
MediaPipeを使用したモバイルデバイスでのリアルタイム3D物体検出

以下の記事を参考に書いてます。
・Real-Time 3D Object Detection on Mobile Devices with MediaPipe
1. はじめに
「物体検出」は、広く研究されているコンピュータービジョンのタスクですが、ほとんどの研究は「2D予測」に焦点を当てています。「2D予測」は2Dバウンディングボックスのみを提供しますが、「3D予測」に拡張することで、世界の物体のサイズ、位置、方向をキャプチャでき、ロボット工学、自動運転車、画像検索、拡張現実などさまざまなアプリケーションにつながります。「2D物体検出」は比較的成熟しており、業界で広く使用されていますが、「2D画像からの3D物体検出」は、データの欠如と、カテゴリ内のオブジェクトの外観と形状の多様性のため、難しいタスクになっています。
本日、私たちは、日常オブジェクト用のモバイルリアルタイム3D物体検出パイプライン「MediaPipe Objectron」をリリースしました。このパイプラインは、「2D画像内の物体」を検出し、新規作成した3Dデータセットで訓練された機械学習モデルを介して「位置」「方向」「サイズ」を推定します。マルチモーダル知覚パイプラインを構築するためのライブラリ「MediaPipe」に実装された「Objectron」は、モバイルデバイス上で物体の3Dバウンディングボックスをリアルタイムに計算します。

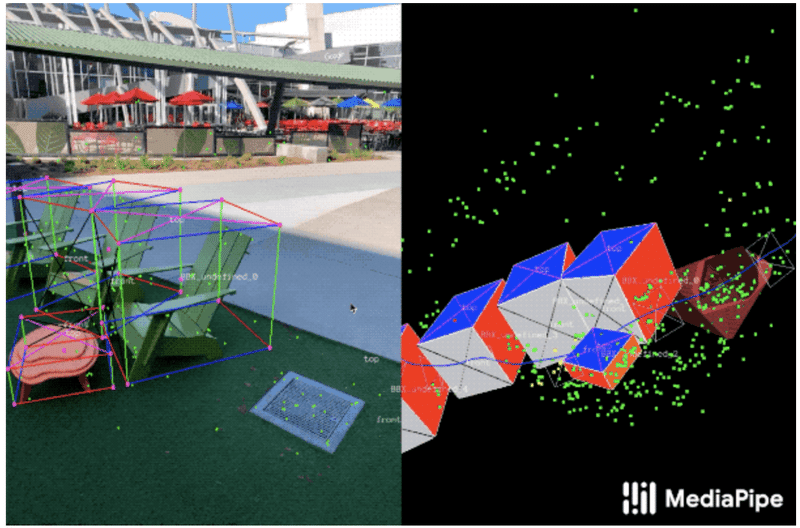
単一画像からの3D物体検出。 「MediaPipe Objectron」は、モバイルデバイスでリアルタイムに日常のオブジェクトの位置、方向、サイズを推定。
2. 実世界の3D訓練データの取得
「LIDAR」のような3Dキャプチャセンサーに依存する自動運転車の研究が普及しているため、ストリートシーンの3Dデータは十分にありますが、日常オブジェクト用のグランドトゥルース3D注釈付きのデータセットは非常に限られています。この問題を克服するために、モバイル拡張現実(AR)を使った新しいデータパイプラインを開発しました。「ARCore」「ARKit」の登場により、数億台のスマートフォンにAR機能が追加され、ARセッション中にカメラ位置、3Dポイントクラウド、推定照明、平面などの情報をキャプチャできるようになりました。
グランドトゥルースデータにラベルを付けるために、ARセッションデータで使用する新しい注釈ツールを作成しました。これにより、アノテーターは物体の3Dバウンディングボックスにすばやくラベルを付けることができます。
このツールは、分割画面ビューを使用して、左側に3Dバウンディングボックスがオーバーレイされた2Dビデオフレームを表示し、右側に3Dポイントクラウド、カメラ位置、平面を示すビューを表示します。アノテーターは、3Dビューに3Dバウンディングボックスを描画し、2Dビデオフレームの投影を確認してその位置を確認します。静的オブジェクトの場合、単一のフレーム内のオブジェクトに注釈を付け、ARセッションデータからのグランドトゥルースカメラポーズを使用して、その位置をすべてのフレームに伝播するだけでよく、作業が非常に効率的になります。
3D物体検出用の実世界のデータ注釈。
右:3Dバウンディングボックスは、検出されたサーフェスとポイントクラウドで3D世界に注釈が付けられている。
左:注釈付き3Dバウンディングボックスの投影がビデオフレームの上にオーバーレイされ、注釈の検証が容易になる。
3. AR合成データ生成
一般的なアプローチは、予測の精度を高めるために、実世界のデータを合成データで補完することです。ただし、そうしようとすると、貧弱で非現実的なデータが生成されることが多く、写真のようにリアルなレンダリングの場合は、多大な労力と計算が必要になります。
「AR Synthetic Data Generation」と呼ばれる当社の新しいアプローチは、仮想オブジェクトをARセッションデータを持つシーンに配置します。これにより、カメラポーズ、検出された平面、推定照明を活用して、物理的に可能性が高く、シーンに一致する照明を備えた配置を生成できます。
このアプローチにより、シーンのジオメトリを尊重し、実際の背景にシームレスに適合するレンダリングされたオブジェクトを持つ高品質の合成データが得られます。実世界のデータとAR合成データを組み合わせることで、精度を約10%向上させることができます。

