
Stable Baselines チュートリアル(3) / 環境のマルチプロセッシング

以下のColabが面白かったので、ざっくり訳してみました。
・Stable Baselines Tutorial - Multiprocessing of environments
1. はじめに
このノートブックでは、「ベクトル化環境」(別名マルチプロセッシング)を使用して訓練を高速化する方法を学習します。また、この高速化には「サンプル効率」が犠牲になることがわかります。
2. pipを使用して依存関係と安定したベースラインをインストール
Colabでのインストールコマンドは次の通りです。
!apt install swig cmake libopenmpi-dev zlib1g-dev
!pip install stable-baselines[mpi]==2.8.03. TensorFlowの警告を削除
TensorFlow 1.xから2.xへの以降による警告をフィルタリングします。
# TensorFlowのバージョンの警告をフィルタリング
import os
# https://stackoverflow.com/questions/40426502/is-there-a-way-to-suppress-the-messages-tensorflow-prints/40426709
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # or any {'0', '1', '2'}
import warnings
# https://stackoverflow.com/questions/15777951/how-to-suppress-pandas-future-warning
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=Warning)
import tensorflow as tf
tf.get_logger().setLevel('INFO')
tf.autograph.set_verbosity(0)
import logging
tf.get_logger().setLevel(logging.ERROR)4. ベクトル化環境とインポート
「ベクトル化環境」は、複数の独立した環境を単一の環境にスタックする方法です。ステップごとに1つの環境でRLエージェントを訓練する代わりに、ステップごとにn個の環境で訓練することができます。
これには2つの利点があります。
・エージェントの経験をより迅速に収集できる。
・エージェントはより多様な経験を収集できる。通常、探索が向上します。
「Stable-Baselines」は、2種類の「ベクトル化環境」を提供します。
・SubprocVecEnv : 各環境を個別のプロセスで実行
・DummyVecEnv : 同じプロセスですべての環境を実行
実際には、サブプロセスの通信遅延のために、「DummyVecEnv」は通常「SubprocVecEnv」よりも高速になります。
import time
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gym
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv, SubprocVecEnv
from stable_baselines.common import set_global_seeds
from stable_baselines import PPO25. 評価関数の定義
def evaluate(model, env, num_episodes=100):
# この関数は、単一の環境でのみ機能する
all_episode_rewards = []
for i in range(num_episodes):
episode_rewards = []
done = False
obs = env.reset()
while not done:
action, _states = model.predict(obs)
obs, reward, done, info = env.step(action)
episode_rewards.append(reward)
all_episode_rewards.append(sum(episode_rewards))
mean_episode_reward = np.mean(all_episode_rewards)
return mean_episode_reward6. 環境関数の定義
「マルチプロセッシング」の実装には、Gym環境をインスタンス化するためにプロセス内で呼び出すことができる関数が必要になります。
def make_env(env_id, rank, seed=0):
"""
マルチプロセス環境のユーティリティ関数。
:param env_id: (str) 環境ID
:param num_env: (int) サブプロセスに含める環境の数
:param seed: (int) RNGの初期シード
:param rank: (int) サブプロセスのインデックス
"""
def _init():
env = gym.make(env_id)
# 【重要】環境ごとに異なるシードを使用してください
env.seed(seed + rank)
return env
set_global_seeds(seed)
return _init7. 定数を定義
Cartpole環境 : https://gym.openai.com/envs/CartPole-v1/
他の環境やアルゴリズムも試してみてください。
# 環境
env_id = 'CartPole-v1'
# プロセス数
PROCESSES_TO_TEST = [1, 2, 4, 8, 16]
# RLアルゴリズムは不安定になることが多いため、実験を複数回実行
# (https://arxiv.org/abs/1709.06560を参照)
NUM_EXPERIMENTS = 3
TRAIN_STEPS = 5000
# 評価するエピソード数
EVAL_EPS = 20
# 評価するアルゴリズム
ALGO = PPO2
# エージェントを評価するための環境の生成
eval_env = DummyVecEnv([lambda: gym.make(env_id)])8. 異なるプロセス数による反復処理
異なるプロセス数による実験を実行します。
これには数分かかる場合があります。
reward_averages = []
reward_std = []
training_times = []
