
DALL-E in Pytorch の使い方

以下の記事が面白かったので、ざっくり翻訳しました。
1. DALL-E in Pytorch
「DALL-E in Pytorch」は、OpenAIのText-to-Image Transformerである「DALL-E」(論文)のPyTorch実装/複製です。生成画像をランク付けするための「CLIP」も含まれます。
Eleuther AIのSid、Ben、Aranは、「DALL-E for Mesh Tensorflow」に取り組んでいます。 DALL-EがTPUで学習されるのを見たい場合は、彼らに手を貸してください。
これを複製する前に、「DeepDaze」「BigSleep」を試すことができます。
2. 状態
Hannuは、わずか2000枚の風景画像のデータセットで小さな6層の「DALL-E」を学習することに成功しました。 (2048ビジュアルトークン)

3. インストール
$ pip install dalle-pytorch4. 使用方法
(1) 「VAE」を学習します。
import torch
from dalle_pytorch import DiscreteVAE
vae = DiscreteVAE(
image_size = 256,
num_layers = 3, # ダウンサンプリングの数。ex. 256 / (2 ** 3) = (32 x 32 feature map)
num_tokens = 8192, # visual tokensの数。論文では8192を使用したが、もっと小さくすることができる
codebook_dim = 512, # codebookの次元
hidden_dim = 64, # hiddenの次元
num_resnet_blocks = 1, # resnetのブロックの数
temperature = 0.9, # gumbel softmax温度。これが低いほど、離散化は難しくなる
straight_through = False, # gumbel softmaxのためのstraight-through。どちらが良いかわからない
)
images = torch.randn(4, 3, 256, 256)
loss = vae(images, return_loss = True)
loss.backward()
# 良いcodebookを学ぶため多くのデータで学習(2) 事前学習した「VAE」を使用して「DALL-E」を学習します。
import torch
from dalle_pytorch import DiscreteVAE, DALLE
vae = DiscreteVAE(
image_size = 256,
num_layers = 3,
num_tokens = 8192,
codebook_dim = 1024,
hidden_dim = 64,
num_resnet_blocks = 1,
temperature = 0.9
)
dalle = DALLE(
dim = 1024,
vae = vae, # (1)画像シーケンスの長さと(2)画像トークンの数を自動的に推測
num_text_tokens = 10000, # テキストの語彙サイズ
text_seq_len = 256, # テキストシーケンスの長さ
depth = 12, # 64を目指すべき
heads = 16, # attention headの数
dim_head = 64, # attention headの次元
attn_dropout = 0.1, # attention dropout
ff_dropout = 0.1 # feedforward dropout
)
text = torch.randint(0, 10000, (4, 256))
images = torch.randn(4, 3, 256, 256)
mask = torch.ones_like(text).bool()
loss = dalle(text, images, mask = mask, return_loss = True)
loss.backward()
# 大量のデータを使用して上記を長時間実行
images = dalle.generate_images(text, mask = mask)
images.shape # (4, 3, 256, 256)5. OpenAIの事前学習済みVAE
OpenAIがリリースした事前学習済みモデルを使用して、VAEの学習を完全にスキップすることもできます。最初に以下を実行する必要があります。
$ pip install git+https://github.com/openai/DALL-E.git次に、OpenAIDiscreteVAEをインポートしてインスタンス化します。 モデルのダウンロードとキャッシュを自動的に処理する必要があります。
import torch
from dalle_pytorch import OpenAIDiscreteVAE, DALLE
vae = OpenAIDiscreteVAE() # 事前学習済みのOpenAIVAEをロード
dalle = DALLE(
dim = 1024,
vae = vae, # (1)画像シーケンスの長さと(2)画像トークンの数を自動的に推測
num_text_tokens = 10000, # テキストの語彙サイズ
text_seq_len = 256, # テキストシーケンスの長さ
depth = 1, # 64を目指すべき
