
Huggingface Transformers 入門 (6) - テキスト生成

以下の記事を参考に書いてます。
・How to generate text: using different decoding methods for language generation with Transformers
前回
1. はじめに
近年、OpenAIの「GPT2」のような、何百万ものWebページで学習された大規模なTransformerベースの言語モデルの台頭により、オープンエンド言語生成への関心が高まっています。
GPT2のユニコーンやXLNetやCTRLなど、条件付きオープンエンド言語生成の結果は印象的です。改良されたTransformerアーキテクチャと大規模な教師なし学習データに加えて、より優れた復号法も重要な役割を果たしています。
この記事では、様々な復号法を説明し、Transformersを使用して、少ない労力でそれらを実装する方法を紹介します。
以下の機能はすべて、自動回帰言語生成(ここで復習)に使用できます。 要するに、自動回帰言語生成は、単語列の確率分布が条件付きの次の単語分布の積に分解できるという仮定に基づいています。

𝑊_0 は初期コンテキストの単語列です。単語列の長さ𝑇は通常臨機応変に決定され、𝑃(𝑤_𝑡|𝑤_{1:𝑡-1},𝑊_0)からEOSトークンが生成されるタイムステップ𝑡=𝑇に対応します。
GPT2、XLNet、OpenAi-GPT、CTRL、TransfoXL、XLM, Bart、T5の自動後退型言語生成が PyTorch と Tensorflow >= 2.0 の両方で利用可能になりました。
Greedy探索、Beam探索、Top-kサンプリング、Top-pサンプリングを中心に、復号法を紹介します。
さっそくTransformersをインストールしてモデルをロードしてみましょう。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 警告を避けるために、EOS トークンを PAD トークンとして追加
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)2. Greedy探索
Greedy探索は、次の単語として最も確率の高い単語を選択するだけです。次のスケッチは、Greedy探索を示しています。

"The"という単語から始まり、アルゴリズムはGreedyに次の最高確率の単語"nice"を選択します。最終的に生成される単語列は"The"、"nice"、"woman"となり、全体の確率は0.5×0.4=0.2となります。
以下では、GPT2を用いて文脈("I", "enjoy", "walking", "with", "my", "cute", "dog")に続く単語列を生成します。Greedy探索がどのようにTransformersで利用できるかを見てみます。
# 条件付きでエンコードされるコンテキスト
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# 出力の長さ(コンテキスト長を含む)が50に達するまでテキスト生成
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'llGPT-2で最初の短文を生成しました。文脈に沿って生成された単語は合理的ですが、モデルはすぐに繰り返しを始めます。これは言語生成においてよくある問題であり、Greedy探索やBeam探索においてはなおさらのようです(Vijayakumar et al., 2016 と Shao et al., 2017 を参照)。
Greedy探索の大きな欠点は、上のスケッチで見られるように、低確率の単語の背後に隠された高確率の単語を見逃してしまうことです。
条件付き確率が0.9と高い "has "という単語は、2番目に高い条件付き確率しか持たない "dog "という単語の後ろに隠されているため、"The", "dog", "has "という単語列を見逃してしまいます。
私たちはこの問題を軽減するためにBeam探索を利用します。
3. Beam探索
Beam探索は、各タイムステップで最も可能性の高い仮説の num_beams を保持し、最終的に全体的に最も高い確率を持つ仮説を選択することで、隠された高確率の単語列を見落とすリスクを低減します。num_beams=2で説明してみます。