total_procs = 0
for n_procs in PROCESSES_TO_TEST:
total_procs += n_procs
print('Running for n_procs = {}'.format(n_procs))
if n_procs == 1:
# プロセスが1つしかない場合は、マルチプロセッシングを使用する必要はない
train_env = DummyVecEnv([lambda: gym.make(env_id)])
else:
# プロセスを起動するために「spawn」を使用。詳細については、ドキュメントを参照
train_env = SubprocVecEnv([make_env(env_id, i+total_procs) for i in range(n_procs)], start_method='spawn')
rewards = []
times = []
for experiment in range(NUM_EXPERIMENTS):
# 結果のばらつきのため、いくつかの実験を実行することをお勧めする
train_env.reset()
model = ALGO('MlpPolicy', train_env, verbose=0)
start = time.time()
model.learn(total_timesteps=TRAIN_STEPS)
times.append(time.time() - start)
mean_reward = evaluate(model, eval_env, num_episodes=EVAL_EPS)
rewards.append(mean_reward)
# 重要:サブプロセスを使用する場合は、サブプロセスを閉じることを忘れないように。
# 多くの実験を実行すると、メモリの問題が発生する可能性がある
train_env.close()
reward_averages.append(np.mean(rewards))
reward_std.append(np.std(rewards))
training_times.append(np.mean(times))Running for n_procs = 1
Running for n_procs = 2
Running for n_procs = 4
Running for n_procs = 8
Running for n_procs = 16結果をプロットします。
training_steps_per_second = [TRAIN_STEPS / t for t in training_times]
plt.figure()
plt.subplot(1,2,1)
plt.errorbar(PROCESSES_TO_TEST, reward_averages, yerr=reward_std, capsize=2)
plt.xlabel('Processes')
plt.ylabel('Average return')
plt.subplot(1,2,2)
plt.bar(range(len(PROCESSES_TO_TEST)), training_steps_per_second)
plt.xticks(range(len(PROCESSES_TO_TEST)),PROCESSES_TO_TEST)
plt.xlabel('Processes')
plt.ylabel('Training steps per second')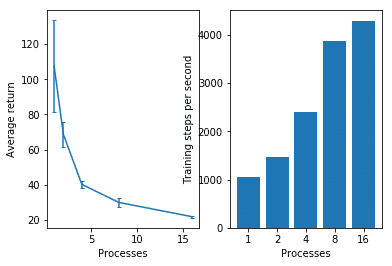
「平均報酬」は、プロセス数が多いほど下がっています。
「秒間のステップ数」は、プロセス数が多いほど上がっています。
9. サンプル効率と実時間のトレードオフ
サンプル効率、多様な経験、実時間の間には明らかにトレードオフがあります。一定時間、実験ごとに10秒での最高のパフォーマンスを計測します。
SECONDS_PER_EXPERIMENT = 10
steps_per_experiment = [int(SECONDS_PER_EXPERIMENT * fps) for fps in training_steps_per_second]
reward_averages = []
reward_std = []
training_times = []
for n_procs, train_steps in zip(PROCESSES_TO_TEST, steps_per_experiment):
total_procs += n_procs
print('Running for n_procs = {} for steps = {}'.format(n_procs, train_steps))
if n_procs == 1:
# プロセスが1つしかない場合は、マルチプロセッシングを使用する必要はない
train_env = DummyVecEnv([lambda: gym.make(env_id)])
else:
train_env = SubprocVecEnv([make_env(env_id, i+total_procs) for i in range(n_procs)], start_method='spawn')
# 通信遅延がボトルネックである場合、DummyVecEnvを使用できる
# train_env = DummyVecEnv([make_env(env_id, i+total_procs) for i in range(n_procs)])
rewards = []
times = []
for experiment in range(NUM_EXPERIMENTS):
# 結果のばらつきのため、いくつかの実験を実行することをお勧めする
train_env.reset()
model = ALGO('MlpPolicy', train_env, verbose=0)
start = time.time()
model.learn(total_timesteps=train_steps)
times.append(time.time() - start)
mean_reward = evaluate(model, eval_env, num_episodes=EVAL_EPS)
rewards.append(mean_reward)
train_env.close()
reward_averages.append(np.mean(rewards))
reward_std.append(np.std(rewards))
training_times.append(np.mean(times))Running for n_procs = 1 for steps = 10726
