
GCP 入門 (1) - Speech-to-Text

「GCP」(Google Cloud Platform)の「Speech-to-Text」で文字起こしを作る方法をまとめました。
・macOS 10.15.7
・Python 3.6
1. Speech-to-Text
「Speech-to-Text」は、音声をテキストに変換するAPIです。
主なタスクは、次のとおりです。
・同期音声認識 (1分)
ローカル・リモートの短い音声ファイルをテキストに変換。
・非同期音声認識 (480分)
リモートの長い音声ファイルをテキストに変換
・ストリーミング音声認識 (5分)
ローカル音声ファイル・音声ストリームをテキストに変換。
・無限ストリーミング音声認識
無限の音声ストリームをテキストに変換。
料金は、次のとおりです。
APIは「REST」と「RPC」が提供されています。
・REST
・RPC
2. プロジェクトの作成とAPIの有効化
(1) GCPの「Google Cloud Console」を開く。
(2) トップ画面上端の「プロジェクト名」から新規プロジェクトを作成。
(3) トップ画面上端の「検索ボックス」で「Speech-to-Text」を検索し、「有効にする」ボタンを押す。
3. サービスアカウントキーの作成
(1) 「Cloud Console」のメニュー「APIとサービス」を開く。
(2) 「認証情報 → 認証情報を作成 → ウィザードで選択」を選択。
(3) 「1. 必要な認証情報の種類を調べる」で、以下を設定し、「必要な認証情報」ボタンを押す。
・使用するAPI : Cloud Speech-to-Text API
・"App Engine または Compute Engine でこの API を使用する予定はありますか?" : いいえ
(4) 「2. 認証情報を取得する」で、以下を設定し、「次へ」ボタンを押す。
・サービスアカウント名 : test
・ロール : Project → オーナー ※ どのリソースにアクセスできるかに影響
・キーのタイプ : JSON
成功すると、 「サービスアカウントキー」(JSONファイル)がダウンロードされます。このファイルを読み込むことで、「Speech-to-Text」のAPIを利用できるようになります。
【用語】「サービスアカウント」は個人ではなくアプリやVMに属する特別なアカウントです。サービスアカウントのキーペアを持ち、Googleの認証に使用します。
・GCP Service Accountを理解する
4. Pythonの開発環境の準備
(1)「Python3.6」の仮想環境の作成。
(2) 「クライアントライブラリ」のインストール。
$ pip install --upgrade google-cloud-speech(3) サービスアカウントキーの登録。
$ export GOOGLE_APPLICATION_CREDENTIALS="[サービスアカウントキーのパス]"(4) 「pyaudio」のインストール。
Pythonでのマイク制御に必要なパッケージになります。
$ brew install portaudio
$ pip install pyaudio5. 音声ファイルをテキストに変換
はじめに練習として、音声ファイルをテキストに変換するスクリプトを作成します。
【quickstart.py】
import io
import os
from google.cloud import speech
# クライアントの生成
client = speech.SpeechClient()
# 音声ファイル名の生成
file_name = os.path.join(os.path.dirname(__file__), "resources", "audio.raw")
# 音声ファイルの読み込み
with io.open(file_name, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
# 音声ファイルをテキストに変換
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
response = client.recognize(config=config, audio=audio)
# 出力
for result in response.results:
print("Transcript: {}".format(result.alternatives[0].transcript))【resources/audio.raw】
githubで取得できます。
実行結果は、次のとおりです。
$ python quickstart.py
Transcript: how old is the Brooklyn Bridge6. 文字起こしの作成
次に本題の、文字起こしを行うスクリプトを作成します。「無限ストリーミング音声認識」の公式サンプル「transcribe_streaming_infinite.py」をカスタマイズして作ります。
(1) スクリプトの先頭近くに、ファイル名の定数「FILE_NAME」を追加。
# ファイル名
import datetime
now = datetime.datetime.now()
FILE_NAME = './output/log_' + now.strftime('%Y%m%d_%H%M%S') + '.txt'(2) 「セリフ入力中」「セリフ確定」の標準出力を変更し、「セリフ確定」にファイル出力を追加。
if result.is_final:
sys.stdout.write(GREEN)
sys.stdout.write("\033[K")
sys.stdout.write(str(corrected_time) + ": " + transcript + "\n")
