Google Colab + trl で Falcon-7B のQLoRAファインチューニングを試す

「Google Colab」で「Falcon-7B」のQLoRAファインチューニングを試したのでまとめました。
【注意】「Google Colab Pro/Pro+」で使えるA100で動作確認してます。
1. trl v0.4.2
「QLoRA」(bitsandbytesによる4bit量子化)を使用した大規模モデルの学習、新クラス「RewardTrainer」「SFTTrainer」を含むTRLの新バージョンで、「RLHF」をエンドツーエンドで簡単に実行可能になりました。
「trl v0.4.2」を使って「Falcon-7B」をQLoRAファインチューニングしてみます。サンプルColabも提供されてました。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」で「A100」を選択。
(2) パッケージのインストール。
「SFTTrainer」を利用するため「accelerate」「peft」「transformers」「datasets」、「4-bit量子化」を利用するため「bitsandbytes」、「Falcon」を読み込むため「einops」をインストールします。
# パッケージのインストール
!pip install -q -U git+https://github.com/lvwerra/trl.git git+https://github.com/huggingface/transformers.git git+https://github.com/huggingface/accelerate.git git+https://github.com/huggingface/peft.git
!pip install -q datasets bitsandbytes einops wandb(3) データセットの準備。
今回は、汎用チャットAIの学習に適した「OpenAssistant」のサブセットである「Guanaco」を使用します。
from datasets import load_dataset
# データセットの準備
dataset_name = "timdettmers/openassistant-guanaco"
dataset = load_dataset(dataset_name, split="train")(4) モデルの準備。
「Falcon 7B」を読み込み、4-bit量子化(load_in_4bit=True)し、LoRAアダプタを接続します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoTokenizer
# モデルの準備
model_name = "ybelkada/falcon-7b-sharded-bf16"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True
)
model.config.use_cache = False(5) トークナイザーの準備。
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token(6) LoRAパラメータの準備。
「QLoRA」の論文によると、パフォーマンスを最大化するには、Transformerブロック内のすべてのlinear層を考慮することが重要です。そこで、mixed query key value層に加えて、ターゲットモジュールにdense、dense_h_to_4_h、dense_4h_to_h層を追加します。
from peft import LoraConfig
# LoRAパラメータの準備
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
]
)(7) トレーナーパラメータの準備。
from transformers import TrainingArguments
# トレーナーパラメータの準備
output_dir = "./results"
per_device_train_batch_size = 4
gradient_accumulation_steps = 4
optim = "paged_adamw_32bit"
save_steps = 10
logging_steps = 10
learning_rate = 2e-4
max_grad_norm = 0.3
max_steps = 500
warmup_ratio = 0.03
lr_scheduler_type = "constant"
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
)(8) 学習の実行。
transformersのトレーナーのラッパーを提供する「trl」の「SFTTrainer」を使用します。
from trl import SFTTrainer
# トレーナーの準備
max_seq_length = 512
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
)(9) 「wandb」のAPIキーを求められるので入力します。
学習完了まで35分ほどかかりました。

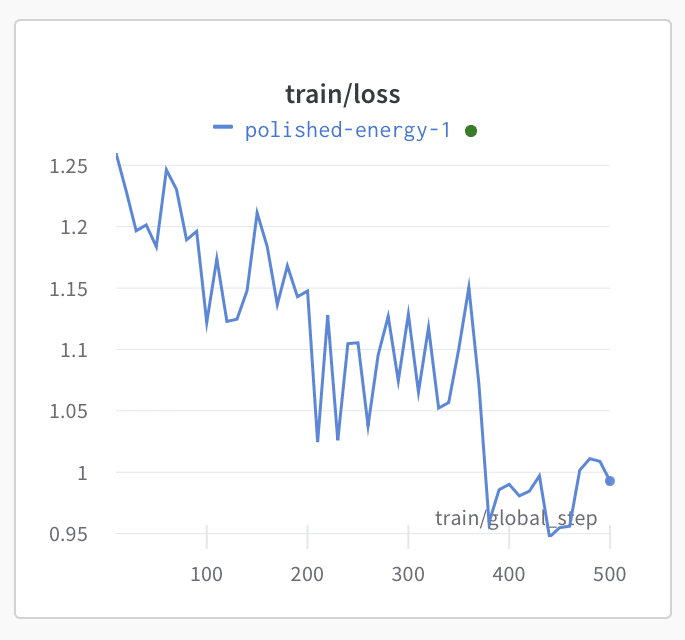
(10) 「wandb」で、lossが収束されている (正常に学習されているっぽい) ことを確認します。
【おまけ】パラメータ
SFTTrainer のパラメータ
・model (Union[transformers.PreTrainedModel, nn.Module, str])
学習用のモデル
・args (Optionaltransformers.TrainingArguments)
学習用のパラメータ
・data_collator (Optionaltransformers.DataCollator)
学習のデータコレータ
・train_dataset (Optionaldatasets.Dataset)
学習用のデータセット。ConstantLengthDataset 推奨
・eval_dataset (Optional[Union[datasets.Dataset, Dict[str, datasets.Dataset]]])
評価用のデータセット。ConstantLengthDataset 推奨
