
HuggingFace の Mixtral 統合

以下の記事が面白かったので、かるくまとめました。
・Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face
1. HuggingFace の Mixtral 統合
「Mixtral 8x7b」は「Mistral」が本日リリースしたエキサイティングなLLMです。オープンモデルの新しいSoTAを確立し、多くのベンチマークにわたって「GPT-3.5」を上回っています。
本日提供されたHuggingFaceのMistral統合は、次のとおりです。
・HuggingFace Hub でのモデル共有
・Transformrs との統合
・Inference Endpoint との統合
・Text Gemeration Inferenct との統合
・TRL によるファインチューニング
2. Mixtral 8x7b
2-1. Mixtral 8x7b
「Mixtral」は「Mistral 7B」と似たアーキテクチャを持っていますが、一工夫が施されています。「MoE」(Mixture of Experts) と呼ばれる技術で、8つの「エキスパート」モデルが1つにまとめられています。Tranformerモデルの場合、これが機能する方法は、一部のフィードフォワードレイヤーを疎なMoEレイヤーに置き換えることです。MoEレイヤーには、どのエキスパートがどのトークンを最も効率的に処理するかを選択するためのルーターネットワークも含まれています。「Mixtral」の場合、タイムステップごとに2人のエキスパートが選択されるため、有効パラメータ数が4倍あるにもかかわらず、12Bのパラメータ密度を持つモデルの速度でデコードすることができます。
2-2. Mixtral 8x7b の特徴
・ベースモデルと指示モデルをリリース
・32kトークンのコンテキスト長をサポート
・Llama2-70Bを上回り、ほとんどのベンチマークでGPT-3.5と同等、またはそれ以上
・英語、フランス語、ドイツ語、スペイン語、イタリア語に対応
・コーディングが得意で、HumanEvalでは 40.2%
・Apache 2.0 ライセンスにより商用可能
2-3. Moe
「MoE」の詳細については、以下の記事を参照。
2-4. 評価
以下は、ベースモデルと他のオープンモデルの「LLM Leaderboard」における性能比較です (スコアが高いほど優れている)。
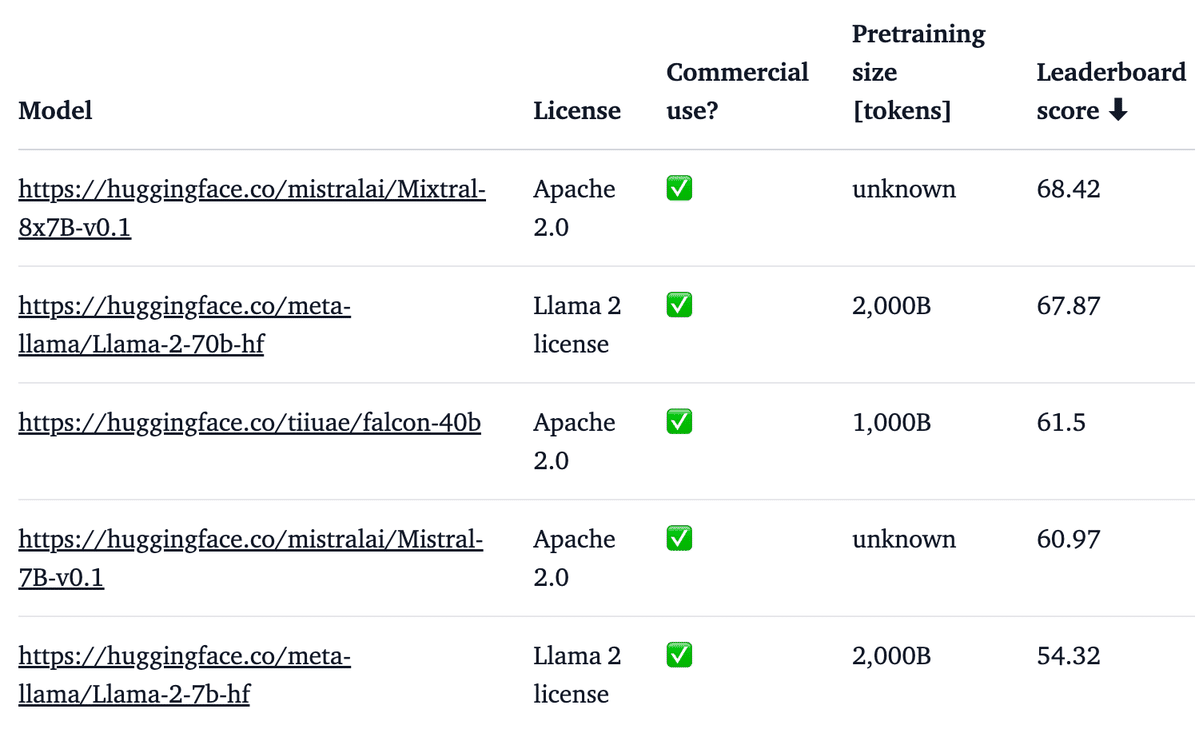
以下は、「Mixtral Instruct」とクローズドモデルとオープンモデルにおける「MT-Bench」「AlpacaEval」の比較です (スコアが高いほど優れている)。

「Mixtral Instruct」は、「MT-Bench」で他のすべてのオープンモデルよりも優れた性能を発揮し、「GPT-3.5」と同等の性能を達成した最初のモデルになります。
2-5. モデルサイズ
「Mixtral MoE」は「Mixtral-8x7B」と呼ばれますが、56Bパラメータはありません。リリース直後、モデルがそれぞれ7Bパラメータを持つ8つのモデルのアンサンブルと同様に動作すると誤解されている人がいることがわかりましたが、「MoE」モデルはそうではありません。
モデルの一部の層 (フィードフォワードブロック) のみが複製されます。残りのパラメータは7Bモデルと同じです。パラメータの総数は56Bではなく、約45Bです。アーキテクチャをよりよく伝えるには、もっと良い名前があったかもしれません。
2-6. プロンプト形式
ベースモデルは、プロンプト形式はありません。
指示モデルは、非常に単純なプロンプト形式を持っています。
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]2-7. 未解決の質問
以前の「Mistral 7B」と同様に、この新しいモデルについても未解決の質問がいくつかあります。特に、事前学習に使用されたデータセットのサイズ、構成、どのように前処理されたかについては情報はありません。同様に、「Mixtral」の指示モデルについても、「SFT」と「DPO」に関連するファインチューニングデータセットやハイパーパラメータに関する詳細は共有されていません。
3. デモ
「HuggingFace Chat」で「Mixtral」の指示モデルとチャットできます。
4. 推論
「Mixtral」で推論を実行するには、主に2つの方法があります。
・Transformers の pipeline()
・Text Generation Inference
各メソッドでは、モデルを半精度 (float16) または量子化された重みで実行できます。「Mixtral」モデルのサイズは45Bパラメータの密なモデルとほぼ同等であるため、必要な VRAMの最小サイズは、次のように推定できます。
・float16 > 90GB
