Google Colab で heron-blip-v1 を試す

「Google Colab」で「heron-blip-v1」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. heron-blip-v1
「Heron」はチューリングが開発した日本語を含む複数言語対応の大規模マルチモーダル学習ライブラリです。「heron-blip-v1」は、Heronで学習した日本語Vision Languageモデルの高性能版になります。
2. heron-blip-v1 のモデル
heron-blip-v1のモデルは、次の2種類です。
・turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1-llava-620k : LLaVA-Instruct-620K-JA で学習
・turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1 : LLaVA-Instruct-150K-JAで学習
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/turingmotors/heron.git
%cd heron
!pip install -r requirements.txt(3) モデルの準備。
「"turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1-llava-620k」を使用しました。
import torch
from heron.models.video_blip import VideoBlipForConditionalGeneration
# モデルの準備
model = VideoBlipForConditionalGeneration.from_pretrained(
""turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1-llava-620k",
torch_dtype=torch.float16,
ignore_mismatched_sizes=True
)
model = model.half()
model.eval()
model.to("cuda:0")「modeling_video_blip.py」の325行目で以下のエラーがでました。

以下のように修正して、メニュー「ランタイム→セッションを再起動」で再起動して、「%cd heron」で元に場所に戻しました。
if module.bias is not None: # biasがNoneでないことを確認
module.bias.data.zero_()
if module.weight is not None: # 念のためweightも確認
module.weight.data.fill_(1.0)(4) プロセッサの準備。
from heron.models.video_blip import VideoBlipProcessor
from transformers import LlamaTokenizer
# プロセッサの準備
processor = VideoBlipProcessor.from_pretrained(
"Salesforce/blip2-opt-2.7b"
)
tokenizer = LlamaTokenizer.from_pretrained(
"novelai/nerdstash-tokenizer-v1",
additional_special_tokens=['▁▁']
)
processor.tokenizer = tokenizer(5) 推論の実行。
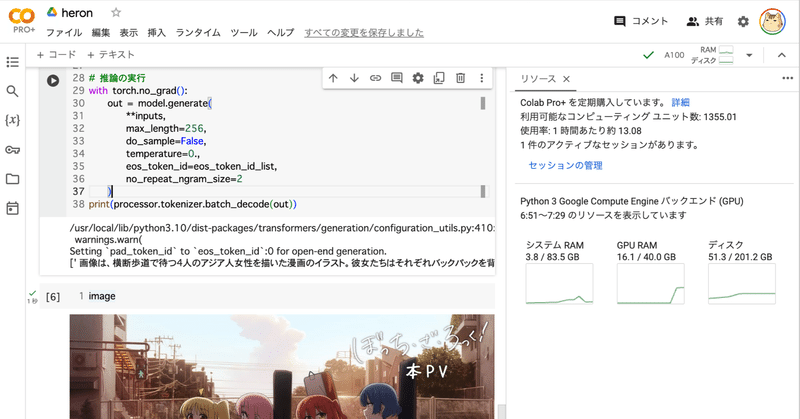
画像のURLは公式のぼっち画像、プロンプトは「##human: この画像を説明してください\n##gpt: 」としています。
import requests
from PIL import Image
# 入力画像の準備
url = "https://img.youtube.com/vi/1-o7fmQqSNg/maxresdefault.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# プロンプトの準備
text = "##human: この画像を説明してください\n##gpt: "
# 前処理の実行
inputs = processor(
text=text,
images=image,
return_tensors="pt",
truncation=True,
)
inputs = {k: v.to("cuda:0") for k, v in inputs.items()}
inputs["pixel_values"] = inputs["pixel_values"].to("cuda:0", torch.float16)
# EOSトークンの準備
eos_token_id_list = [
processor.tokenizer.pad_token_id,
processor.tokenizer.eos_token_id,
int(tokenizer.convert_tokens_to_ids("##"))
]
# 推論の実行
with torch.no_grad():
out = model.generate(
**inputs,
max_length=256,
do_sample=False,
temperature=0.,
eos_token_id=eos_token_id_list,
no_repeat_ngram_size=2
)
print(processor.tokenizer.batch_decode(out))
[' 画像は、横断歩道で待つ4人のアジア人女性を描いた漫画のイラスト。彼女たちはそれぞれバックパックを背負い、ハンドバッグを持っている。背景には、道路脇の歩道に駐車している車が見える。さらに、画像の右側には自転車が写っており、この地域にさまざまな交通手段があることを示している。\n<|pad|>']
この記事が気に入ったらサポートをしてみませんか?