Google Colab で Rinna-4B + LlamaIndex の QA を試す

「Google Colab」で「Rinna-4B + LlamaIndex」の QA を試したのでまとめました。
1. 使用モデル
今回は、「rinna/bilingual-gpt-neox-4b-instruction-ppo」(8bit量子化)と埋め込みモデル「multilingual-e5-large」を使います。
2. ドキュメントの準備
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のあらすじのドキュメントを用意しました。
・bocchi.txt
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install llama-index
!pip install transformers accelerate bitsandbytes sentence_transformers sentencepiece(3) ログレベルの設定。
import logging
import sys
# ログレベルの設定
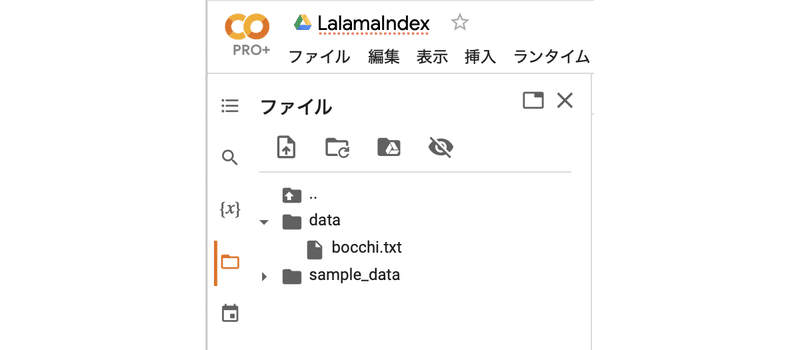
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)(4) Colabにdataフォルダを作成してドキュメントを配置。
左端のフォルダアイコンでファイル一覧を表示し、右クリック「新しいフォルダ」でdataフォルダを作成し、ドキュメントをドラッグ&ドロップします。
(6) ドキュメントの読み込み。
from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
documents = SimpleDirectoryReader("data").load_data()(7) LLMの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from langchain.llms import HuggingFacePipeline
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/bilingual-gpt-neox-4b-instruction-ppo",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/bilingual-gpt-neox-4b-instruction-ppo",
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
# パイプラインの準備
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=256
)
# LLMの準備
llm = HuggingFacePipeline(pipeline=pipe)(8) 埋め込みモデルの準備。
from langchain.embeddings import HuggingFaceEmbeddings
from llama_index import LangchainEmbedding
# 埋め込みモデルの準備
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
)(9) ノートパーサーの準備。
テキストスプリッターに、LangChainのRecursiveCharacterTextSplitterを使います。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index.node_parser import SimpleNodeParser
# チャンクの分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=514, # チャンクの最大文字数
chunk_overlap=20, # オーバーラップの最大文字数
)
# ノードパーサーの準備
node_parser = SimpleNodeParser(text_splitter=text_splitter)(10) サービスコンテキストの準備。
from llama_index import ServiceContext
# サービスコンテキストの準備
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)(11) インデックスの作成。
from llama_index import VectorStoreIndex
# インデックスの作成
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)Adding chunk: 結束バンド...
Adding chunk: 後藤ひとりは友達を作れない陰キャでいつも一人で過ごしていたが、...
Adding chunk: ことを知る。紆余(うよ)曲折の末、...
Adding chunk: 文化祭ライブ...
Adding chunk: 夏休みに入り、...
Adding chunk: る。そしてひとりたちは、...
Adding chunk: デモ審査...
Adding chunk: 未確認ライオットに参加するためには、...
Adding chunk: れる結束バンドだったが、...
Adding chunk: 後藤ひとり(ごとうひとり)...
Adding chunk: 秀華高校に通う女子。...
Adding chunk: ものだが、他人と合わせるセッションの経験が皆無なため、...
Adding chunk: 伊地知虹夏(いじちにじか)...
Adding chunk: 下北沢高校に通う女子。...
Adding chunk: いてきており、...
Adding chunk: 山田リョウ(やまだりょう)...
Adding chunk: 下北沢高校に通う女子。...
Adding chunk: も及ばず、成績はつねに赤点。...
Adding chunk: 喜多郁代(きたいくよ)...
Adding chunk: 秀華高校に通う女子。...
Adding chunk: 以上いる。...
Adding chunk: 廣井きくり(ひろいきくり)...