Running for n_procs = 2 for steps = 18502
Running for n_procs = 4 for steps = 34272
Running for n_procs = 8 for steps = 62248
Running for n_procs = 16 for steps = 86549結果をプロットします。
training_steps_per_second = [s / t for s,t in zip(steps_per_experiment, training_times)]
plt.figure()
plt.subplot(1,2,1)
plt.errorbar(PROCESSES_TO_TEST, reward_averages, yerr=reward_std, capsize=2, c='k', marker='o')
plt.xlabel('Processes')
plt.ylabel('Average return')
plt.subplot(1,2,2)
plt.bar(range(len(PROCESSES_TO_TEST)), training_steps_per_second)
plt.xticks(range(len(PROCESSES_TO_TEST)),PROCESSES_TO_TEST)
plt.xlabel('Processes')
plt.ylabel('Training steps per second')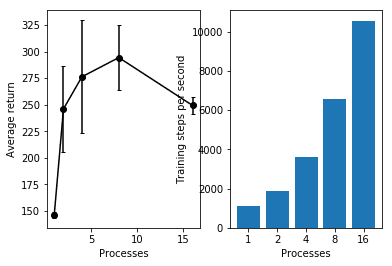
「平均報酬」は、プロセス数8が一番高いという結果になっています。
「秒間のステップ数」は、前回同様、プロセス数が多いほど上がっています。
10. DummyVecEnv vs SubprocVecEnv
reward_averages = []
reward_std = []
training_times = []
total_procs = 0
for n_procs in PROCESSES_TO_TEST:
total_procs += n_procs
print('Running for n_procs = {}'.format(n_procs))
# n_env> 1の場合でも1つのプロセスのみを使用している
train_env = DummyVecEnv([make_env(env_id, i + total_procs) for i in range(n_procs)])
rewards = []
times = []
for experiment in range(NUM_EXPERIMENTS):
# 結果のばらつきのため、いくつかの実験を実行することをお勧めする
train_env.reset()
model = ALGO('MlpPolicy', train_env, verbose=0)
start = time.time()
model.learn(total_timesteps=TRAIN_STEPS)
times.append(time.time() - start)
mean_reward = evaluate(model, eval_env, num_episodes=EVAL_EPS)
rewards.append(mean_reward)
train_env.close()
reward_averages.append(np.mean(rewards))
reward_std.append(np.std(rewards))
training_times.append(np.mean(times))Running for n_procs = 1
Running for n_procs = 2
Running for n_procs = 4
Running for n_procs = 8
Running for n_procs = 16結果をプロットします。
training_steps_per_second = [TRAIN_STEPS / t for t in training_times]
plt.figure()
plt.subplot(1,2,1)
plt.errorbar(PROCESSES_TO_TEST, reward_averages, yerr=reward_std, capsize=2)
plt.xlabel('Processes')
plt.ylabel('Average return')
plt.subplot(1,2,2)
plt.bar(range(len(PROCESSES_TO_TEST)), training_steps_per_second)
plt.xticks(range(len(PROCESSES_TO_TEST)),PROCESSES_TO_TEST)
plt.xlabel('Processes')
plt.ylabel('Training steps per second')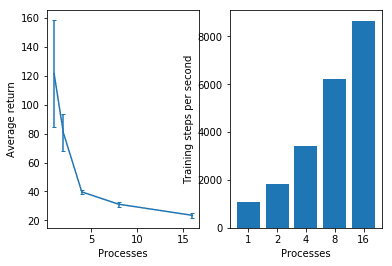
「SubprocVecEnv」より「DummyVecEnv」の方が「秒間のステップ数」が上なことがわかります。
◎何が起こっているのか
私たちの場合、n個の環境に対して1つのプロセスしか持たない方が速いようです。実際には、ボトルネックは環境の計算によるものではなく、プロセス間の同期と通信によるものです。この問題の詳細については、ここから始めることができます。
11. おわりに
このノートブックは、「マルチプロセッシング」の長所と短所を強調しています。Colabはプロセスごとに2つのCPUコアしか提供しないため、環境のFPSの線形スケーリングは見られません。対照的に、最先端のDeep RL研究では、並列処理を数万のCPUコア、OpenAI RAPID、 IMPALAに拡大しています。
別のアルゴリズム/環境、実験数、より多くの反復数を試してみることをお勧めします。
12. 参照
・Github repo: https://github.com/araffin/rl-tutorial-jnrr19
・Stable-Baselines: https://github.com/hill-a/stable-baselines
・Documentation: https://stable-baselines.readthedocs.io/en/master/
・RL Baselines zoo: https://github.com/araffin/rl-baselines-zoo
この記事が気に入ったらサポートをしてみませんか?