タイムステップ1では、最も可能性の高い仮説である "The", "woman "の他に、2番目に可能性の高い仮説である "The", "dog "も追跡しています。タイムステップ2で、ビームサーチは、"The", "dog", "has "の単語列が、"The", "nice", "woman "の0.2よりも0.36の確率で高いことを発見します。
Beam探索は、Greedy探索よりも常に高い確率の出力を見つけますが、最も可能性の高い出力を見つけることは保証されていません。
Beam探索がTransformersでどのように使えるか見てみます。num_beams > 1 と early_stopping=True を設定して、すべてのBeam仮説が EOS トークンに到達した時点で生成が終了するようにしています。
# Beam探索とearly_stoppingの有効化
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll結果はより流暢なものになりましたが、出力には同じ単語列の繰り返しが含まれています。簡単な解決策は、 Paulus et al. (2017) や Klein et al. (2017)によって紹介されているように、n-grams(𝑛単語の単語列)のペナルティを導入することです。最も一般的な n-grams ペナルティは、すでに見た n-gramsを作る可能性のある次の単語の確率を 0 に手動で設定することで、n-gramsが 2 回出現しないようにするものです。
no_repeat_ngram_size=2 を設定して、2-gramsが2回出現しないようにしてみます。
# no_repeat_ngram_sizeに2を設定
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a breakだいぶ良くなりました。繰り返しが出てこなくなったのがわかります。それにもかかわらず、n-gramペナルティは慎重に使用する必要があります。ニューヨークという都市について生成された記事では、2-gramのペナルティを使うべきではありません。
Beam探索のもう一つの重要な特徴は、生成後に最高得点のBeamを比較して、目的に合ったBeamを選ぶことができることです。
Transformersでは、num_return_sequencesというパラメータに、返されるべき最高得点のBeamの数を設定します。ただし、num_return_sequences <= num_beams とします。
# return_num_sequences > 1 を指定
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a step見ての通り、5つのBeam仮説は互いにわずかに異なるだけです。
オープンエンドでは、最近Beam探索が最良の選択肢ではないとする理由がいくつか提唱されています。
・Beam探索は、機械翻訳や要約のように、希望する生成の長さが多かれ少なかれ予測可能なタスクでは非常にうまく機能します(Murray et al. (2018) や Yang et al. (2018)を参照)。しかし、ダイアログやストーリーの生成など、希望する出力の長さが大きく変化する可能性があるオープンエンドの生成の場合は、この限りではありません。
・Beam探索は繰り返し生成に大きく悩まされることを見てきました。これは、ストーリー生成におけるn-gramやその他のペナルティを制御するのが特に難しいことです。なぜなら、強制的な「反復なし」と同一のn-gramの繰り返しサイクルとの間で良いトレードオフを見つけることは、多くの微調整を必要とするからです。
・Ari Holtzman et al. (2019) で論じられているように、高品質な人間の言語は、高確率の次の単語の分布には従いません。言い換えれば、人間として、私たちは生成されたテキストが私たちを驚かせ、つまらない/予測可能なものではないことを望んでいるのです。著者らは、モデルが人間のテキストに与えるであろう確率をプロットすることで、このことをうまく示しています。
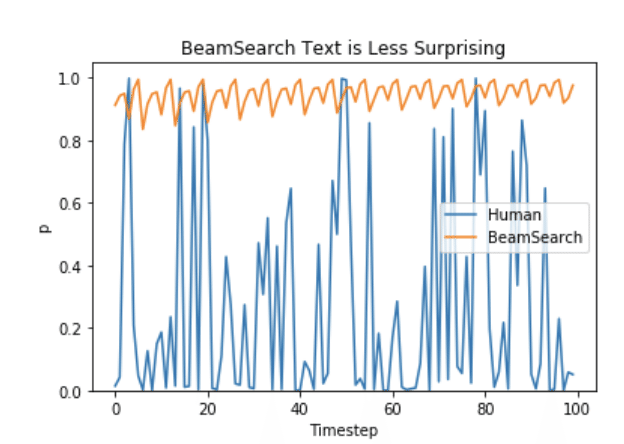
そこで、ランダム性を導入します。
4. サンプリング
サンプリングとは、条件付き確率分布に従って、次の単語 𝑤_𝑡 を無作為に選ぶことを意味します。

上記を例に、サンプリング時の言語生成を可視化したものが以下の図です。

サンプリングを用いた言語生成は、もはや決定論的ではないことが明らかになります。"car"という単語は条件付き確率分布 𝑃(𝑤|"The") からサンプリングされ、続いて 𝑃(𝑤|"The", "car") から "drives" がサンプリングされます。
Transformersでは、do_sample=True を設定し、top_k=0 で Top-k サンプリングを無効にします(これについては後述します)。 以下では、説明のために random_seed=0 を固定します。random_seedは自由に変更して、モデルで遊んでみてください。
# 結果を再現するためにシードを設定
tf.random.set_seed(0)
# top_k サンプリングを 0 に設定することでサンプリングをアクティブにし、top_k を非アクティブにする
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He just gave me a whole new hand sense."
But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside.
"I take3-gramsのnew hand senseとlocal batte harnessは非常に奇妙で、人間が書いたようには見えません。これは単語列をサンプリングするときの大きな問題です。モデルはしばしば支離滅裂な失言を生成することがあります(Ari Holtzman et al. (2019)を参照)。
トリックは、ソフトマックスのいわゆる温度を下げることで、分布 𝑃(𝑤|𝑤_{1:𝑡-1}) をシャープにすることです(高確率の単語の尤度を上げ、低確率の単語の尤度を下げる)。
上の例に温度を適用すると、次のようになります。