AR合成データ生成の例。 仮想の白茶色のシリアルボックスは、実際の青い本の横にある実際のシーンにレンダリングされる。
4. 3D物体検出用のMLパイプライン
単一画像から物体の「位置」「方向」「サイズ」を予測するための単一ステージモデルを構築しました。モデルのバックボーンには、MobileNetv2上に構築されたエンコーダーデコーダーアーキテクチャーがあります。マルチタスク学習アプローチを採用し、検出と回帰によりオブジェクトの形状を予測します。形状タスクは、利用可能なグランドトゥルースアノテーションに応じて、オブジェクトの形状信号を予測します。訓練データに形状注釈がない場合、これはオプションです。検出タスクでは、注釈付きのバウンディングボックスを使用して、ボックスの重心に中心を置き、ボックスサイズに比例する標準偏差で、ガウスをボックスに合わせます。検出の目標は、この分布を予測し、そのピークがオブジェクトの中心位置を表すことです。回帰タスクは、8つのバウンディングボックスの頂点の2D投影を推定します。バウンディングボックスの最終的な3D座標を取得するには、確立されたポーズ推定アルゴリズム(EPnP)を活用します。オブジェクトの大きさを事前に知らなくても、物体の3Dバウンディングボックスを復元できます。3Dバウンディングボックスがあれば、物体のポーズとサイズを簡単に計算できます。下の図は、ネットワークアーキテクチャと後処理を示しています。このモデルは、モバイルデバイス(Adreno 650モバイルGPUで26 FPS)でリアルタイムに実行できるほど軽量です。
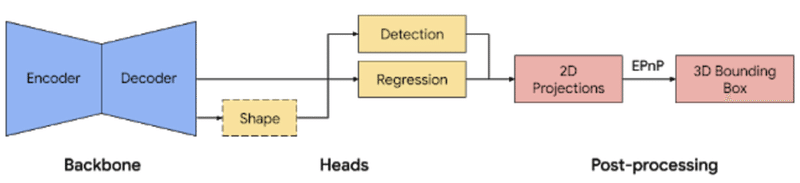
ネットワークアーキテクチャと3Dオブジェクト検出のための後処理。

ネットワークのサンプル結果。
左 : 推定境界ボックス付きの元の2D画像。
中央 : ガウス分布によるオブジェクト検出。
右 : 予測セグメンテーションマスク。
5. MediaPipeでの検出と追跡
モデルがモバイルデバイスによってキャプチャされたすべてのフレームに適用されると、各フレームで推定された3Dバウンディングボックスのあいまいさが原因で、ジッタの影響を受ける可能性があります。これを軽減するために、2Dオブジェクト検出および追跡ソリューションで、最近リリースされた検出+追跡フレームワークを採用しています。このフレームワークは、すべてのフレームでネットワークを実行する必要性を軽減し、モバイルデバイスでパイプラインをリアルタイムに保ちながら、より重い(正確な)モデルを使用できるようにします。また、フレーム全体で物体の同一性を保持し、予測が時間的に一貫していることを保証し、ジッタを削減します。
モバイルパイプラインの効率をさらに高めるために、数フレームごとに1回だけモデル推論を実行します。次に、以前のブログで説明したインスタントモーショントラッキングとモーション静止画を使用して、予測を取得し、時間をかけて追跡します。新しい予測が行われると、重複領域に基づいて検出結果と追跡結果を統合します。
研究者と開発者が当社のパイプラインに基づいて実験およびプロトタイプを作成できるように、エンドツーエンドのデモモバイルアプリケーションと2つのカテゴリ(靴と椅子)のトレーニング済みモデルを含む、デバイス上のMLパイプラインを「MediaPipe」でリリースしています。幅広い研究開発コミュニティとソリューションを共有することで、新しいユースケース、新しいアプリケーション、新しい研究努力が促進されることを願っています。将来的には、モデルをさらに多くのカテゴリに拡大し、デバイス上のパフォーマンスをさらに向上させる予定です。

3Dオブジェクト検出の例。
この記事が気に入ったらサポートをしてみませんか?