stream.is_final_end_time = stream.result_end_time
stream.last_transcript_was_final = True
# Exit recognition if any of the transcribed phrases could be
# one of our keywords.
if re.search(r"\b(exit|quit)\b", transcript, re.I):
sys.stdout.write(YELLOW)
sys.stdout.write("Exiting...\n")
stream.closed = True
break
else:
sys.stdout.write(RED)
sys.stdout.write("\033[K")
sys.stdout.write(str(corrected_time) + ": " + transcript + "\r")
stream.last_transcript_was_final = False↓
# セリフ確定
if result.is_final:
# 標準出力
sys.stdout.write('\r' + transcript + '\n')
# ファイル出力
with open(FILE_NAME, mode='a') as f:
f.write(transcript + '\n')
# ストリームの設定
stream.is_final_end_time = stream.result_end_time
stream.last_transcript_was_final = True
# セリフ入力中
else:
# 標準出力
sys.stdout.write(transcript + '\r')
# ストリームの設定
stream.last_transcript_was_final = False(3) RecognitionConfigでlanguage_codeをen-USからja-JPに変更。
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=SAMPLE_RATE,
language_code="ja-JP",
max_alternatives=1,
)(4) 不必要な標準出力をコメントアウト。
'''
print(mic_manager.chunk_size)
sys.stdout.write(YELLOW)
sys.stdout.write('\nListening, say "Quit" or "Exit" to stop.\n\n')
sys.stdout.write("End (ms) Transcript Results/Status\n")
sys.stdout.write("=====================================================\n")
''' '''
sys.stdout.write(YELLOW)
sys.stdout.write(
"\n" + str(STREAMING_LIMIT * stream.restart_counter) + ": NEW REQUEST\n"
)
'''実行結果は、次のとおりです。
$ python transcribe_streaming_infinite.py
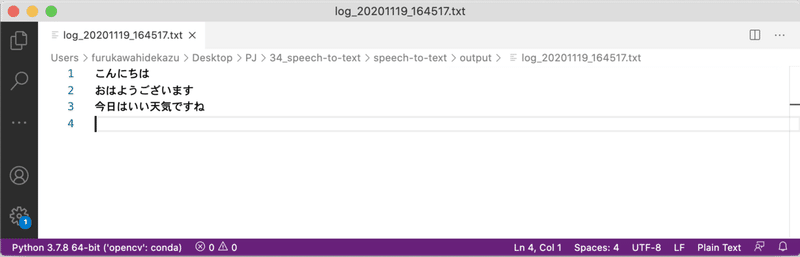
こんにちは
おはようございます
今日はいい天気ですね「./output/log_<日>_<時>.txt」に、ファイルも出力されています。
7. 参考
◎ 開発ドキュメント
◎ APIリファレンス
【おまけ】 Macでrawファイルをwavファイルに変換
Macでrawファイルをwavファイルに変換する方法は、次のとおりです。
(1) soxのインストール。
$ brew install sox(2) rawファイルをwavファイルに変換
$ sox -r 16000 -b 16 -e signed-integer audio.raw audio.wav【おまけ】 音声認識の設定
音声認識の設定のクラスをまとめました。
「RecognitionConfig」のプロパティは、次のとおり。
◎ encoding : AudioEncoding
オーディオのエンコード。FLACとWAVではオプション、他のオーディオでは必須。
◎ sample_rate_hertz : int32
オーディオのヘルツ単位のサンプルレート。有効な値は8000〜48000。 16000が最適。
◎ audio_channel_count : int32
マルチチャネル認識の場合の、入力オーディオのチャンネル数。
◎ enable_separate_recognition_per_channel : bool
trueの場合、マルチチャネル認識。
◎ language_code : string (必須)
言語コード。
◎ max_alternatives : int32