・tokenizer (Optionaltransformers.PreTrainedTokenizer)
学習用のトークナイザー。未指定時はモデルに関連付けられたトークナイザーを利用
・model_init (Callable[[], transformers.PreTrainedModel])
学習用のモデル初期化子
・compute_metrics (Callable[[transformers.EvalPrediction], Dict], optional defaults to compute_accuracy)
評価用のメトリック
・callbacks (List[transformers.TrainerCallback])
学習用のコールバック
・optimizers (Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR])
学習用のオプティマイザとスケジューラ
・preprocess_logits_for_metrics (Callable[[torch.Tensor, torch.Tensor], torch.Tensor])
メトリクス計算前にロジットを前処理するために使用する関数
・peft_config (Optional[PeftConfig])
PeftModelの初期化に使用するパラメータ
・dataset_text_field (Optional[str])
データセットのテキストフィールドの名。指定時は、dataset_text_fieldにもとづいて ConstantLengthDataset を自動的作成
・formatting_func (Optional[Callable])
ConstantLengthDataset の作成に使用される書式設定関数
・max_seq_length (Optional[int])
ConstantLengthDataset およびデータセットの自動作成に使用する最大シーケンス長 (デフォルト:512)
・infinite (Optional[bool])
無限のデータセットを使用するかどうか (デフォルト:False)
・num_of_sequences (Optional[int])
ConstantLengthDataset に使用するシーケンス数 (デフォルト:1024)
・chars_per_token (Optional[float])
ConstantLengthDataset に使用するトークンあたりの文字数 (デフォルト:3.6)
・packing (Optional[bool])
dataset_text_field が渡される場合のみ使用。データセットのシーケンスをパックするために ConstantLengthDataset によって使用される
TrainingArguments のパラメータ
・output_dir (str)
出力フォルダのパス (モデルのpredictionsとcheckpointsを出力)
・overwrite_output_dir (bool, optional, defaults to False)
Trueの場合、出力フォルダの内容を上書
・do_train (bool, optional, defaults to False)
学習を実行するかどうか (Trainer以外で利用)
・do_eval (bool, optional)
評価を実行するかどうか (Trainer以外で利用)
・do_predict (bool, optional, defaults to False)
予測を実行するかどうか (Trainer以外で利用)
・evaluation_strategy (str or IntervalStrategy, optional, defaults to "no")
学習中に採用する評価戦略 ("no", "steps", "epoch")
・prediction_loss_only (bool, optional, defaults to False)
評価を実行して予測を生成する場合、損失のみが返す
・per_device_train_batch_size (int, optional, defaults to 8)
学習の GPU/TPU core/CPU 毎のバッチサイズ
・per_device_eval_batch_size (int, optional, defaults to 8)
評価の GPU/TPU core/CPU 毎のバッチサイズ
・gradient_accumulation_steps (int, optional, defaults to 1)
backward/updateパスを実行する前に勾配を蓄積する更新ステップ数
・eval_accumulation_steps (int, optional)
結果をCPUに移動する前に、出力テンソルを蓄積する予測ステップ数
・eval_delay (float, optional)
評価戦略に応じて、最初の評価を実行する前に待機するエポック数 / ステップ数
・learning_rate (float, optional, defaults to 5e-5)
AdamWオプティマイザの初期学習率
・weight_decay (float, optional, defaults to 0)
AdamWオプティマイザのすべてのバイアスおよびLayerNorm重みを除くすべてのレイヤーに適用する重み減衰
・adam_beta1 (float, optional, defaults to 0.9)
AdamWオプティマイザのbeta1ハイパーパラメータ
・adam_beta2 (float, optional, defaults to 0.999)
AdamWオプティマイザのbeta2ハイパーパラメータ
・adam_epsilon (float, optional, defaults to 1e-8)
AdamWオプティマイザのepsilonハイパーパラメータ
・max_grad_norm (float, optional, defaults to 1.0)
最大勾配ノルム (勾配クリッピング用)
・num_train_epochs (float, optional, defaults to 3.0)
学習エポック数
・max_steps (int, optional, defaults to -1)
学習ステップ数
