
オンデバイス マシン インテリジェンス

以下の記事が面白かったので、ざっくり訳しました。
・On-Device Machine Intelligence
1. はじめに
「会話の理解」「画像認識」を可能にする最先端テクノロジーを構築するために、「深層学習」や「グラフベース機械学習」などのテクノロジーの組み合わせることはよくあります。
しかし、アプリケーションで利用する機械学習システムの多くはクラウドで実行され、計算集約型であり、かなりのメモリ要件があります。クラウドに接続されているかどうかに関係なく、「パーソナルインテリジェンス」「スマートウォッチ」「IoTデバイス」でマシンインテリジェンスを提供したい場合はどうすれば良いでしょうか?
昨日、Googleは、「デバイス上」で機械学習テクノロジーを実行する新しいウェアラブルデバイス共に、「Android Wear 2.0」を発表しました。Expanderの研究チームが開発したこのデバイス上の機械学習システムにより、「スマートリプライ」などのテクノロジーを、クラウド接続なしに、あらゆるアプリケーションで利用できるようになりました。これからは、時計からタップするだけで着信チャットに応答できます。

この背後にある研究は昨年、私たちのチームが「Allo」と「Inbox」の会話理解能力を可能にする機械学習システムを開発しているときに始まりました。
「Android Wear」チームから連絡があり、「スマートリプライ」をスマートデバイスに直接展開できるかどうかを知りたいと考えていました。スマートデバイスの計算能力とメモリは限られているため、それは不可能であることにすぐに気付きました。
GoogleのプロダクトマネージャであるPatrick McGregorは、これがユニークな課題であり、Expanderチームが設計図に戻って、「Android Wear」で「スマートリプライ」を有効にするだけでなく、完全に新しい軽量の機械学習アーキテクチャを設計する機会を提供することに気付きました。
Tom Rudick、Nathan Beachおよび「Android Wear」チームの他の同僚と協力して、新しいシステムの構築に着手しました。
2. 投影による学習
軽量の会話型モデルを構築するための単純な戦略は、デバイス上で「一般的なルールの小さな辞書」(入力→応答マッピング)を作成し、推論時に検索することです。これは、「少数機能」を使用した「少数クラス」を含む単純な予測タスク(バイナリ感情分類など)で機能します。ただし、豊富な語彙やチャットで見られる幅広い言語の変動を含む複雑な自然言語理解タスクには対応できません。
一方、「リカレントニューラルネットワーク」(LSTMなど)などの機械学習モデルは、グラフ学習と組み合わせて、「スマートリプライ」などの自然言語理解タスクの学習のための非常に強力なツールであることが証明されています。しかし、このようなモデルをデバイスメモリに収まるように圧縮し、低い計算コストで堅牢な予測を行うことは非常に困難です。少数の応答のみを予測するようにモデルを制限したり、量子化などの手法を使用した初期の実験では、有用な結果は得られませんでした。
代わりに、デバイス上の機械学習システム用に別のソリューションを構築しました。最初に、高速で効率的なメカニズムを使用して、類似した着信メッセージをグループ化し、類似した「ビットベクトル表現に投影」します。
この「投影ステップ」を実行する方法はいくつかありますが(「Word Embeddings」や「Encoder Networks」など)、「LSH」(Locality Sensitive Hashing)を使用して、数百万の一意の単語から短い固定長のビットシーケンスに次元を削減しました。これにより、着信メッセージの予測を非常に高速に、デバイスの小さなメモリだけで計算できます。
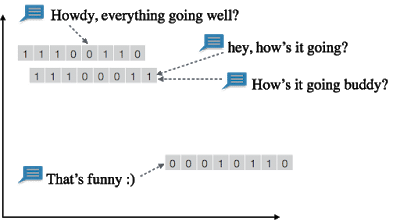
【投影ステップ】
類似メッセージがグループ化され、近くのベクトルに投影される。例えばば、「お元気ですか」「調子はどう?」 は同様のコンテンツを共有し、同じベクトル「11100011」に投影される可能性がある。別の関連メッセージ「すべて順調ですか?」は 2ビットのみが異なる、近くのベクトル「11100110」に投影される。
次に、システムは、「着信メッセージ」と「投影」を受け取り、「半教師ありグラフ学習」を使用して、「メッセージ投影モデル」を共同で訓練します。グラフ学習は、複数のソースからの意味的関係(メッセージ/返信の相互作用、単語/フレーズの類似性、セマンティッククラスタ情報)メッセージ/応答の相互作用、単語/フレーズの類似性、意味的クラスター情報)を組み合わせることにより、堅牢なモデルの学習を可能にします。

【学習ステップ】
(1) メッセージと予測および対応する応答(ある場合)が機械学習フレームワークで使用され、「メッセージ投影モデル」を共同で学習。
(2) 「メッセージ投影モデル」は、返信を対応する着信メッセージの投影に関連付けることを学習。例えば、モデルは2つの異なるメッセージ「すべて順調ですか」を投影。 そして「調子はどう?」を近くのビットベクトルに割り当て、これらを関連する返信にマップする方法を学習。
「メッセージ投影モデル」は複雑な機械学習アーキテクチャとクラウドの能力を使用して訓練しますが、モデル自体はデバイス上で推論することに注意してください。デバイスで実行されているアプリは、ユーザーの受信メッセージを渡し、デバイスからデータを送信せずに、デバイス上のモデルから応答の予測を受信できます。このモデルは、ユーザーの書き方や個人の好みに合わせてカスタマイズすることもできます。

【推論ステップ】
モデルは学習した予測を着信メッセージ(またはメッセージのシーケンス)に適用し、関連する多様な応答を提案。 デバイス上で推論が実行されるため、モデルをユーザーデータや個人の書き方に適応させることができる。
3. おわりに
このテクノロジーをゼロから構築するための取り組みに着手したとき、予測が有用であるか、十分な品質のものであるかはわかりませんでした。コンピューティングリソースとメモリリソースが非常に限られているGoogle Watchでも正しく機能していることに、私たちはかなり驚いて興奮しています。今後もモデルを改善して、ユーザーにもっと楽しい会話体験を提供できることを楽しみにしています。
この機能を使用して、Google WatchまたはAndroid Wear 2.0を実行する時計からメッセージに直接応答できるようになりました。Googleハングアウト、Googleメッセンジャー、および多くのサードパーティメッセージングアプリでも、すでに有効になっています。また、サードパーティのWearアプリの開発者向けのAPIも提供しています。
この記事が気に入ったらサポートをしてみませんか?