heads = 16, # attention headの数
dim_head = 64, # attention headの次元
attn_dropout = 0.1, # attention dropout
ff_dropout = 0.1 # feedforward dropout
)
text = torch.randint(0, 10000, (4, 256))
images = torch.randn(4, 3, 256, 256)
mask = torch.ones_like(text).bool()
loss = dalle(text, images, mask = mask, return_loss = True)
loss.backward()6. 世代のランキング
(1)「CLIP」を学習します。
import torch
from dalle_pytorch import CLIP
clip = CLIP(
dim_text = 512,
dim_image = 512,
dim_latent = 512,
num_text_tokens = 10000,
text_enc_depth = 6,
text_seq_len = 256,
text_heads = 8,
num_visual_tokens = 512,
visual_enc_depth = 6,
visual_image_size = 256,
visual_patch_size = 32,
visual_heads = 8
)
text = torch.randint(0, 10000, (4, 256))
images = torch.randn(4, 3, 256, 256)
mask = torch.ones_like(text).bool()
loss = clip(text, images, text_mask = mask, return_loss = True)
loss.backward()(2) 学習した「CLIP」から類似度スコアを取得します。
images, scores = dalle.generate_images(text, mask = mask, clip = clip)
scores.shape # (2,)
images.shape # (2, 3, 256, 256)
# 論文では512 samplingのtop 32公式の「CLIP」を使用して、「DALL-E」の画像をランク付けすることもできます。
7. スケーリングの深さ
ブログ投稿では、64層を使用して結果を達成しました。ユーザーが計算を犠牲にして深度をスケーリングしようとするために、Reformerの論文からリバーシブルネットワークを追加しました。リバーシブルネットワークを使用すると、メモリコストをかけずに任意の深さに拡張できますが、計算コストは2倍強になります(各レイヤーはバックワードパスで再実行されます)。
DALLEクラスのリバーシブルキーワードをTrueに設定するだけです。
dalle = DALLE(
dim = 1024,
vae = vae,
num_text_tokens = 10000,
text_seq_len = 256,
depth = 64,
heads = 16,
reversible = True # <-- reversible networks https://arxiv.org/abs/2001.04451
)8. Sparse Attention
ブログ投稿では、主に画像で使用される、様々なタイプのSparse Attentionをほのめかしました(テキストはおそらくFull Causal Attentionを持っていました)。私は、リリースされたわずかな詳細について、これらのタイプのSparse Attentionを再現するために最善を尽くしました。主に、彼らはCausal Axial Row / Column Attentionを行っているようです。Causal Convolution-like Attentionと組み合わされます。
デフォルトでは、DALLEはすべての層にFull Attentionを使用しますが、層ごとにAttentionタイプを次のように指定できます。
・full : Full Attention
・axial_row : Axial Attention(画像特徴マップの行に沿って)
・axial_col : Axial Attention(画像特徴マップの列に沿って)
・conv_like : Convolution-Like Attention(画像特徴マップ用)
Sparse Attentionは画像にのみ適用されます。 ブログ投稿で述べられているように、テキストは常にFull Attentionを集めます。
dalle = DALLE(
dim = 1024,
vae = vae,
num_text_tokens = 10000,
text_seq_len = 256,
depth = 64,
heads = 16,
reversible = True,
attn_types = ('full', 'axial_row', 'axial_col', 'conv_like') # cycles between these four types of attention
)9. Deepspeed Sparse Attention
Microsoft DeepspeedのSparse Attentionを使用して、Dense AttentionのSparse Attentionの任意の組み合わせで、学習することもできます。