・lr_scheduler_type (str or SchedulerType, optional, defaults to "linear")
スケジューラ種別
・warmup_ratio (float, optional, defaults to 0.0)
0からlearning_rateまでの線形ウォームアップに使用される学習ステップの合計比率
・warmup_steps (int, optional, defaults to 0)
0からlearning_rateまでの線形ウォームアップに使用されるステップ数
・log_level (str, optional, defaults to passive)
ログレベル ("debug", "info", "warning", "error", "critical", "passive")
・log_level_replica (str, optional, defaults to "warning")
replicaで使用するログレベル
・logging_dir (str, optional)
TensorBoard のログディレクトリ
・logging_strategy (str or IntervalStrategy, optional, defaults to "steps")
学習中に採用するロギング戦略 ("no", "steps", "epoch")
・logging_first_step (bool, optional, defaults to False)
最初の global_step をログに記録して評価するかどうか
・logging_steps (int or float, optional, defaults to 500)
logging_strategy="steps" の場合、2 つのログ間の更新ステップの数
・logging_nan_inf_filter (bool, optional, defaults to True)
ロギング用に nan および inf 損失をフィルタリングするかどうか。
・save_strategy (str or IntervalStrategy, optional, defaults to "steps")
学習中に採用するチェックポイント保存戦略 ("no", "steps", "epoch")
・save_steps (int or float, optional, defaults to 500)
save_strategy="steps" の場合、2つのチェックポイントが保存されるまでの更新ステップ数
・save_total_limit (int, optional)
保存するチェックポイントの最大数
・save_safetensors (bool, optional, defaults to False)
デフォルトの torch.load と torch.save の代わりに、state dictsのsafetensorsの保存とロードを使用
・no_cuda (bool, optional, defaults to False)
CUDA が使用可能な場合でも使用しないかどうか
・seed (int, optional, defaults to 42)
乱数シード
・data_seed (int, optional)
データサンプラーで使用される乱数シード
・jit_mode_eval (bool, optional, defaults to False)
推論に PyTorch JITトレースを使用するかどうか
・use_ipex (bool, optional, defaults to False)
PyTorch用のIntel拡張機能が利用可能な場合は、それを使用
・bf16 (bool, optional, defaults to False)
2-bit学習の代わりに bf16 16-bit (mixed) precision学習を使用するかどうか
・fp16 (bool, optional, defaults to False)
32-bit学習の代わりに fp16 16-bit (mixed) precision学習を使用するかどうか
・fp16_opt_level (str, optional, defaults to "O1")
fp16学習の場合、Apex AMP 最適化レベルは ["O0","O1","O2", "O3"] で選択される
・fp16_backend (str, optional, defaults to "auto")
非推奨
・half_precision_backend (str, optional, defaults to "auto")
(mixed) precision学習をに使用するバックエンド ("auto", "cuda_amp", "apex", "cpu_amp")
・bf16_full_eval (bool, optional, defaults to False)
32-bitの代わりに完全な bfloat16 評価を使用するかどうか
・tf32 (bool, optional)
Ampere以降のGPU アーキテクチャで利用可能なTF32モードを有効にするかどうか
・tpu_num_cores (int, optional)
TPUコアの数
・dataloader_drop_last (bool, optional, defaults to False)
最後の不完全なバッチを削除するかどうか (データセットの長さがバッチサイズで割り切れない場合)
・eval_steps (int or float, optional)
Evaluation_strategy="steps" の場合、2つの評価間の更新ステップ数
・dataloader_num_workers (int, optional, defaults to 0)
データのロードに使用するサブプロセスの数 (PyTorch のみ)
・past_index (int, optional, defaults to -1)
TransformerXL や XLNet などの一部のモデルは、予測に過去の隠れた状態を利用できる
・run_name (str, optional)
runの名前
・disable_tqdm (bool, optional)
Jupyter Notebooksに生成されるtqdmプログレスバーとメトリクスのテーブルを無効にするかどうか