ステップ𝑡=1の条件付き次の単語の分布は、"car "という単語が選択される可能性がほとんどなくなり、かなりシャープになります。
tempratureを0.7に設定することで、ライブラリ内の分布をクールダウンさせる方法を見てみましょう。
# 結果を再現するためにシードを設定
tf.random.set_seed(0)
# 温度を利用して低確率候補の感度を下げる
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to be at home too much. I also find it a bit weird when I'm out shopping. I am always away from my house a lot, but I do have a few friends変なn-gramが少なくなり、出力がもう少しまとまりのあるものになりました。温度を適用することで分布をよりランダムにすることができます。温度に0を適用すると、サンプリングはGreedyと同じ問題に悩まされることになります。
5. Top-k サンプリング
Fan et. al (2018)は、Top-kサンプリングと呼ばれるシンプルで強力なサンプリング方式を導入しました。Top-kサンプリングでは、最も可能性の高いK個の次の単語をフィルタリングし、それらのK個の次の単語のみに確率を再分配します。「GPT2」では、このサンプリング方式を採用しており、これがストーリー生成に成功した理由の一つになります。
上記の例では、Top-kサンプリングをより良く説明するために、両サンプリングステップで使用される単語の範囲を3単語から10単語に拡張しています。

𝐾=6 とすると、両サンプリングステップでは、サンプリングプールを6語に限定します。𝑉_{top-k}と定義された6つの最も可能性の高い単語は、第1ステップでは確率の約3分の2に過ぎませんが、第2ステップではほぼすべての確率を含んでいます。それにもかかわらず、第2ステップでは、"not"、"the"、"small"、"telled "などの奇妙な候補を除去することに成功していることがわかります。
top_k=50に設定することで、ライブラリでTop-kがどのように使えるか見てみます。
# 結果を再現するためにシードを設定
tf.random.set_seed(0)
# top_k に 50 を指定
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting!
I am fromこのテキストは、間違いなく今のところ最も人間らしいテキストです。Top-kサンプリングでは、次の単語の確率分布 𝑃(𝑤|𝑤_{1:𝑡-1}) からフィルタリングされる単語の数を動的に適応させないことが懸念されます。これは、ある単語は非常にシャープな分布(上のグラフの右側の分布)からサンプリングされ、他の単語はよりフラットな分布(上のグラフの左側の分布)からサンプリングされる可能性があるため、問題となります。
ステップ𝑡=1では、Top-kは、合理的な候補と思われる "people"、"big"、"house"、"cat "をサンプル化する可能性を排除します。一方𝑡=2 では、"down"、"a"という一見して適合していないと思われる単語が含まれています。このように、サンプルプールを固定サイズKに限定することは、鋭い分布に対しては失言を生み出すモデルを危険にさらし、平坦な分布に対してはモデルの創造性を制限してしまう可能性があります。この直感により、Holtzman et al. (2019) はTop-pサンプリングまたはnucleusサンプリングを作成しました。
6. Top-p (nucleus) サンプリング
Top-pサンプリングは、最も可能性の高いK個の単語からのみサンプリングするのではなく、累積確率が確率pを超える可能性のある最小の単語の集合から選択します。このようにして、単語の集合のサイズ(集合内の単語の数)は、次の単語の確率分布に応じて動的に増減することができます。非常に言葉が多かったので、可視化してみます。

