
Google Colab で はじめる NEUTRINO v0.320

「Google Colab」で「NEUTRINO v0.320」を試してみました。
【最新版の情報は以下で紹介】
1. NEUTRINO とは
「NEUTRINO」は、「楽譜」から発声タイミング・音の高さ・声質・声のかすれ具合などをニューラルネットワークで推論して、「歌声のwavファイル」を出力するツールです。
2. v0.320 の新機能
「NEUTRINO v0.320」は、NEUTRINOの高速化を行ったバージョンです。GPUによる高速レンダリングが可能になり、 最速で実時間の1/4になりました。
3. NEUTRINO(オンライン版)の準備
「NEUTRINO(オンライン版)」をダウンロードして解凍してください。「NEUTRINOフォルダ」が生成されます。
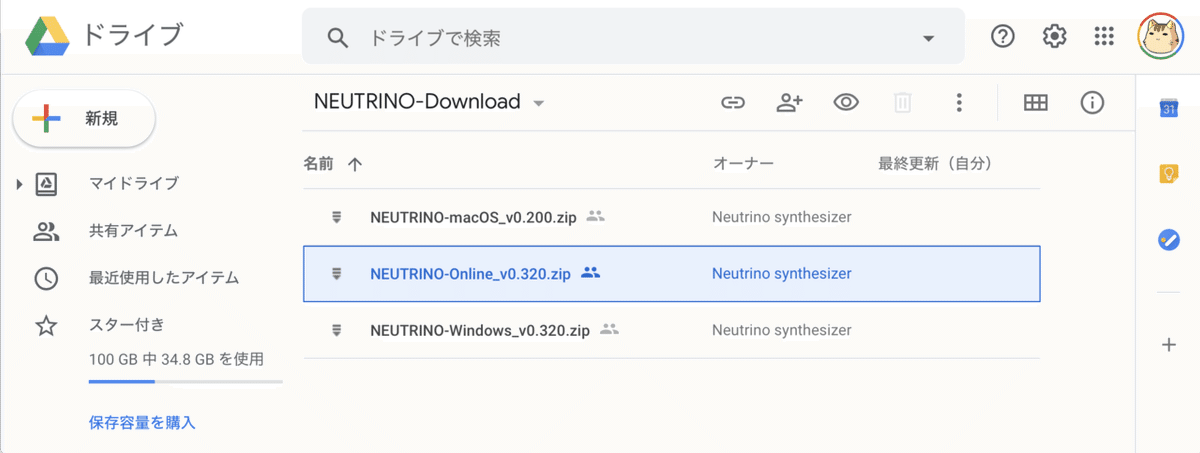
フォルダ構成は、次のとおりです。
・score : 入力ファイル
・musicxml : 楽譜ファイル
・sample1.musicxml
・sample2.musicxml