・remove_unused_columns (bool, optional, defaults to True)
モデルフォワードメソッドで使用されていない列を自動的に削除するかどうか
・label_names (List[str], optional)
ラベルに対応する入力の辞書内のキーのリスト
・load_best_model_at_end (bool, optional, defaults to False)
学習中に見つかった最適なモデルをトレーニングの終了時にロードするかどうか
・metric_for_best_model (str, optional)
2つの異なるモデルを比較するために使用するメトリックを指定するには、load_best_model_at_end と組み合わせて使用
・greater_is_better (bool, optional)
load_best_model_at_end および metric_for_best_model と組み合わせて使用して、より優れたモデルにはより大きなメトリックが必要かどうかを指定
・ignore_data_skip (bool, optional, defaults to False)
学習再開時に、エポックとバッチをスキップして、前の学習と同じ段階でデータの読み込みを取得するかどうか
・deepspeed (str or dict, optional)
deepspeedの利用
・label_smoothing_factor (float, optional, defaults to 0.0)
使用するラベルの平滑化係数
・debug (str or list of DebugOption, optional, defaults to "")
デバッグ機能の有効化 ("underflow_overflow", "tpu_metrics_debug")
・optim (str or training_args.OptimizerNames, optional, defaults to "adamw_hf")
使用するオプティマイザ (adamw_hf, adamw_torch, adamw_torch_fused, adamw_apex_fused, adamw_anyprecision, adafactor)
・optim_args (str, optional)
AnyPrecisionAdamWに提供されるオプションの引数
・group_by_length (bool, optional, defaults to False)
学習データセット内のほぼ同じ長さのサンプルをグループ化するかどうか
・length_column_name (str, optional, defaults to "length")
事前計算された長さの列名
・report_to (str or List[str], optional, defaults to "all")
結果とログをレポートするIntegrationのリスト ("azure_ml", "comet_ml", "mlflow", "neptune", "tensorboard","clearml", "wandb")
・dataloader_pin_memory (bool, optional, defaults to True)
データローダーにメモリを固定するかどうか。デフォルトはTrue
・skip_memory_metrics (bool, optional, defaults to True)
メモリプロファイラーレポートのメトリックへの追加をスキップするかどうか
・resume_from_checkpoint (str, optional)
モデルの有効なチェックポイントが含まれるフォルダへのパス
・gradient_checkpointing (bool, optional, defaults to False)
Trueの場合、勾配チェックポイントを使用して、バックワードパスが遅くなる代わりにメモリを節約
・include_inputs_for_metrics (bool, optional, defaults to False)
CUDAのメモリ不足エラーを回避して、指数関数的な減衰を通じて自動的にメモリに収まるバッチサイズを見つけるかどうか
・auto_find_batch_size (bool, optional, defaults to False)
CUDAのメモリ不足エラーを回避して、指数関数的な減衰を通じて自動的にメモリに収まるバッチサイズを見つけるかどうか
・ddp_backend (str, optional)
分散学習に使用するバックエンド ("nccl", "mpi", "ccl", "gloo")
・ddp_find_unused_parameters (bool, optional)
分散学習を使用する場合、フラグ find_unused_parameters の値が DistributedDataParallel に渡される
・ddp_bucket_cap_mb (int, optional)
分散学習を使用する場合、フラグ Bucket_cap_mb の値が DistributedDataParallel に渡される
・sharded_ddp (bool, str or list of ShardedDDPOption, optional, defaults to False)
FairScale のSharded DDP学習を使用 ("simple", "zero_dp_2", "zero_dp_3", "offload")
・fsdp (bool, str or list of FSDPOption, optional, defaults to False)
PyTorch分散並列学習を使用 ("full_shard", "shard_grad_op", "offload", "auto_wrap")
・fsdp_config (str or dict, optional)
fsdp (Pytorch Distributed Parallel Training) で使用される構成
・fsdp_min_num_params (int, optional, defaults to 0): FSDP’s minimum number of parameters for Default Auto Wrapping. (useful only when fsdp field is passed).
