
画像1枚からVTuberになる方法

以下の記事を参考にして書いてます。
・Talking Head Anime from a Single Image
1. 要約
バーチャルYouTubeに魅了された私は、ディープニューラルネットワークシステムを構築しました。より具体的には、ネットワークは入力として「アニメキャラクターの顔の画像」と「ポーズ」受け取り、「そのポーズをとった同じキャラクターの別の画像」を出力します。
また、システムをフェイストラッカーに接続しました。これにより、キャラクターが私の顔の動きを模倣できるようにしました。
既存のビデオの顔の動きを模倣することもできます。
2. はじめに
過去2年間、私はバーチャルYouTuber(VTuber)に夢中になりました。これらはアニメのキャラクターであり、実際の人間によって演じられ、声を出して、動画コンテンツを提供したり、YouTubeでライブ配信を行ったりします。それらが何であるかを知ってもらうには、実際に見てもらうのが一番です。以下は、私のお気に入りのVTubersの1人「白上フブキ」になります。
VTubersはエンターテイナーの新しい分野を形成し、日本で注目を集めています。BBCによるこの記事によると、それらを中心に新しい産業が生まれており、企業は数百万ドルを投資することを計画しているとのことです。
一方、私は、特にアニメ関連のものに関しての、ディープラーニングの最近の進歩にも魅了されています。2017年、熱心な研究者チームが「GAN」の訓練に成功し、非常に高品質のアニメキャラクターの画像を生成しました。最近、フリーランスのライターである「Gwern」は、アニメ画像の最大のコーパスをリリースし、目を見張るほど美しいアニメキャラクターを生成するGANを訓練することもできました。
サンフランシスコのゲーム開発者である「Sizigi Studios」は、GANによって生成された女性キャラクターをカスタマイズし、彼女をフィーチャーした商品を購入できるWebサイト「WaifuLabs」を開設しました。
The StyleGAN anime face interpolations are solid:
— 𝔊𝔴𝔢𝔯𝔫 (@gwern) February 12, 2019
- https://t.co/JtzWaQ1rLT
- https://t.co/dl5AqXYqlc
- https://t.co/FaldMdAbyQ pic.twitter.com/7T7hoCDXMg
すべては、人工知能がアニメ作成の重要なツールとなる未来を指し示しているようで、私はそれを実現することに参加したいと思いました。特に、ディープラーニングでアニメを簡単に作成するにはどうすればよいでしょうか。最も手に届きそうな果実は、VTuberのコンテンツ作成のようです。
そこで、私は2019年の初めから、「VTuberになるためにディープラーニングを活用できるか」という問いに答えるための探求に乗り出しました。
3. 何をしようとしているのか
そもそもどのようにしてVTuberになるのか。まずは、動きを制御できるキャラクターモデルが必要です。
1つのアプローチは、キャラクターの完全な3Dモデルを作成することです。この方法は、「キズナアイ」「ミライアカリ」「電脳少女シロ」など多くの有名なVTubersがとっています。ただし、美しい3Dモデルを作成するには、複数の種類の才能が必要になり、費用もかかります。優れたキャラクターデザイナーが必要であり、高度に熟練した3Dモデラーも必要です。キャラクターを作成することは、私のような芸術スキルのない人間には立ち入れない領域であることは言うまでもありません。もちろん、お金で解決することもできますが、軽くGoogle検索したところ、手数料の提示価格は約500,000円(≈ 5,000ドル)でした。
2つ目のアプローチは、3Dモデルの代わりに、2Dモデルを作成することです。2Dモデルは、レイヤーに配置された動かすことができる画像のコレクションです。ほとんどのVTuberはこのタイプのモデルを使用します。3Dと比べてはるかに安価に作成できるためです。試運転で約30,000円(≈300ドル)です。それでも、2Dモデリングには、キャラクターの設計と作画に加えて、追加の作業が必要です。体は複数の可動部分に分割する必要があります。その後、モデラーは、「Live2D」などの特殊なソフトウェアを使用してそれらを組み立てる必要があります。部品の動きを指定するのにも時間がかかります。
ただし、ほとんどの2D VTuberの動作はかなり単純です。口や目を開閉したり、眉を上下させたり、顔を小さな角度で回転させたり、体を左右に揺り動かしたりできます。体を回転させたり、腕や脚を動かしたりは、めったにしません。その理由は、2D画像のコレクションで、そのような動きを作成することは非常に困難だからです。
2D VTuberの動きは単純で制限されているので、動かすことができる2Dモデルを作成する代わりに、その場で自動的に生成できるないでしょうか。そうすることができれば、VTuberになりやすくなります。私はおそらく2万円以下のデザインを依頼することができます。さらに良いことに、GANを使用して、実質的に無料でキャラクターを生成することもできます。これは、私のような絵を描けない人だけでなく、アーティストにとっても利益です。さらには、ゲーム制作でも活用できます。「ビジュアルノベル」のすべてのキャラクターを対話の中で動かすのは非常に簡単です。
4. システム概要
目標が設定されたので、プロジェクトについて具体的に見てみましょう。私が解決しようとしている問題は以下です。
「アニメキャラクターの顔の画像」と「ポーズ」受け取り、
「そのポーズをとった同じキャラクターの別の画像」を出力
ここで、「ポーズ」とは、キャラクターの「表情」と「頭の向き」を指定する数字群です。私のポーズには6つの数字があり、要旨の最初のビデオのスライダーに対応しています。入力と出力の詳細については、「問題の仕様」のセクションで説明します。