・sample3.musicxml
・ouput : 出力ファイル
・model : 音声モデル
・JSUT
・KIRITAN
・YOKO
・NEUTRINO.ipynb : ノートブック「score/musicxml」に楽譜ファイル(*.musicxml)を配置した後、「NEUTRINO.ipynb」で変換を実行することで、「output」にwavファイルが出力されます。
「model」には利用可能な音声モデル(きりたん、謡子、JSUT)が配置されています。
4. 楽譜の準備
「NEUTRINO」で使う楽譜の作成は「MuseScore」が推奨とのことなので、以下からダウンロードおよびインストールします。
楽譜は「musicxml」形式で用意して、「score/musicxml」に配置します。今回は、サンプルとして提供されている「/score/musicxml/sample1.musicxml」を使います。
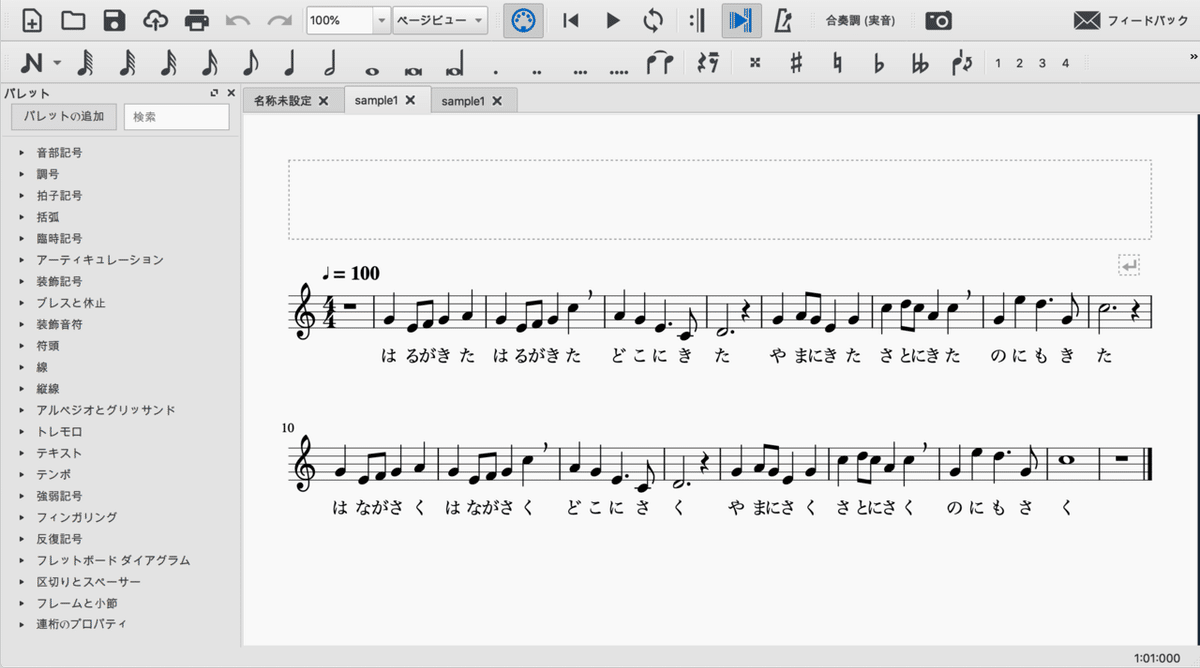
MuseScoreの使い方は以下が参考になります。
・NEUTRINOでAIに歌わせるために必要なMuseScoreの操作方法