𝑝=0.92 を設定した場合、Top-p サンプリングでは、確率質量の 𝑝=92%を超える最小の単語数を選択します。最初の例では、最も可能性の高い9個の単語が含まれていたのに対し、2番目の例では、92%を超えるためには上位3個の単語を選ぶだけでよいです。実に単純です。これは、次の単語が予測しにくい単語の広い範囲を保持していることがわかります。
Transformersでチェックしてみます。0 < top_p < 1 を設定することで Top-p サンプリングを有効にします。
# 結果を再現するためにシードを設定
tf.random.set_seed(0)
# top_kのサンプリングを無効にし、92%の最も可能性の高い単語からのみサンプリング
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
What was that? I had a lot ofまだ完全ではないかもしれませんが、人間によって書かれた可能性があるように見えます。
理論的にはTop-pの方がTop-kよりもエレガントに見えますが、実際にはどちらの方法もうまく機能します。Top-pはTop-kと組み合わせて使用することもでき、動的な選択を可能にしながら、非常に低いランクの単語を避けることができます。
最後に、独立してサンプリングされた複数の出力を得るために、パラメータnum_return_sequences > 1を設定することができます。
# 結果を再現するためにシードを設定
tf.random.set_seed(0)
# top_k=50、top_p=0.95、num_return_sequences=3を設定
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog. It's so good to have the chance to walk with a dog. But I have this problem with the dog and how he's always looking at us and always trying to make me see that I can do something
1: I enjoy walking with my cute dog, she loves taking trips to different places on the planet, even in the desert! The world isn't big enough for us to travel by the bus with our beloved pup, but that's where I find my love
2: I enjoy walking with my cute dog and playing with our kids," said David J. Smith, director of the Humane Society of the US.
"So as a result, I've got more work in my time," he said.これで、あなたのモデルにTransformersでストーリーを書かせるためのすべてのツールが揃いました。
7. おわりに
アドホックな復号法としては、top-pサンプリングとtop-kサンプリングの方が、従来のGreedy探索やオープンエンドの言語生成におけるBeem探索よりも流暢なテキストを生成するように思われます。最近では、Greedy探索やBeam探索の見かけ上の欠陥(主に反復的な単語列の生成)が、復号法よりもむしろモデル(特にモデルの学習方法)に起因していることを示す証拠が増えてきました(Welleck et al. (2019)を参照)。また、Welleck et al. (2020)で実証されているように、top-kとtop-pサンプリングもまた、反復的な単語列の生成に苦しんでいるように見えます。
Welleck et al. (2019)では、人間の評価によると、モデルの学習目的を適応させた場合、Beam探索はTop-pサンプリングよりも流暢なテキストを生成できることを示しています。
オープンエンドの言語生成は急速に進化している研究分野であり、しばしばそうであるように、ここではワンサイズフィットオールの方法は存在しないので、自分の特定のユースケースで何が最もよく機能するかを見なければなりません。
良いことは、Transformersの中にある全ての異なる復号法を試してみることができるということです。
以上、Transformrsにおけるさまざまな復号法の使い方と、最近のオープンエンド言語生成の傾向についての簡単な紹介でした。
【おまけ】 generate()のパラメータ
generate()には、上記では触れていない追加パラメータがいくつかあります。簡単に説明します。
・min_length : min_lengthに達する前にモデルがEOSトークンを生成しないように強制するために使用することができます(=文を完成させない)。これは要約でよく使われますが、ユーザーがより長い出力をしたい場合には一般的に便利です。
・repetition_penalty : すでに生成された単語や文脈に属する単語にペナルティを与えるために使用することができます。これはKesker et al. (2019) によって最初に導入され、Welleck et al. (2019)の学習目的でも使用されています。反復防止にはかなり効果的ですが、異なるモデルやユースケースには非常に敏感なようで、例えばGithub上の議論を参照してください。
・attention_mask : パディングされたトークンをマスクするために使用することができます。
・pad_token_id, bos_token_id, eos_token_id : モデルがデフォルトでこれらのトークンを持っていない場合、ユーザーはそれらを表現するために他のトークンIDを手動で選択することができます。
詳細については、docstringを生成する関数も参照してください。
【おまけ】GPT2Tokenizerのスペシャルトークン
「GPT2Tokenizer」のスペシャルトークンは、以下で確認できます。
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.special_tokens_map{'bos_token': '<|endoftext|>',
'eos_token': '<|endoftext|>',
'unk_token': '<|endoftext|>'}'<|endoftext|>'がBOS(シーケンスの始まり)、EOS(シーケンスの終わり)、UNK(未知の語彙)に使われるスペシャルトークンであることがわかります。
次回
この記事が気に入ったらサポートをしてみませんか?