
Google Colab で StableCode を試す

「Google Colab」で「StableCode」を試したのでまとめました。
1. StableCode
「StableCode」は、「Stability AI」が開発したコーディング用LLMです。
2. StableCodeのモデル
次の3つのモデルを提供しています。
・stablecode-completion-alpha-3b-4k : ベースモデル
このモデルは、最大 4,000 トークンまでのコンテキストウィンドウから単一行または複数行のコード補完することを目的としています。BigCodeの「stack-dataset」 (v1.2) の多様なプログラミング言語セットで学習した後、 Python、Go、Java、JavaScript、C、Markdown、C++ などの一般的な言語でさらに学習しています。
・stablecode-instruct-alpha-3b : 指示モデル
モデルは、指示に従ってコードを生成することを目的としています。Alpaca形式の約 120,000 個のコード指示/応答ペアでベースモデルを指示ファインチューニングしています。
・stablecode-completion-alpha-3b : ロングコンテキストウィンドウモデル
このモデルは、最大 16,000 トークンまでのロングコンテキストウィンドウから単一行または複数行のコード補完することを目的としています。
平均サイズの5つのPythonコードを確認または編集できます。
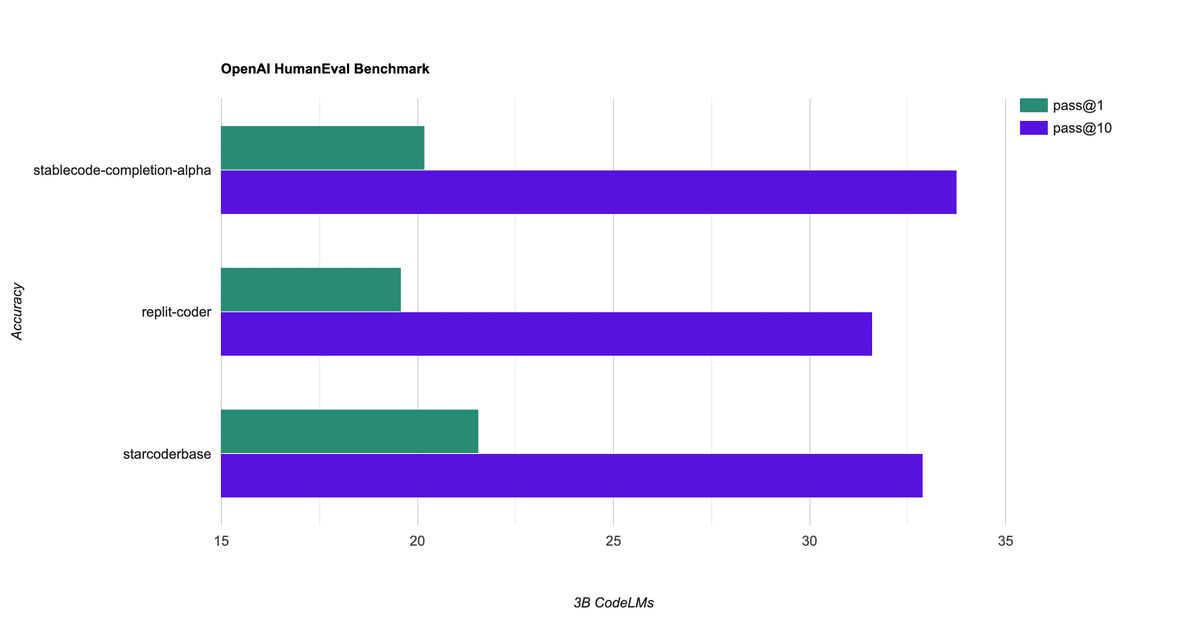
3. StableCodeの評価
以下は、同様の数のパラメータで学習された他のモデルと比較です。一般的な HumanEvalベンチマークで、標準のpass@1メトリクスと pass@10メトリクスを使用しています。

4. Colabでの実行
Colabでの指示モデルの実行手順は、次のとおりです。
(1) モデルカードのページでライセンスをAgree。

(2) Colabのノートブックを開いて、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(3) パッケージのインストール。
# パッケージのインストール
!pip install transformers accelerate bitsandbytes(4) HuggingFaceのログイン。
# HuggingFaceのログイン
!huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n) n
Token is valid (permission: read).
Your token has been saved to /root/.cache/huggingface/token
Login successful(5) トークナイザーとモデルの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"stabilityai/stablecode-instruct-alpha-3b"
)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablecode-instruct-alpha-3b",
trust_remote_code=True,
torch_dtype="auto",
).cuda()(6) 推論の実行。
# プロンプト
prompt = """###Instruction
Generate a python function to find number of CPU cores
###Response
"""
# 推論の実行
input_ids = tokenizer(prompt, return_tensors='pt').input_ids.cuda()
tokens = model.generate(
inputs=input_ids,
max_new_tokens=48,
temperature=0.2,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))###Instruction
Generate a python function to find number of CPU cores
###Response
def get_cpu_count():
"""
This function will return the number of CPU cores
installed on the system
"""
import multiprocessing
return multiprocessing.cpu_count()【翻訳】
###Instruction
CPU コアの数を見つけるための Python 関数を生成します。
###Response
def get_cpu_count():
"""
この関数は、システムにインストールされている CPU コアの数を返します。
"""
import multiprocessing
return multiprocessing.cpu_count()

この記事が気に入ったらサポートをしてみませんか?