・8bit > 45GB
・4bit > 23GB
5. Transformers との統合
「Transformers v4.36」では、「Mixtral」でHuggingFaceエコシステム内のすべてのツールを活用できます。
・学習および推論のスクリプトと例
・safetensors
・bitsandbytes、PEFT、Flash Attendant 2 などのツール
・テキスト生成のユーティリティとヘルパー
・デプロイするモデルをエクスポートするメカニズム
pip install -U "transformers==4.36.0" --upgrade
以下のコードでは、Transformersと4bit量子化で推論を実行する方法を示します。モデルサイズが大きいため、実行するには少なくとも30GBのRAMが必要です。
from transformers import AutoTokenizer
import transformers
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A Mixture of Experts is an ensemble learning method that combines multiple models, or "experts," to make more accurate predictions. Each expert specializes in a different subset of the data, and a gating network determines the appropriate expert to use for a given input. This approach allows the model to adapt to complex, non-linear relationships in the data and improve overall performance.6. Text Generation Inference との統合
「Text Generation Inference」は 、HuggingFaceによる実稼働対応の推論コンテナです。LLMを簡単にデプロイできます。連続バッチ処理、トークンストリーミング、複数GPUでの高速推論のためのTensor並列処理、本番環境に対応したロギングとトレースなどの機能を備えています。
HuggingFace推論エンドポイントを使用して LLM をデプロイする方法について詳しくは、記事を参照してください。
7. TRL によるファインチューニング
LLMの学習は、技術的にも計算的にも困難な場合があります。この節では、単一のA100 GPUで「Mixtral」を効率的に学習するためにHuggingFaceエコシステムで利用できるツールについて説明します。
「OpenAssistant」のチャットデータセットで「Mixtral」をファインチューニングするコマンドの例を以下に示します。メモリを節約するために、4bit量子化とQLoRAを利用して、Attentionブロック内のすべての線形層をターゲットにします。密なTransformerとは異なり、MLPレイヤーは疎であり、PEFTとうまく相互作用しないため、MLPレイヤーをターゲットにすべきではないことに注意してください。
まず、TRL のnightlyバージョンをインストールし、学習スクリプトにアクセスするためにリポジトリのクローンを作成します。
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl次に、スクリプトを実行します。
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 20_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit単一のA100での学習には約 9 時間かかりますが、利用可能な GPU の数に合わせて --num_processes を調整することで簡単に並列化できます。
8. 免責事項と進行中の作業
8-1. 量子化
MoEの量子化は、活発な研究分野です。TheBlokeは4bitおよび8bitの量子化を達成するために初期実験を行いましたが、モデルの品質は大幅に低下しました。今後数日、数週間でこの分野での発展が見られるのはとても楽しみです。さらに、 MoE のサブ1bit量子化を実現するQMoEなどの最近の研究をここに適用することもできます。
8-2. VRAM の使用量が多い
MoEは推論を非常に高速に実行しますが、それでも大量のVRAM (したがって高価なGPU) が必要です。このため、ローカル設定で使用することが困難になります。MoE は、多くのデバイスと大容量のVRAM を使用するセットアップに最適です。「Mixtral」には半精度で 90GBのVRAM が必要です。
関連
この記事が気に入ったらサポートをしてみませんか?