ご想像のとおり、ディープラーニングでこの問題を解決します。これには、次の2つの質問に答える必要があります。
(1) ネットワークの訓練に使用するデータは何か。
(2) どのネットワークアーキテクチャを使用するか。特にネットワークをどのように訓練するか。
主な課題は最初の質問であることがわかります。ポーズがアノテーションされた顔画像を含むデータセットが必要です。「EmotioNet」は、目的のタイプのアノテーションを備えた人間の顔の大きなデータセットです。しかし、私の知る限り、アニメキャラクターのそのようなデータセットはありません。
そのため、プロジェクト専用の新しいデータセットを生成しました。「MikuMikuDance」と呼ばれる3Dアニメーションソフトウェア用に作成された、ダウンロード可能なアニメキャラクターの3Dモデルが何万もあるという事実を利用しました。約8,000個のモデルをダウンロードし、それらを使用してランダムなポーズでアニメの顔をレンダリングしました。データを準備する手順については、「データセット」のセクションで説明します。
3Dキャラクターモデルのアニメーション方法に従ってネットワークを設計しました。プロセスを2つのステップに分解します。
(1) 顔の表情の変更(目と口をどれだけ開くかを制御)
(2) 顔を回転
各ステップで個別のネットワークを使用し、2番目のネットワークが最初の出力を入力として使用するようにします。最初のネットワークを「フェイスモーファー」(face morpher)、2番目のネットワークを「フェイスローター」(face rotator)と呼ぶことにします。