デフォルトの自動ラッピングのパラメータ ("backward_pre", "backward_post")
・fsdp_forward_prefetch (bool, optional, defaults to False)
FSDPの前方プリフェッチモード
・local_rank (int, optional, defaults to -1)
分散学習中のプロセスのランク
・log_on_each_node (bool, optional, defaults to True)
マルチノード分散学習で、ノードごとに1回ログレベルを使用してログを記録するか、メインノード上でのみログを記録するか
・save_on_each_node (bool, optional, defaults to False)
マルチノード分散学習を実行する場合、モデルとチェックポイントを各ノードに保存するか、メインノードにのみ保存するか
・full_determinism (bool, optional, defaults to False)
Trueの場合、分散学習で再現可能な結果を保証するために、set_seed() の代わりにenable_full_determinism() が呼び出される
・push_to_hub (bool, optional, defaults to False)
モデルが保存されるたびにモデルをHubにPushするかどうか
・hub_model_id (str, optional)
ローカルのoutput_dirとの同期を保つリポジトリ名
・hub_strategy (str or HubStrategy, optional, defaults to "every_save")
Hubに何をいつPushするかの範囲を定義
・hub_token (str, optional)
モデルをHubにPushするために使用するトークン
・hub_private_repo (bool, optional, defaults to False)
Trueの場合、Hubリポジトリをプライベートに設定
・torchdynamo (str, optional)
TorchDynamoのバックエンドコンパイラ ("eager", "aot_eager", "inductor", "nvfuser", "aot_nvfuser", "aot_cudagraphs", "ofi", "fx2trt", "onnxrt", "ipex")
・ray_scope (str, optional, defaults to "last")
Rayでハイパーパラメータ検索を行うときに使用するスコープ
・ddp_timeout (int, optional, defaults to 1800)
torch.distributed.init_process_group 呼び出しのタイムアウト
・use_mps_device (bool, optional, defaults to False)
Apple Silicon チップベースの mps デバイスを使用するかどうか
・torch_compile (bool, optional, defaults to False)
PyTorch 2.0 torch.compile を使用してモデルをコンパイルするかどうか
・torch_compile_backend (str, optional)
torch.compile で使用するバックエンド
・torch_compile_mode (str, optional)
torch.compile で使用するモード
LoraConfig のパラメータ
・r (int)
low-rank行列の次元数。この値が小さいと、更新行列が小さくなり、学習可能なパラメーターが少なくなる
・lora_alpha (int)
low-rank行列のスケーリングファクター。大きいほどLoRAが活性化
・lora_dropout (float)
LoRAレイヤーのドロップアウト確率。学習時にランダムに一部のノードを無効にすることで汎化性能向上。
・task_type (Union[str, peft.utils.config.TaskType] = None)
タスク種別 (CAUSAL_LM)
・target_modules (Union[List[str],str])
LoRAを適用するモジュールの名前
・bias (str)
LoRAのバイアス種別 ("none", "all", "lora_only")
・fan_in_fan_out (bool)
置換レイヤーが (fan_in, fan_out) のような重みを保存かどうか
・modules_to_save (List[str])
保存するLoRAレイヤー以外のモジュールのリスト
・layers_to_transform (Union[List[int],int])
LoRAによって変換されるレイヤーのリスト。指定しない場合、target_modules 内のすべてのレイヤーが変換される
・layers_pattern (str)
layers_to_transformが指定されている場合、target_modulesのレイヤー名と一致させるためのパターン
関連
この記事が気に入ったらサポートをしてみませんか?