
LlamaIndex の マルチモーダルRAG のしくみ

以下の記事が面白かったので、かるくまとめました。
1. マルチモーダルRAG
「OpenAI Dev Day」で最もエキサイティングな発表の1つは、「GPT-4V API」のリリースでした。「GPT-4V」は、テキスト/画像の両方を取り込み、テキスト応答を出力できるマルチモーダルモデルです。これにより、LLMが新しいステージに拡張されます。
過去1年、LLMアプリケーションスタックはテキストの入出力を中心に出現しました。最も注目された例の1つが「RAG」(検索拡張生成) です。LLMと外部テキストを組み合わせて、モデルが学習していないデータを推論できるようになります。
「RAG」がエンドユーザーにもたらした最も大きな影響の1つは、非構造化テキストデータの分析にかかる時間の短縮です。任意のドキュメント (PDF、Webページ) を処理し、ストレージにロードして、LLMのコンテキストウィンドウにフィードすることで、そこから必要な洞察を抽出できます。
「GPT-4V API」の導入により、「RAG」の概念をテキスト/画像のハイブリッドに拡張し、さらに大量の(画像を含む) データコーパスから価値を引き出すことができます。
2. マルチモーダルRAGのパイプライン
基本的なマルチモーダルRAGのパイプラインの流れは、次のとおりです。
・Input : 入力はテキストまたは画像。
・Retrieval :取得するコンテキストはテキストまたは画像。
・Synthesis : 回答はテキストまたは画像、あるいはその両方に合成。
・Response : 返す結果はテキストまたは画像、あるいはその両方。
3. マルチモーダルRAGの抽象化
「LlamaIndex」にマルチモーダルRAGの抽象化が導入され、次のことが可能になりました。
・マルチモーダルLLM
・マルチモーダル埋め込み
・マルチモーダルインデックス
3-1. マルチモーダルLLM
「OpenAIMultiModal」クラスで「GPT-4V」、「ReplicateMultiModal」クラスでオープンソースなマルチモーダルモデルをサポートします (現在Beta版のため、名前は変更される可能性があります)。
「SimpleDirectoryReader」は以前から音声、画像、動画を取り込むことができましたが、次のように「GPT-4V」に直接渡して質問できるようになりました。
from llama_index.multi_modal_llms import OpenAIMultiModal
from llama_index import SimpleDirectoryReader
image_documents = SimpleDirectoryReader(local_directory).load_data()
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview",
api_key=OPENAI_API_TOKEN,
max_new_tokens=300
)
response = openai_mm_llm.complete(
prompt="what is in the image?",
image_documents=image_documents
) 標準の「LLM」クラスとは異なり、「MultiModalLLM」は画像とテキストの両方を入力として取り込むことができます。

リソースは、次のとおりです。
今後の予定は、次のとおりです。
・より多くのマルチモーダルLLMの統合
・チャットエンドポイント
・ストリーミング
3-2. マルチモーダル埋め込み
テキストと画像の両方を埋め込むことができる「MultiModalEmbedding」を作成しました。これには、既存の埋め込みモデルのメソッドが含まれていますが、 get_image_embedding も含まれています。主な実装は、CLIPモデルを使用した「ClipEmbedding」になります。
今後の予定は、次のとおりです。
・より多くのマルチモーダル埋め込みの統合
3-3. マルチモーダルインデックス
「MultiModalVectorIndex」を作成しました。既存の (最も人気のある) 「VectorStoreIndex」とは異なり、テキストと画像の両方を保存できます。
画像のインデックス作成には、次のような別のプロセスが必要になります。
(1) CLIPを使用して画像を埋め込む
(2) 画像ノードを Base64 エンコードまたはパスとして表し、それをその埋め込みとともにベクトル データベースに保存 (テキストとは別のコレクション)
テキストと画像の両方が結果として返され、これらの結果を合成できます。
今後の予定は、次のとおりです。
・画像をベクター ストアに保存するためのよりネイティブな方法
・より柔軟なマルチモーダル検索の抽象化
・マルチモーダル応答合成の抽象化
4. ウォークスルー
4-1. マルチモーダルインデックスの作成
はじめに、ドキュメントをテキストと画像の組み合わせとして読み込みます。
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()次に、2つの別々のベクトルデータベースコレクション (テキストと画像) を定義します。
次に、「MultiModalVectorStoreIndex」を定義します。
# ローカル Qdrant ベクトルストア作成
client = qdrant_client.QdrantClient(path="qdrant_mm_db")
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
# マルチモーダルインデックスの作成
index = MultiModalVectorStoreIndex.from_documents(
documents, storage_context=storage_context, image_vector_store=image_store
)その後、マルチモーダルコーパスに対して質問をすることができます。
4-2. キャプショニング
最初の画像キャプションを入力としてコピー/ペーストし、検索拡張された出力を取得します。
retriever_engine = index.as_retriever(
similarity_top_k=3, image_similarity_top_k=3
)
# GPT-4Vのレスポンスから詳細情報を取得
retrieval_results = retriever_engine.retrieve(query_str)取得された結果には画像とテキストの両方が含まれます。

これを「GPT-4V」にフィードしてフォローアップの質問をしたり、一貫した応答を合成したりできます。
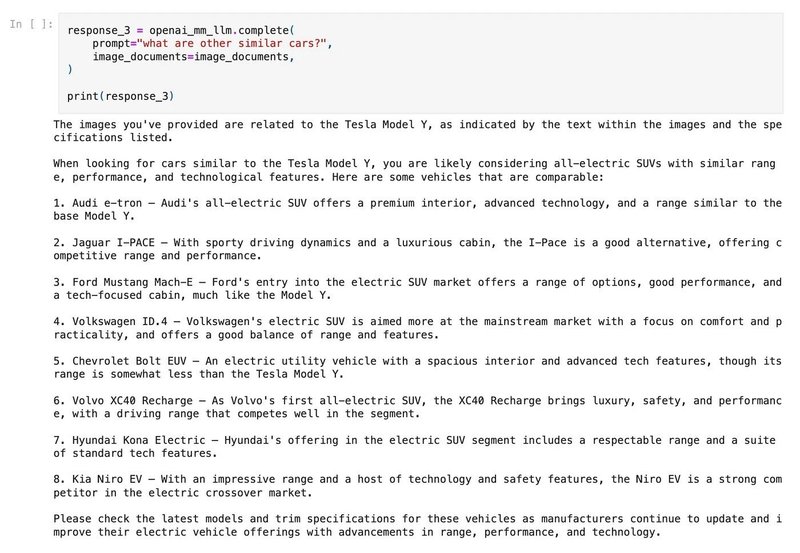
4-3. クエリ
ここで質問をして、マルチモーダルRAGパイプラインから応答を取得します。「SimpleMultiModalQueryEngine」は、最初に関連するテキスト/画像のセットを取得し、応答を合成するために入力をVisionモデルに供給します。
from llama_index.query_engine import SimpleMultiModalQueryEngine
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm,
text_qa_template=qa_tmpl
)
query_str = "Tell me more about the Porsche"
response = query_engine.query(query_str)結果は、次のとおりです。

リソースは、次のとおりです。
この記事が気に入ったらサポートをしてみませんか?