「フェイスモーファー」には、「Pumarola et al.」が採用したジェネレーターアーキテクチャを使用します。このネットワークは、元の画像への変更を表す別の画像を生成することにより、表情を変更します。変更イメージは、アルファマスクを使用して元のイメージと結合されます。これもネットワーク自体によって生成されます。彼らのアーキテクチャは、画像の小さな部分を変更するのに非常に効果的であることがわかりました。私の場合はこれによって、目と口を閉じさせます。
「フェイスローテイター」は、はるかに複雑です。単一のネットワークに実装された2つのアルゴリズムを使用して顔を回転させ、2つの出力を生成します。アルゴリズムは次のとおりです。
・「Pumarola et al.」のアルゴリズム
これは顔の表情の変更に使用されるものですが、今回はネットワークに顔を回転させるように指示しています。
・「Zhou et al.」のビュー合成アルゴリズム
彼らの目標は、画像内の3Dオブジェクトを回転させることです。それらは、ニューラルネットワークに外観フローを計算させることによって実行します。
外観フローは元のテクスチャを保持するシャープな結果を生成しますが、回転後に見えるようになるオクルードされた部分を幻覚化するのは得意ではありません。
一方、「Pumarola et al」のアーキテクチャは、ぼやけた結果を生成しますが、既存の画像のピクセルをコピーせずに元の画像のピクセルを変更するように訓練されているため、非閉塞部分を幻覚化できます。
両方のアプローチの利点を組み合わせるために、アルファマスクを介して2つの出力をブレンドする別のネットワークを訓練します。ネットワークは、「レタッチ」画像も出力します。これは、さらに別のアルファマスクを使用して、結合された画像とブレンドされます。
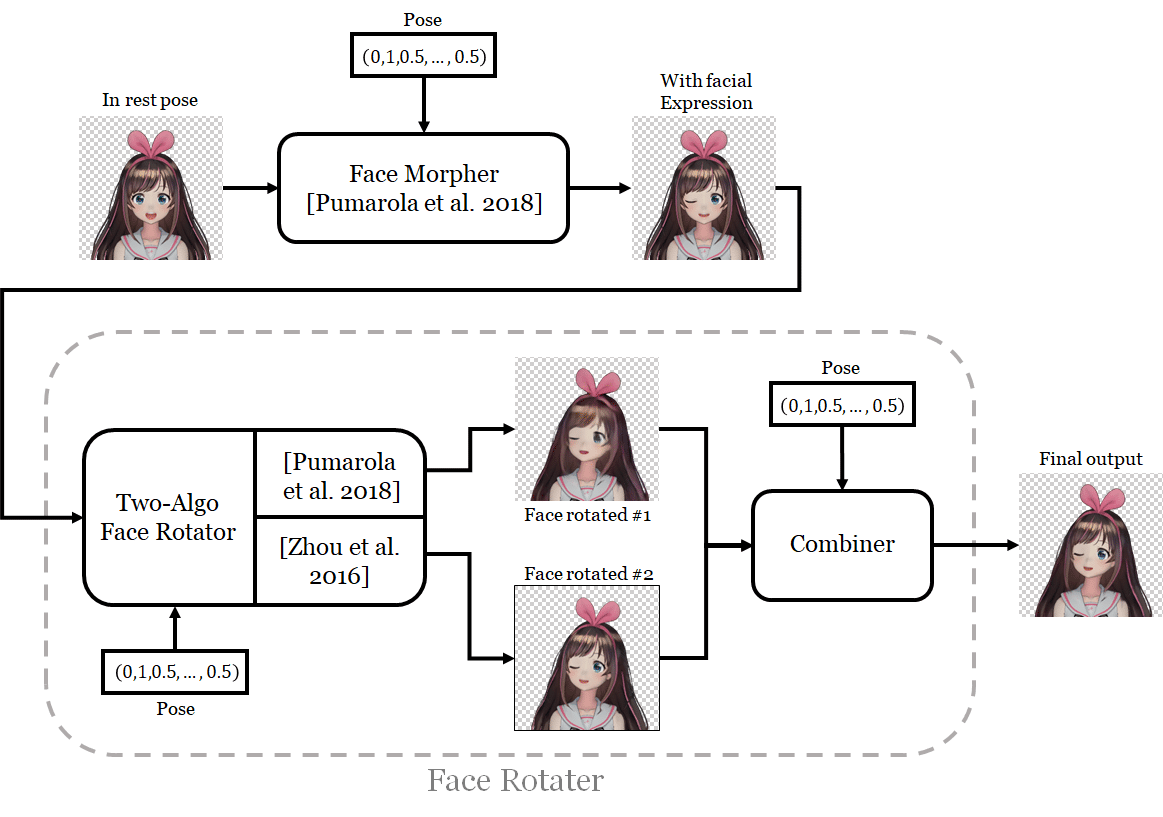
すべてのネットワークのアーキテクチャと、それらがどのように訓練されたかについては、「ネットワーク」のセクションで説明します。
5. 問題の仕様
システムへの入力は、「アニメキャラクターの画像」と「ポーズ」のベクトルで構成されます。
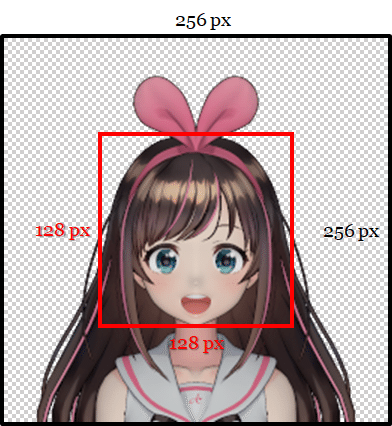
画像のサイズは 256 ×256 のRGBA形式で、透明な背景が必要です。より具体的には、キャラクターに属さないピクセルのRGBA値は (0,0,0,0) である必要があり、ピクセルはゼロ以外のアルファ値である必要があります。キャラクターの頭は、イメージの垂直方向にまっすぐである必要があります。頭は中央 128 ×128 に収まる必要があります。目と口は大きく開いている必要があります。(ネットワークは目と口を閉じた状態でも画像を処理できます。しかしそのような場合、開いた目と口がどのように見えるかに関する十分な情報がないため、開くことができません。)
前述のように、キャラクターの顔の構成は「ポーズ」によって制御されます。私の場合、これは6次元のベクトルです。3成分は顔の特徴を制御し、閉区間の値を持っています。
・2成分が目の開きを制御
1つは左目用、1つは右目用です。値「0」が完全に開いていること、値「1」が完全に閉じていることを意味します。

・1成分がが口の開きを制御
値「0」が口が完全に閉じていること、値「1」が口が完全に開いていることを意味します。目と口のパラメータが矛盾するのは、3Dモデルのモーフの重みのセマンティクスに由来します。

