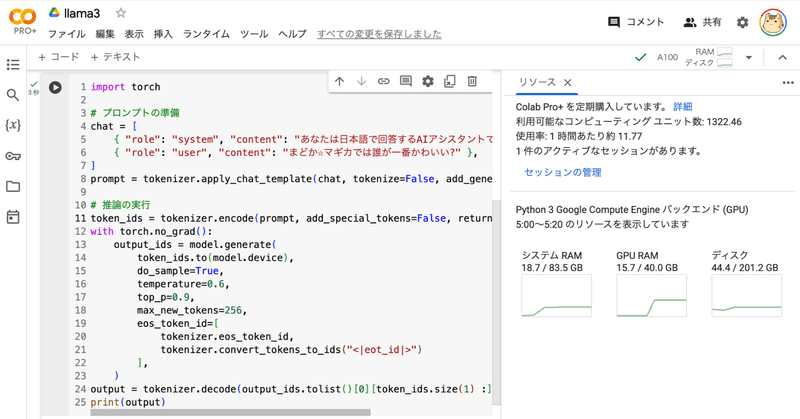
import torch
# プロンプトの準備
chat = [
{ "role": "system", "content": "あなたは日本語で回答するAIアシスタントです。" },
{ "role": "user", "content": "まどか☆マギカでは誰が一番かわいい?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=256,
eos_token_id=[
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
],
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)まどか☆マギカ(Madoka Magica)では、キャラクターの可愛さは個人的な好みによるが、人気投票では、Homura Akemiが一番かわいいと評価されることが多いです。
Homuraは、物語の進行に影響を与える重要なキャラクターであり、同時に彼女のキャラクター設定やデザインも非常に人気があります。彼女の冷静な性格や、魔法少女としての能力、また彼女の過去や秘密も、ファンの心を掴む要因となっています。
ただし、他のキャラクターも非常に可愛く、ファンの間では、Madoka、Sayaka、Mami、Kyouko、Kyubeyなど各キャラクターが人気を博しています。
この記事が気に入ったらサポートをしてみませんか?