(1) SparseAttentionを使用してDeepspeedをインストール。
$ sh install_deepspeed.sh(2) pipでtritonをインストール。
$ pip install triton上記の両方が成功した場合は、Sparse Attentionで学習できます。
dalle = DALLE(
dim = 512,
vae = vae,
num_text_tokens = 10000,
text_seq_len = 256,
depth = 64,
heads = 8,
attn_types = ('full', 'sparse') # interleave sparse and dense attention for 64 layers
)10. 学習
このセクションでは、Discrete Variational AutoEncoderと最終的なMulti-Modal Transformer (DALL-E)を学習する方法の概要を説明します。全ての実験追跡にWeights&Biasesを使用します。
Google Colabで、このセクションの全てを実行することもできます。
$ pip install wandb$ wandb login◎ VAE
「VAE」を学習するには、以下を実行する必要があります。
$ python train_vae.py --image_folder /path/to/your/imagesすべてを正しくインストールすると、実験ページへのリンクがターミナルに表示されます。 以下のレイアウト例のように、そこにあるリンクをたどって実験をカスタマイズできます。
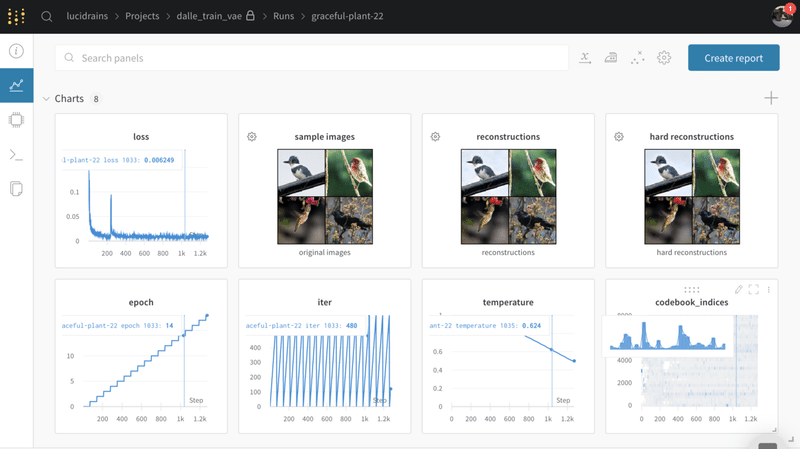
「./train_vae.py」を開いて、定数やWeights & Biasesに渡すものを変更したり、VAEをよりよく学習させるために知っている他のトリックを変更したりすることができます。
モデルは定期的に「./vae.pt」に保存されます。
実験トラッカーでは、ハードな再構成を監視する必要があります。これは、基本的にネットワークに画像を個別の視覚的なトークンに圧縮して、Transformerで視覚的な語彙として使用するように教えているからです。
重みとバイアスは、温度アニーリング、画像再構成(エンコーダとデコーダが正しく動作しているか)、コードブックの崩壊(ネットワークが提供したトークンのうち、いくつかのトークンだけを使用することを決定する)を監視することを可能にします。
満足のいくまでまともなVAEを訓練したら、「./vae.pt」でモデルの重みを設定して次のステップに進むことができます。
◎ DALL-E
「./train_dalle.py」を開いて、使用したいVAEモデルと、画像とテキストの場合はフォルダへのパスを指定してください。
私が現在作業しているデータセットには、画像とテキストファイルのフォルダがあり、テキストファイル名は画像名に対応し、各テキストファイルには複数の説明が含まれ、改行で区切られています。このスクリプトは、同じ名前の画像ファイルとテキストファイルをすべて見つけてペアリングし、バッチ作成中にテキストファイルの説明文の中からランダムに1つを選択します。
ex.
📂image-and-text-data
┣ 📜cat.png
┣ 📜cat.txt
┣ 📜dog.jpg
┣ 📜dog.txt
┣ 📜turtle.jpeg
┗ 📜turtle.txtex. cat.txt
A black and white cat curled up next to the fireplace
A fireplace, with a cat sleeping next to it
A black cat with a red collar napping画像とテキストの記述を結びつけるための独自のディレクトリ構造を持つデータセットがある場合は、問題集で教えてください。
$ python train_dalle.py --vae_path ./vae.pt --image_text_folder /path/to/dataDALL-E 学習は、離散 VAE を行ったときのようにすぐには終了しないでしょう。元の状態から再開するには、同じスクリプトを実行しますが、DALL-E チェックポイントへのパスを指定してください。
$ python train_dalle.py --dalle_path ./dalle.pt --image_text_folder /path/to/data◎ DALL-E with OpenAI's VAE
モデルをオープンソース化してくれたおかげで、「Discrete VAE」を全く学習しなくても「DALL-E」を学習できるようになりました。単に、--vae_pathを指定せずに「train_dalle.py」を起動するだけです。
$ python train_dalle.py --image_text_folder /path/to/coco/dataset◎ 世代
「DALL-E」の学習に成功したら、保存したモデルを生成に使用できます。
$ python generate.py --dalle_path ./dalle.pt --text 'fireflies in a field under a full moon'画像が「./outputs/{your prompt}/{image number}.jpg」として保存されているのがわかります。
この記事が気に入ったらサポートをしてみませんか?