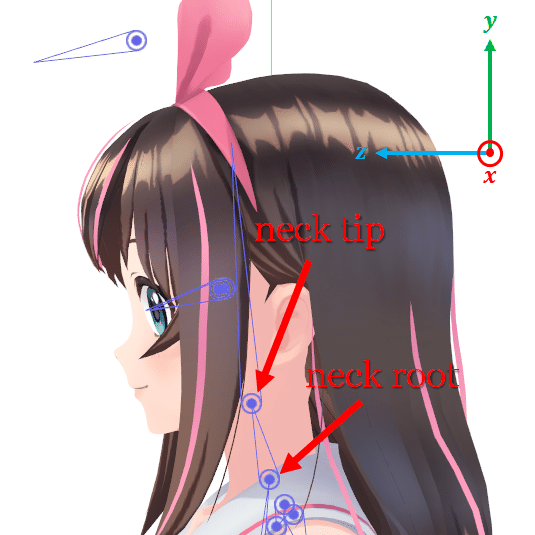
他の3成分は、頭の回転方法を制御します。頭は「ボーン」に接続した2つの「関節」によって制御されます。
「ネックルート」は、首と本体を接続する関節で、ネックチップは、首と頭を接続する関節になります。キャラクターのスケルトンでは、「ネックチップ」は「ネックルート」の子です。そのため、「ネックルート」に適用された3D変換は「ネックチップ」に影響しますが、逆には影響しません。
「ポーズ」の3成分は、間隔の値を持っています。
・ネックルートの関節のz軸周りの回転を制御
y軸が上を向き、x軸が文字の左側を指し、z軸が正面を指します。要素は首が横にどの程度傾くかを制御します。回転角度を [-15度, 15度] の範囲に制限します。値「-1」は「-15度」に対応し、値「1」は「15度」に対応します。

・ネックチップの関節のx軸周りの回転を制御
物理的には、頭が上下にどれだけ傾いているかを示します。繰り返しますが、要素の値の範囲 [-1, 1] を回転角の範囲 [-15度, 15度] にマッピングします。正の値は頭を上に傾けることを意味し、負の値は頭を下に傾けることを意味し、値「0」は頭がz軸に平行な方向を向いていることを意味します。