返される認識結果の最大数。具体的には、各SpeechRecognitionResult内のSpeechRecognitionAlternativeの最大数。
◎ profanity_filter : bool
trueの場合、サーバーは冒とく表現を除外。フィルタリングされた各単語の最初の文字を除くすべてを「*」に置き換える。
◎ speech_contexts[] : SpeechContext
SpeechContextの配列。音声認識を支援するためのコンテキストを提供する手段。
◎ enable_word_time_offsets : bool
trueの場合、一番上の結果に、単語のリストと、単語の開始時間と終了時間のオフセット(タイムスタンプ)が含ませる。falseの場合、ワードレベルのタイムオフセット情報は返されない。デフォルトはfalse。
◎ enable_automatic_punctuation : bool
trueの場合、暫定結果に句読点を追加。この機能は、一部の言語でのみ使用できる。
◎ diarization_config : SpeakerDiarizationConfig
スピーカーのダイアリゼーションを有効にし、追加のパラメータを設定して、ダイアリゼーションをアプリにより適したものにするように設定。
◎ metadata : RecognitionMetadata
このリクエストに関するメタデータ。
◎ model : string
モデル。デフォルトは、RecognitionConfigのパラメータを元に自動選択。
・command_and_search : 音声コマンドや音声検索などの短いクエリに最適。
・phone_call : 電話のオーディオに最適(サンプリングレートは8kHz)。
・video : ビデオ、または複数のスピーカーのオーディオに最適(サンプリングレートは16kHz)。プレミアムモデル。
・default : 特定のオーディオモデルの1つではないオーディオに最適。長いオーディオなど(high-fidelityで、サンプリングレートは16kHz以上)。
◎ use_enhanced : bool
trueの場合、音声認識に拡張モデルを使用。
「StreamingRecognitionResult」のプロパティは、次のとおり。
◎ alternatives[] : SpeechRecognitionAlternative
音声認識結果のリスト(最大max_alternatives)。
◎ is_final : bool
trueの場合、確定結果。falseの場合、暫定結果。
◎ stability : float
認識者が暫定結果についての推測を変更しない可能性の推定(0.0〜1.0)
◎ result_end_time : Duration
オーディオの開始に対するこの結果の終了時間のオフセット。
◎ channel_tag : int32
マルチチャネルのチャネル番号(1〜audio_channel_count)。
「StreamingRecognitionConfig」のプロパティは、次のとおり。
◎ config : RecognitionConfig (必須)
音声認識の設定。
◎ single_utterance : bool
trueの場合、単一の発話を検出。falseの場合、入力ストリーム切断まで、または制限時間に達するまで、音声認識を実行。
◎ interim_results : bool
trueの場合、暫定結果(is_final = true)が返される場合がある。falseの場合、確定結果(is_final = true)のみ返される。
「StreamingRecognizeRequest」の引数は、次のとおり。
◎ streaming_config : StreamingRecognitionConfig
ストリーム設定。
◎ audio_content : bytes
オーディオコンテンツ。オーディオバイトは、RecognitionConfigで指定されているようにエンコードする必要がある。
【おまけ】 音声認識の結果
音声認識の結果のクラスをまとめました。
「RecognizeResponse」のプロパティは、次のとおり。
◎ results[] : SpeechRecognitionResult
音声認識結果のリスト。
「SpeechRecognitionResult」のプロパティは、次のとおり。
◎ alternatives[] : SpeechRecognitionAlternative
音声認識結果のリスト(最大max_alternatives)。
◎ channel_tag : int32
マルチチャネルのチャネル番号(1〜audio_channel_count)。
「SpeechRecognitionAlternative」のプロパティは、次のとおり。
◎ transcript : string
音声認識結果のテキスト。
◎ confidence : float
信頼度(0.0〜1.0)。
◎ words[] : WordInfo
認識された各単語の情報のリスト。
次回
この記事が気に入ったらサポートをしてみませんか?