Adding chunk: 実力派サイケデリックロックバンド「SICKHACK(シックハック)」に所属する女性。...
Adding chunk: のシャワーを使ったり、タダ飯にありつこうとしているため、...
Adding chunk: 後藤ふたり(ごとうふたり)...
Adding chunk: 清水イライザ(しみずいらいざ)...
Adding chunk: 岩下志麻(いわしたしま)...
Adding chunk: 長谷川あくび(はせがわあくび)...
Adding chunk: 佐々木次子(ささきつぐこ)...
Adding chunk: 大槻ヨヨコ(おおつきよよこ)...
Adding chunk: 人気メタルバンド「SIDEROS(シデロス)」のリーダーを務める少女。...
Adding chunk: 佐藤愛子(さとうあいこ)...
Adding chunk: フリーライターとして活動する女性。...
Adding chunk: に参加させるきっかけをつくった。...
Adding chunk: ひとりの父(ひとりのちち)...
Adding chunk: 2号(にごう)...
Adding chunk: 吉田銀次郎(よしだぎんじろう)...
Adding chunk: PAさん(ぴーえーさん)...
Adding chunk: 伊地知星歌(いじちせいか)...
Adding chunk: 完熟マンゴー仮面(かんじゅくまんごーかめん)...
Adding chunk: ギターヒーロー...(12) QAテンプレートの準備。
LangChainのQAテンプレートをコピペしてます。LlamaIndexのQAテンプレートでは「Llama 2 + 日本語」でうまく回答してくれませんでした。
from llama_index.prompts.prompts import QuestionAnswerPrompt
# QAテンプレートの準備
qa_template = QuestionAnswerPrompt("""Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context_str}
Question: {query_str}
Helpful Answer:""")(13) クエリエンジンの作成。
# クエリエンジンの作成
query_engine = index.as_query_engine(
similarity_top_k=3,
text_qa_template=qa_template,
)(14) 質問応答。
qa_chain.run("日本語で回答してください。後藤ひとりの得意な楽器は?")ギター4. 追加の質問応答
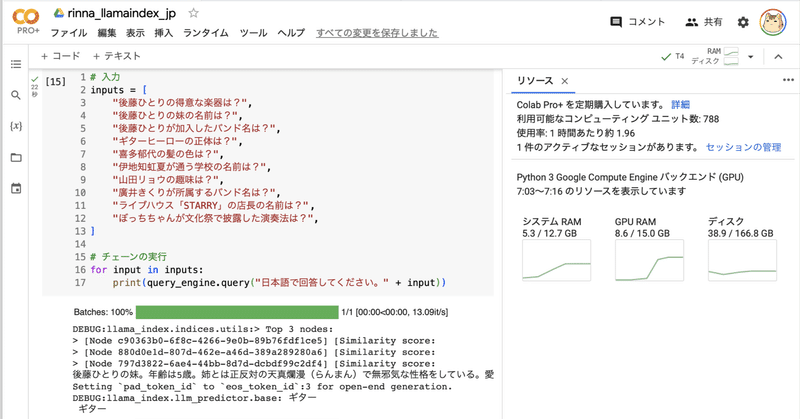
10個の質問を投げてみます。
# 入力
inputs = [
"後藤ひとりの得意な楽器は?",
"後藤ひとりの妹の名前は?",
"後藤ひとりが加入したバンド名は?",
"ギターヒーローの正体は?",
"喜多郁代の髪の色は?",
"伊地知虹夏が通う学校の名前は?",
"山田リョウの趣味は?",
"廣井きくりが所属するバンド名は?",
"ライブハウス「STARRY」の店長の名前は?",
"ぼっちちゃんが文化祭で披露した演奏法は?",
]
# チェーンの実行
for input in inputs:
print(query_engine.query("日本語で回答してください。" + input))・ギター
・後藤ひとりの妹の名前は、後藤ひとりより1学年上です。【不正解】
・結束バンド
・後藤ひとりが動画配信の際に用いるハンドルネーム。ひとりは「ギターヒーロー」の名で動画配信して、スゴ腕の女子高生ギタリストとしてカリスマ的な人気を集めている。
・赤
・下北沢高校
・ギター【不正解】
・SIDEROS(シデロス)
・伊地知虹夏【不正解】
・ボトルネック奏法
正解率は7/10でした。
この記事が気に入ったらサポートをしてみませんか?