・ネックチップの関節のy軸を中心とした回転を制御
顔の水平方向を制御します。

「眉毛」「虹彩」「上半身」など、さまざまな種類の動きを省略しました。システムを完成させ、それがより速く動作することを実証できるように、問題をより小さく、より簡単に解決できるようにするためです。システムは現在制限されていますが、動きの種類を追加することは、ここで行うことと概念的には異なりません。これは今後の作業として残しています。
要約すると、入力はキャラクターの顔の画像と6次元の「ポーズ」ベクトルで構成されます。出力は、顔の別の画像であり、それに応じてポーズが設定されます。
6. データセット
2D絵のキャラクターをアニメーション化したいので、2D絵でネットワークを訓練することが最も有利です。けれども、3Dキャラクターモデルをレンダリングして訓練データセットを作成しました。3Dレンダリングは2D絵と同じではありませんが、3Dモデルの方が操作がはるかに簡単であるためです。任意のポーズをモデルに適用し、そのポーズを正確に示す画像をレンダリングできます。さらに、3Dモデルを使用して何百もの訓練画像を生成できるため、数千のモデルを収集するだけで済みます。2D絵を使用する場合、何十万もの2D絵を収集し、それぞれにキャラクターのポーズをアノテーションする必要があります。数十万の画像にアノテーションを付けることは、数千の3Dモデルを処理するよりもはるかに困難です。
「MikuMikuDance」(MMD)と呼ばれる3Dアニメーションソフトウェア用に作成されたモデルを使用しています。主な理由は、アニメキャラクターのダウンロード可能なモデルが、何万もあることです。また、MMDモデルを使用して以前の研究論文の1つの訓練データを生成したため、ファイル形式にも精通しています。長年にわたり、モデルを操作およびレンダリングするためのライブラリを開発していたため、データ生成プロセスの多くを自動化することができました。
訓練データセットを作成するために、「ニコニコ立体」「BowlRoll」などのWebサイトから、約13,000のMMDモデルをダウンロードしました。さらに、「VPVP wiki」「みさきる!」「ニコニコ大百科」のリンクをたどってモデルを見つけました。ダウンロードだけで約2か月かかりました。
これらモデルはすべて使用できるわけではありません。それらのいくつかはキャラクターモデルでさえありません、そして私は私のライブラリが扱うことができなかったモデルを捨てなければなりませんでした。反復訓練データを減らすために、外観が他のモデルの外観に近すぎると思われるモデルも主観的に削除しました。すべて排除した後、約8,000のモデルが残されました。
7. データアノテーション
生モデルデータは、訓練データを生成するのに十分ではありません。特に、2つの問題があります。
(1) 各モデルの頭がどこにあるのか正確にわからない。
入力仕様では、入力イメージの中央の128×128ボックスにヘッドを含める必要があるため、これを知る必要があります。そこで、各モデルに頭の下部と上部のy位置に注釈を付けることができるツールを作成しました。下部はあごの先端に対応していますが、上部には正確な定義がありません。ほとんどの場合、頭蓋骨全体と頭蓋骨を覆う髪の平らな部分が範囲に含まれるようにし、上向きの髪を任意に除外しました。キャラクターが帽子をかぶっている場合、私は単に頭のてっぺんの位置を推測しました。幸いなことに、ニューラルネットワークが機能するには、位置が正確である必要はありません。
(2) 各モデルの目を正確に制御する方法がわからない。
MMDモデルの顔の表情は、「モーフ」(別名ブレンドシェイプ)で実装されます。モーフは通常、特定の方法で変形される顔の特徴に対応します。たとえば、ほとんどのモデルには、両目を閉じることに対応するモーフと、「あ」と言うかのように口を開くことに対応するモーフがあります。訓練データを生成するには、左目を閉じるモーフ、右目を閉じるモーフ、口を開くモーフの3つのモーフの名前を知る必要があります。最後のモデルは、ほとんどすべてのモデルで「あ」と名付けられているため、問題はありませんでした。目を閉じるモーフでは、状況はさらに難しくなります。モデラーの名前が異なると、モデルの一部または両方が欠落する場合があります。
私は目の制御モーフを循環させ、正しいセマンティクスを持つものをマークできるツールを作成しました。
ビデオでは、2つではなく6つのモーフを収集したことがわかります。理由は、MMDモデルには一般に2種類のウインクが付属しているためです。通常のウインクには、まぶたが下向きに湾曲しており、笑顔のウインクには、まぶたが上向きに湾曲しているので、幸せそうに見えます。さらに、ウィンクのタイプごとに、3つの異なるモーフがあります。1つは右目を閉じ、1つは左を閉じ、もう1つは両方を閉じます。データアノテーションの時点で、使用するウィンクとモーフのタイプがわからなかったため、それらをすべて収集することにしました。最終的に、より多くのモデルがそれらを持っているので、私は通常のウィンクのみを使用することにしました。両目を閉じるモーフは不要であるように見えますが、一部のモデルには片目だけを閉じるモーフがありません。そのためのツールの開発など、モデルにアノテーションを付けるには、約4か月かかりました。プロジェクトの中で最も時間のかかる部分でした。
8. ポーズサンプリング
訓練データのもう1つの重要な部分は「ポーズ」です。これは、訓練の例ごとに1つ指定する必要があります。「ポーズ」ベクトルの各要素を個別にサンプリングして、ポーズを生成しました。目と口を制御するパラメータについては、[0, 1] 間隔から均一にサンプリングします。頭部関節パラメータについては、範囲の中心(0)から極値(-1と1)まで密度が線形に増加する確率分布からサンプリングしました。密度は次の図に示しています。
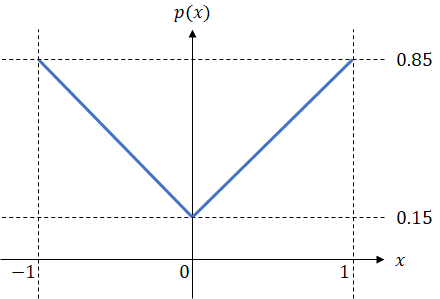
訓練のサンプルを増やすためにこの分布を選択しました。いくつかの頭部関節パラメータが「0」から遠く離れている場合、頭部の構成と残りのポーズの構成に大きな違いがあります。ネットワークに最初からやりがいのある問題を強制的に解決させると、一般的にパフォーマンスが向上すると思います。
9. レンダリング
訓練画像を生成するために、「モデル」と「ポーズ」を決定します。頭の上下のy位置が画像の中央の128ピクセルの垂直に対応するように、正射投影を使用してポーズモデルをレンダリングしました。 透視投影ではなく正投影を使用する理由は、特にVTubersの2D絵には短縮効果がないようだからです。
3Dモデルをレンダリングするには、モデルの表面の光散乱特性を指定する必要があります。MMDは通常、トゥーンシェーディングを使用しますが、トゥーンシェーディングを実装するには遅すぎるため、より標準的なPhong反射モデルを使用しました。モデルデータによっては、結果の訓練画像は通常の図面よりも3Dのように見える場合があります。ただし、最終的には、3Dのような画像の訓練を受けているにもかかわらず、システムは2D絵でもうまく機能しました。