5. Google Colabの準備
「Google Colab」(Google Colaboratory)は「Google Drive」上で動くPythonの実行環境です。「NEUTRINOフォルダ」を「Google Drive」にコピーし、「Google Colab」のアプリを追加後、ノートブックを開きます。
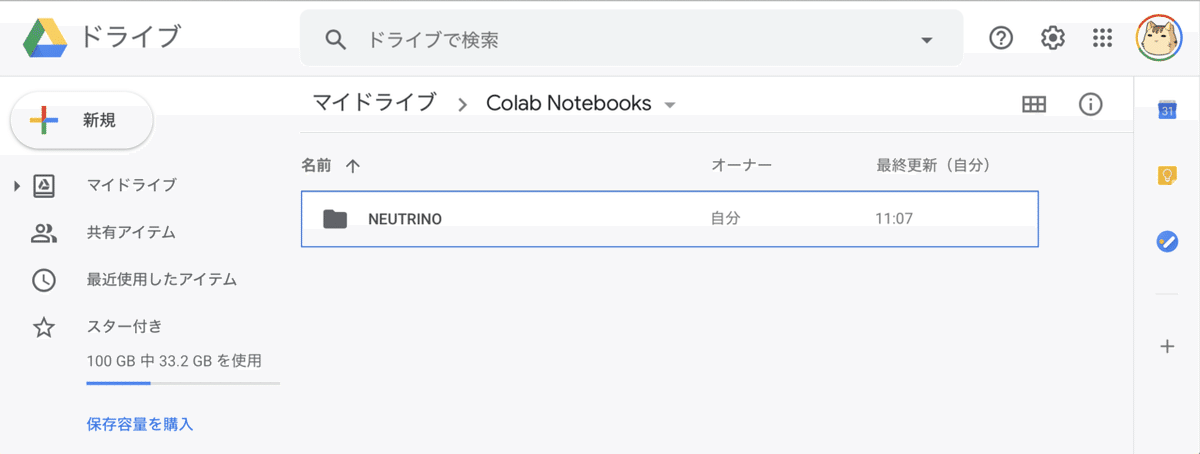
◎ NEUTRINOフォルダ を Google Drive にコピー
(1) 「Google Drive」にアクセス。
Googleアカウントでのログインが必要です。
(2) マイドライブに「Colab Notebooks」フォルダを作成し、先ほど解凍した「NEUTRINOフォルダ」をコピー。
◎ Google Colabのアプリの追加
(1) 右側の「+」をクリック後、上側の「検索」(虫眼鏡)をクリック。
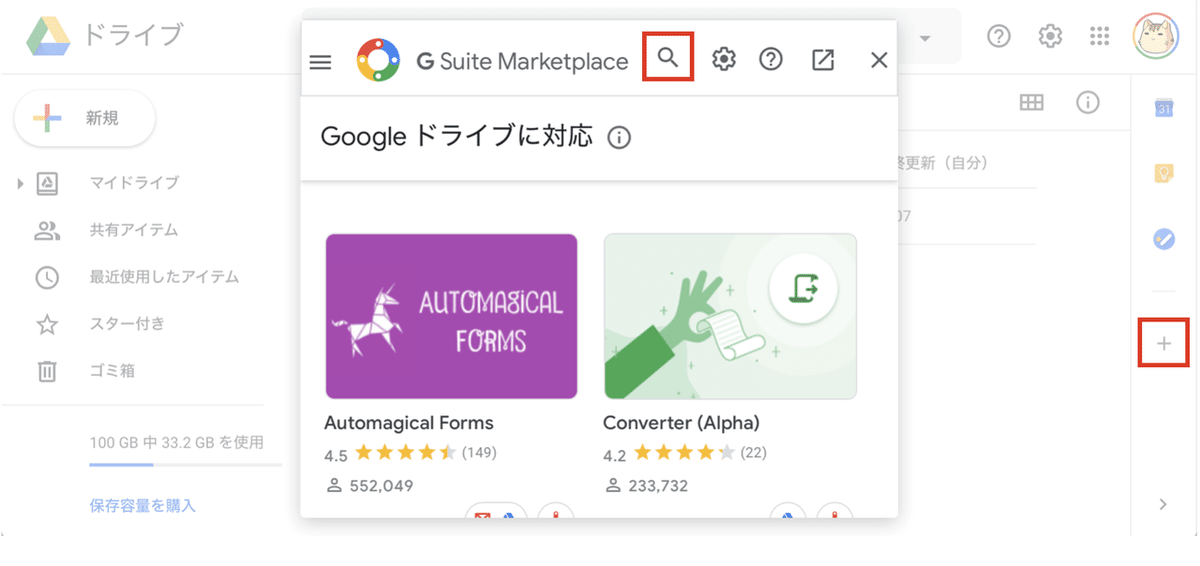
(2) 検索ボックスで「Colab」を検索し、「Colaboratory」を選択して追加。

