
LlamaIndex v0.6 クイックスタートガイド

「LlamaIndex v0.6」で大きな変更があったので更新しました。
・LlamaIndex v0.6
【最新版の情報は以下で紹介】
前回
1. LlamaIndex
「LlamaIndex」は、専門知識を必要とする質問応答チャットボットを簡単に作成できるライブラリです。同様のチャットボットは「LangChain」でも作成できますが、「LlamaIndex」は、コード数行で完成してお手軽なのが特徴になります。
2. ドキュメントの準備
はじめに、チャットボットに教える専門知識を記述したドキュメントを用意します。
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のあらすじのドキュメントを用意しました。
・bocchi.txt

3. Colabでの実行
Google Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install llama-index==0.6(2) 環境変数の準備。
以下のコードの <OpenAI_APIのトークン> にはOpenAI APIのトークンを指定します。(有料)
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIのトークン>"(3) ログレベルの設定。
ログレベルをINFOに設定します。
import logging
import sys
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)・DEBUG : デバッグ情報の出力。
・INFO : 想定通りのことが発生。
・WARNING : 想定外のことが発生。
・ERROR : 機能を実行できない。
(4) Colabにdataフォルダを作成してドキュメントを配置。
左端のフォルダアイコンでファイル一覧を表示し、右クリック「新しいフォルダ」でdataフォルダを作成し、ドキュメントをドラッグ&ドロップします。
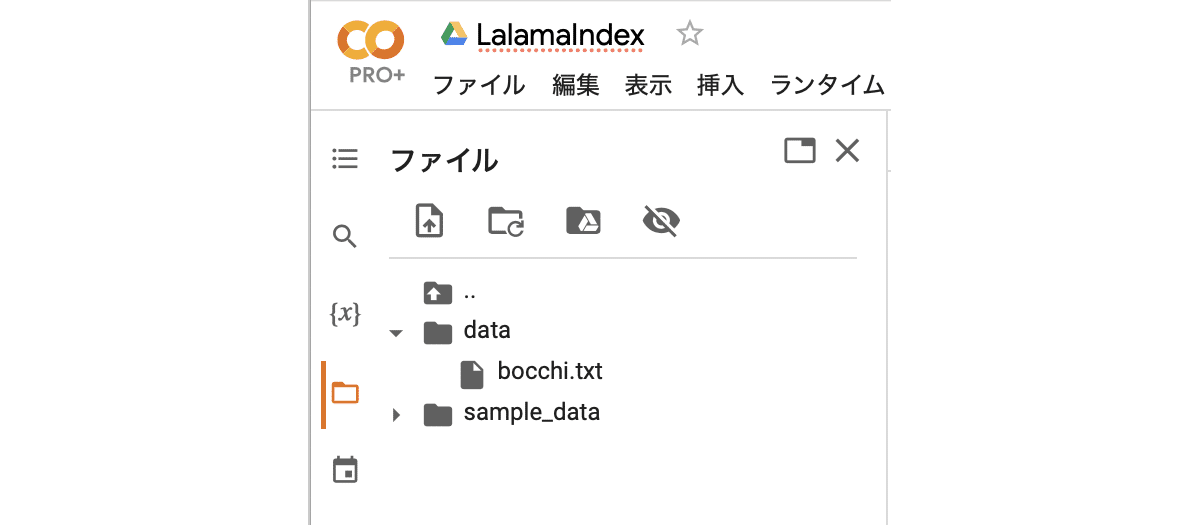
(5) インデックスの作成。
「インデックス」は、ドキュメントの情報を保持するモジュールです。
ドキュメントをチャンクに分割し、チャンク毎に埋め込みに変換して保持ます。チャンクは類似検索の対象となるデータ単位です。デフォルトでは、「\n\n」で分割した後、プロンプトに収まるサイズで結合しています。
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
# インデックスの作成
documents = SimpleDirectoryReader("data").load_data()
index = GPTVectorStoreIndex.from_documents(documents)> [build_index_from_nodes] Total LLM token usage: 0 tokens
> [build_index_from_nodes] Total embedding token usage: 15033 tokens使用されたLLMと埋め込みのトークン数が情報として出力されます。
(5) クエリエンジンの作成。
「クエリエンジン」は、ユーザー入力(クエリ)と関連する情報をインデックスから取得し、それをもとに応答を生成するモジュールです。
# クエリエンジンの作成
query_engine = index.as_query_engine()(5) 質問応答。
# 質問応答
print(query_engine.query("ぼっちちゃんの得意な楽器は?"))ぼっちちゃんの得意な楽器はギターです。4. インデックスの保存
作成したインデックスは保存しておくと、次回に再作成する必要がなくなります。
(1) インデックスの保存。
# インデックスの保存
index.storage_context.persist()(2) インデックスの読み込み。
from llama_index import StorageContext, load_index_from_storage
# インデックスの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)5. LlamaHub
「LlamaIndex」がドキュメントとして読み込めるのは、テキストだけではありません。「LlamaHub」で提供しているデータコネクタを利用することで、さまざまなファイル (PDF、ePub、Word、PowerPoint、Audioなど) やWebサービス (Twitter、Slack、Wikipediaなど) をドキュメントのデータソースとして利用できます。
今回は、「Fast Zero Shot Object Detection with OpenAI CLIP」のYoutube動画についてLlamaIndexで質問応答してみます。
(1) 「LlamaHub」で目的のデータコネクタを探す。
今回は、「youtube_transcript」をクリックします。

(2) サンプルコードを元に、ドキュメントを読み込む。
from llama_index import download_loader
YoutubeTranscriptReader = download_loader("YoutubeTranscriptReader")
loader = YoutubeTranscriptReader()
documents = loader.load_data(ytlinks=['https://www.youtube.com/watch?v=i3OYlaoj-BM'])(3) インデックスとクエリエンジンの作成。
from llama_index import GPTVectorStoreIndex
# インデックスの作成
index = GPTVectorStoreIndex.from_documents(documents)
# クエリエンジンの作成
query_engine = index.as_query_engine()(4) 質問応答。
日本語で答えてくれない時は、「日本語で答えて」をつけると良いです。
# 質問応答
print(query_engine.query("この動画で伝えたいことはなんですか?日本語で答えて"))この動画では、オープンAIのCLIPを使用して、画像分類、オブジェクトローカリゼーション、オブジェクト検出をゼロショットで行う方法を紹介しています。また、これらのタスクを切り替えるためにモデルを微調整する必要がないことも示しています。さらに、スコアを計算し、画像全体の平均を取り、それを現在のスコアから引くことで、低いスコアをゼロにクリップする方法も紹介しています。これにより、より良いローカリゼーシ