レンダリングには、シーンの照明を指定することも必要です。2つの光源を使用しました。 1つは、-z方向に真っ直ぐを指す大きさ0.5の指向性白色光です。ライトの方向は、レンダリングの影を最小限に抑えるために選択されました。 2番目は、大きさが0.5の白色の環境光源です。
データ生成プロセスのもう1つの詳細は、各訓練のサンプルが3つの画像で構成されていることです。
(1) 静止ポーズ
(2) 顔の特徴の変更のみ
(3) (2)に顔の回転を追加
これは、顔の特徴を操作したり顔を回転させたりするための別のネットワークがあり、異なる訓練データが必要だからです。残りのポーズ画像はサンプリングされたポーズに依存しないため、モデルごとに一度だけレンダリングする必要があることに注意してください。
10. データセット
モデルを3つのサブセットに分割し、それらを使用して訓練、検証、およびテストデータセットを生成できるようにしました。モデルをダウンロードしながら、ソース資料に応じてフォルダーに整理しました。
たとえば、「Fate / Grand Order」と「艦隊これくしょん」のキャラクターモデルは、異なるフォルダーに入れました。「にじさんじ」のVTubersのモデルを使用して検証セットを生成し、他のVTubersのモデルを使用してテストセットを生成しました。訓練セットは、アニメ、マンガ、ビデオゲームのキャラクターから作成されました。キャラクターの起源が異なるため、3つのデータセット間に重複はありません。
3つのデータセットの数値の内訳は次のとおりです。

データ生成は完全に自動化されました。全体のプロセスには約16時間かかりました。
11. ネットワーク
私のニューラルネットワークシステムは多くのサブネットワークで構成されています。それらを詳細に説明します。
◎ フェイスモーファー
キャラクターの顔のポーズをとる最初のステップは、顔の特徴を変更することです。より具体的には、目と口を閉じる必要があります。
「Pumarola et al」の論文では、顔の筋肉の動きを表す特定の「Action Unit」(AU)に従って、人間の顔の特徴を変更できるネットワークについて説明しています。AUは非常に一般的なコーディングシステムであるため、そのネットワークは目と口を閉じる以上のことができます。その結果、手元にあるタスクで効果的だと思いました。私はそれを試してみましたが、それは失望しませんでした。
しかし、私の問題は彼らの問題よりもずっと単純なので、私は論文のすべてを使用しませんでした。特に、彼らの訓練データは、異なる顔の表情をした同じ人の顔のペアでは得られません。そのため、教師なし学習を実行するために、サイクルの一貫性が失われたGANを使用する必要があります。ただし、私のデータはペアになっています。そのため、教師あり学習を行うことができます。その結果、私は彼らのジェネレータネットワークだけが必要です。
完全を期すために、私は「Pumarola et al.」のジェネレータを詳細に説明します。ネットワークは、アルファマスクを介して元の入力画像と結合される変更画像を生成することにより、表情を修正します。そうするために、入力画像とポーズはエンコーダー / デコーダーネットワークに送られ、それぞれに対して64次元の特徴ベクトルが生成されます。入力画像のピクセル、 特徴ベクトルのこの画像は、2D畳み込みユニットと適切な非線形性の2つの別々の列で処理され、アルファマスクと変更画像が生成されます。ネットワークの詳細な仕様は、付録 A.1に記載しています。
「Pumarola et al」は、かなり複雑な損失関数でネットワークを訓練しました。驚いたことに、私の問題では単純なL1ピクセル差の損失で十分でした。数学的には、損失関数は次のように与えられます:

・添え字f_mは「顔モーファー」の略。
・p_dataは、訓練データの確率分布を示す。サンプルはタプル(I_r、ρ、I_e)で、I_rは休憩ポーズのキャラクター画像、ρはポーズベクトル、I_eは表情付きキャラクター画像。
・G_fmは、顔モーファーネットワークを示す。
「Pumarola et al.」の設定と同じ設定を使用して、Adamアルゴリズムでネットワークを最適化しました。学習率は1-4、β1= 0.5、β2= 0.999、バッチサイズは25です。ネットワークは6エポック(3,000,000 例)、GeForce GTX 1080 Ti GPUで約2日かかります。
◎ フェイスローテイター
「フェイスローテイター」は、2つのサブネットワークで構成されています。2つのアルゴリズムのローテーターは、それぞれ独自の長所と短所を持つ2つの異なるアルゴリズムを使用してキャラクターの顔を回転させます。それらの強度を結合するために、コンバイナは2つの出力画像を取得し、それらをアルファマスクとブレンドし、画像をレタッチして品質を向上させます。
・2つのアルゴリズム路のローテイター
このアーキテクチャは図6Bに示されており、付録A.2で詳細に指定されています。
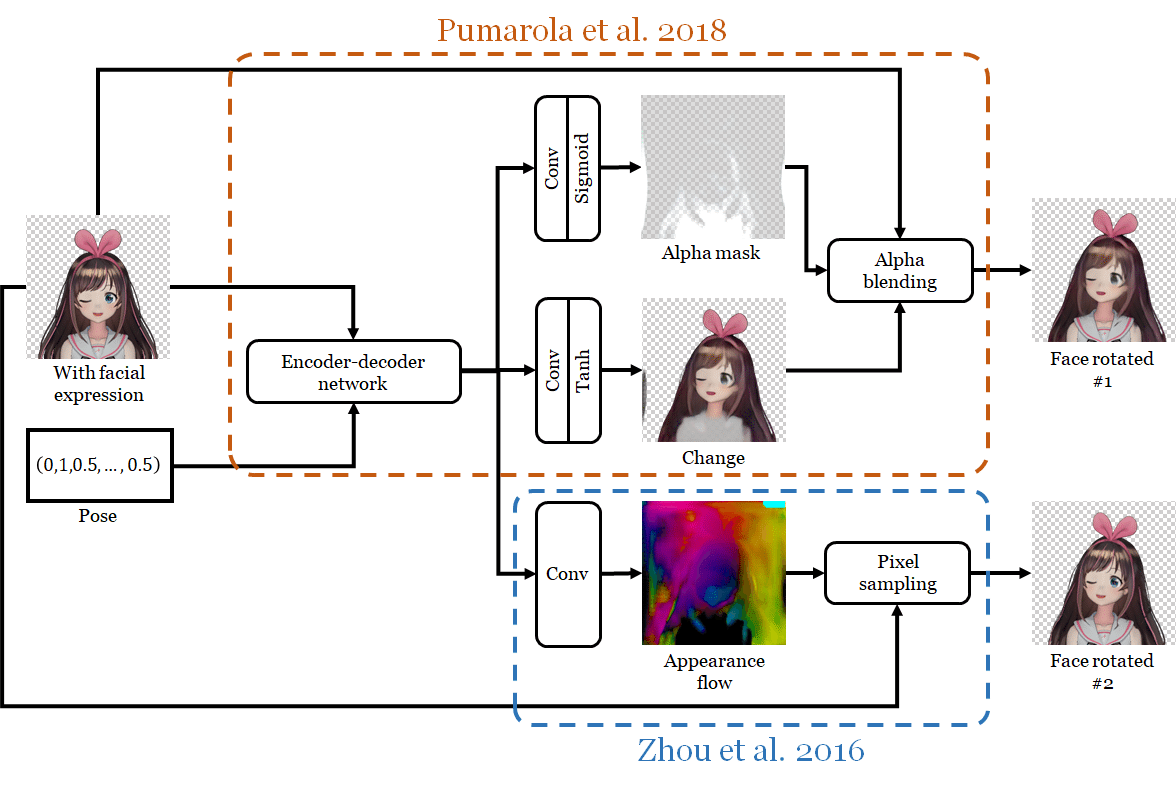
このネットワークは、「Pumarola et al.」のジェネレータの拡張と考えることができます。ジェネレータのすべてのユニットを備えていますが、現在は新しい出力経路が含まれています。古いものは、目と口を閉じるのではなく、顔を回転させるように求められているネットワークです。
新しい経路は、「Zhou et al」の論文で説明されているオブジェクトを回転させるアプローチを使用して出力を生成します。特に小さな角度でオブジェクトを回転させるには、主に入力画像内のピクセルをさまざまな場所に移動する必要があります。「Zhou et al.」にしたがって、外観フローの計算を提案します。マップは、入力画像内の出力画像の各ピクセルのコピー元を示すマップです。次に、このマップと元の画像がピクセルサンプリングユニットに渡され、出力画像が生成されます。私のアーキテクチャでは、エンコーダー / デコーダーネットワークの出力を新しい畳み込みユニットに渡すだけで、外観フローが計算されます。
2つの異なる損失を使用してネットワークを訓練しました。 1つ目は、L1ピクセルの差分損失のみです。

・下付き文字f_rは「顔回転子」を表し、上付き文字L1はL1損失を表す。
・p_dataは、再び訓練データの確率分布を示す。 サンプルは現在(I_e、ρ、I_p)。ここで、I_eは表情が変化した画像、ρがポーズ、I_pが完全にポーズされた画像。
・インデックスkは2つの出力経路を通過し、I_kはk番目の経路の出力を示す。