◎ ノートブックを開く
「NEUTORINO.ipynb」をダブルクリックして開きます。
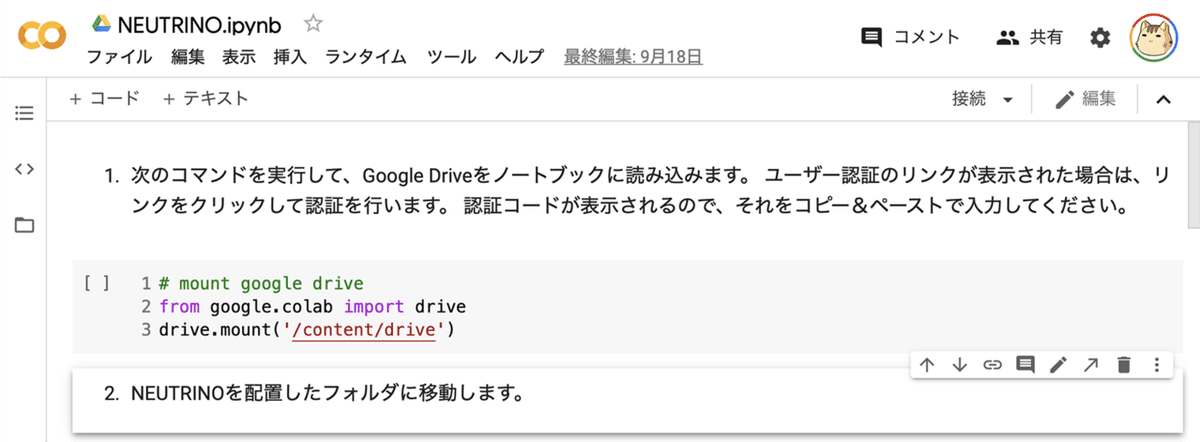
6. ノートブックの実行
(1) 1つ目のセルを選択し、セルの実行ボタンを押す。

「Google Colab」から「Google Drive」にマウント(ファイルアクセスできるように)します。
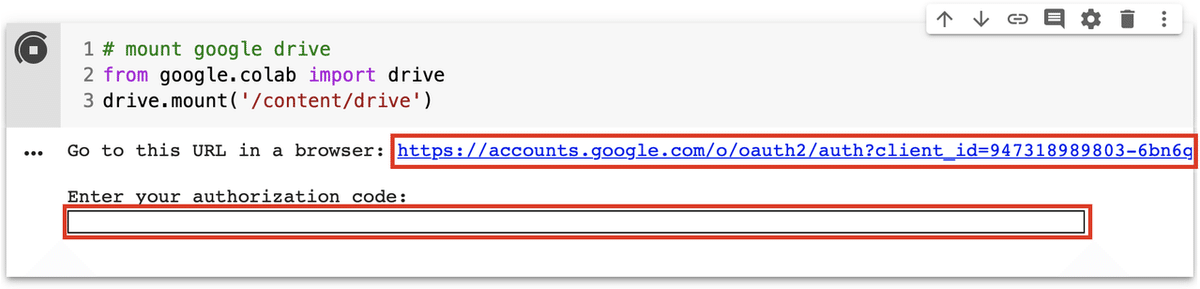
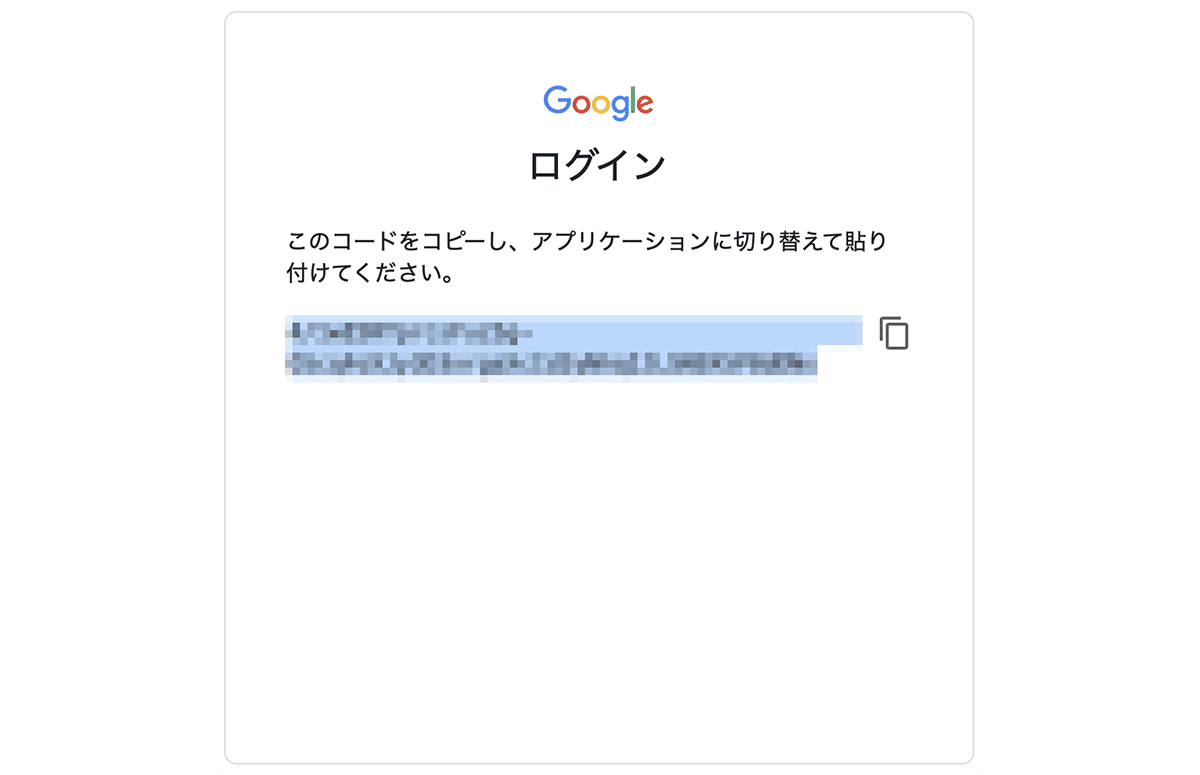
リンクが表示されたら、リンクをクリックします。認証コードが表示されるので、それをコピーして、下のテキストフィールドに貼り付けます。
(2) 2つ目のセルを選択し、セルの実行ボタンを押す。
「NEUTRINOフォルダ」に移動します。
(3) 3つ目のセルを選択し、セルの実行ボタンを押す。
ファイルが実行できるように権限を設定しています。
(4) 4つ目のセルを選択し、パラメータを確認(今回はそのまま)してから、セルの実行ボタンを押す。
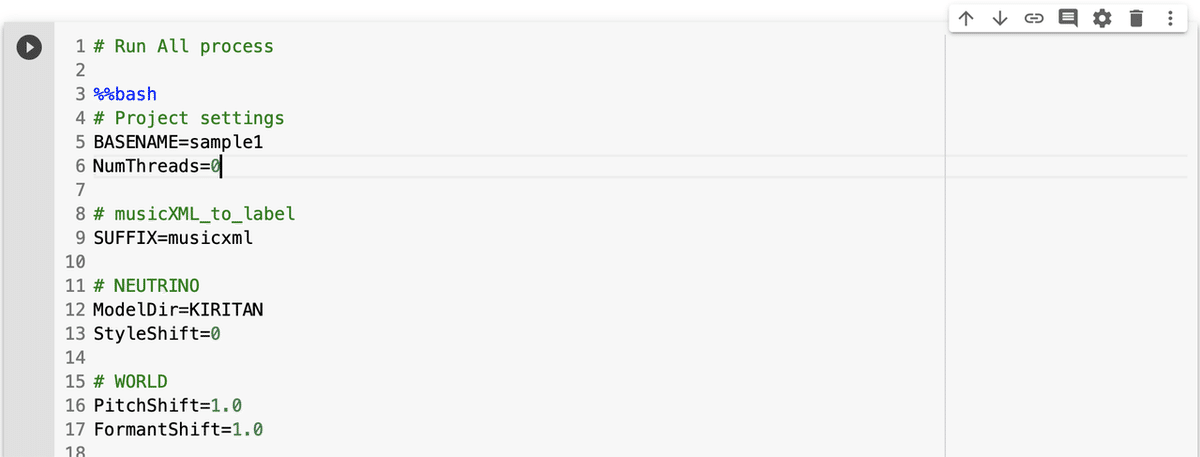
