Google Colab で LLM-jp-13B を試す

「Google Colab」で「LLM-jp-13B」を試したので、まとめました。
【注意】Google Colab Pro/Pro+ のT4 ハイメモリで動作確認しています。
1. LLM-jp-13B
「LLM-jp-13B」は、「国立情報学研究所(NII)」が開発した130億パラメータの日本語LLMです。
2. LLM-jp-13Bのモデル
「LLM-jp-13B」は、現在4つのモデルのみが提供されています。
・llm-jp-13b-instruct-full-jaster-v1.0
・llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0
・llm-jp-13b-instruct-full-dolly-oasst-v1.0
・llm-jp-13b-instruct-lora-jaster-v1.0
・llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0
・llm-jp-13b-instruct-lora-dolly-oasst-v1.0
・llm-jp-13b-v1.0
・llm-jp-1.3b-v1.0
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「T4」の「ハイメモリ」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install transformers sentencepiece accelerate(2) トークナイザーとモデルの準備。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0",
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0",
torch_dtype=torch.float16,
device_map="auto",
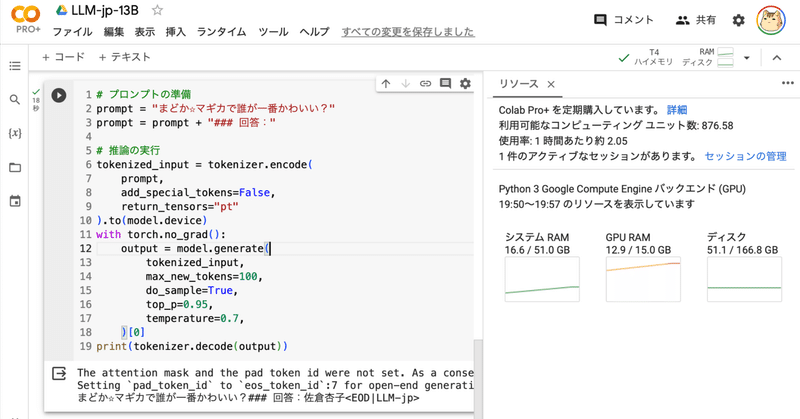
)(3) 推論の実行。
# プロンプトの準備
prompt = "まどか☆マギカで誰が一番かわいい?"
prompt = prompt + "### 回答:"
# 推論の実行
tokenized_input = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))まどか☆マギカで誰が一番かわいい?### 回答:佐倉杏子<EOD|LLM-jp>この記事が気に入ったらサポートをしてみませんか?