パラメータの説明は、次のとおりです。
BASENAME : musicxmlフォルダ内の楽譜ファイル名 (拡張子除く)
NumThreads : スレッド数
SUFFIX : 楽譜ファイルの拡張子
ModelDir : 音声モデルのフォルダ名 (KIRITAN, YOKO, JSUT)
PitchShift : ピッチシフト
FormantShift : フォルマント(声色)シフト成功時には、Google Driveのoutputフォルダにwavファイルが生成されています。
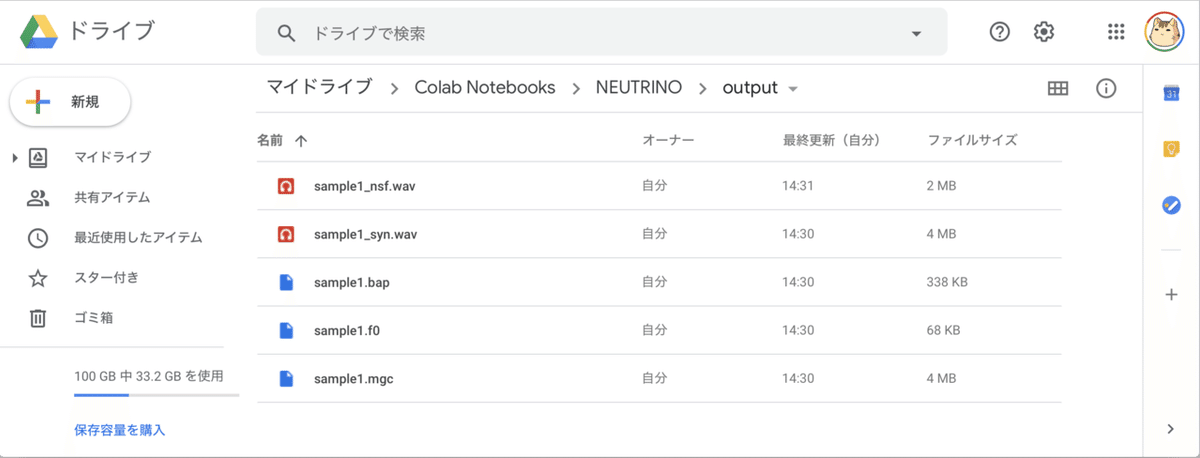
・sample1_syn.wav : world版 (パラメータをより忠実に再現)
・sample1_nsf.wav : nsf版 (人間の声に近くなるようにNNで補正)
world版とnsf版の違いは、以下の記事が参考になります。
・【AIきりたん】と【AI謡子】のWORLD版とNSF版を比較してみた
(5) wavファイルをダブルクリックして歌声を確認。
この記事が気に入ったらサポートをしてみませんか?