・G_1は「Pumarola et al.」の経路を示し、G_2はZhou等の経路を示す。
2番目の損失は、L1ピクセル差分損失とジョンソンらの知覚的特徴再構成損失の合計です。

・上付き文字Pは、「知覚」を表す。
・Φ1、Φ2、Φ3は、それぞれVGG16のrelu1_2、relu2_2、relu3_3レイヤーを使用して定義されたジョンソンらの特徴再構成損失を示す。 次のように定義される。

ここで、ϕj(⋅)は、j番目に使用される層によって出力される特徴テンソルを示します。 入力形式の違いにより、損失は1つではなく2つのL1ノルムの合計として定義されます。VGG16は入力として3チャンネルの画像を取りますが、この記事のすべての画像には4チャンネルがあります。 フォーマットの不一致を解決するために、各4チャンネル画像Iから2つの3チャンネル画像を作成します。I^rgbで示される最初の画像は、IのRGBチャンネルのみを取得して形成されます。I^aaaで示される2番目の画像は IのAチャンネルを3つの出力チャンネルにコピーすることにより形成される3チャンネルのグレースケール画像。
・λfrjはj番目の特徴再構成損失の重みです。 私はそれを次のように定義します:

ここで、C_j、H_j、およびW_jは、ϕ_j(⋅)のチャネル数、高さ、および幅です。実際には、特徴の再構成損失は、処理された画像のサイズに「一致」するように再スケーリングされ、その後、私が任意に選んだ定数である1/5で乗算されます。
繰り返しになりますが、「フェイスモーファー」と同じハイパーパラメータを使用して、6エポック(3,000,000サンプル)で、Adamを使用してネットワークを訓練しました。L1ロスを使用する場合、バッチサイズを25に設定すると、訓練には約2日かかりました。ただし、特徴の再構成損失を評価するにはより多くのメモリが必要になるため、知覚損失を伴う訓練ではバッチサイズを8に減らす必要がありました。この場合、訓練には6日かかりました。
・コンバイナー
2つのアルゴリズムのローテーターの出力を見て、それらの1つだけでは不十分であることがわかります。

図6Cでは、キャラクターの首が回転し、その結果、体に隠れていた長い髪の一部が見えるようになります。「Pumarola et al.」のアルゴリズムがぼやけた顔を生成したことがわかります。これは、圧縮されたフィーチャエンコードからすべての新しいピクセルを生成するようネットワークに要求するためであると推測されます。これにより、元の画像の高周波の詳細が失われる可能性があります。他のエンコーダーデコーダーアーキテクチャーからの同様の動作は、以前の研究でも見られます。たとえば、「Tatarchenko et al.」「Park et al.」「Zhou et al.」は入力画像のピクセルを再利用するため、鮮明な結果を得ることができます。
それにもかかわらず、既存のピクセルをコピーすることにより、非コピー部分を再構築することは難しく、特にコピー元の適切な場所が遠く離れている場合は困難です。図6Cbでは、「Zhou et al.」のアルゴリズムが、腕のピクセルを使用して、閉鎖されていない髪を再構築したことを示しています。
一方、「Pumarola et al.」の髪はより自然な色をしています。
2つのアルゴリズムの出力を組み合わせることで、はるかに良い結果を得ることができます。再配置された可視ピクセルは鮮明なままであり、非遮蔽部分のピクセルは自然な色になります。コンバイナーネットワークを図6Dに示し、付録A.3で詳細に指定します。

ピクセルごとの操作を容易にするために、U-Netを「コンバイナー」の本体として使用します。次に、その出力は2つのアルファマスクと変更画像に変換されます。最初のアルファマスクは、2つの入力画像を結合するために使用されます。次に、2番目のアルファマスクと変更イメージを前のステップの出力と組み合わせて、最終出力を生成します。この最後のステップでは、結合された画像を「レタッチ」して品質を改善します。
「コンバイナー」は、メモリ使用量を削減するために、2つのアルゴリズムのローテーターとは別に訓練されました。前者の入力を生成するために、すべての訓練例で後者を実行しました。繰り返しますが、2つの損失関数を試しました。
1つ目は「L1損失」です。

・下付き文字cは「コンバイナ」を表す。
・I_cはコンバイナの出力を表す。

・G_cは「コンバイナー」自体を示します。
2つ目は「知覚的損失」です。

・λ_c^jは、L1ピクセル損失に対する知覚損失の重み。私はそれを設定。

訓練と検証のセットで評価したときに2つの損失がほぼ同じ大きさになるように、選択した「コンバイナー」の重みは低くなります。
訓練手順は、「フェイスモーファー」の手順に似ていました。ただし、便宜上、期間は6ではなく3エポックでした。L1損失のバッチサイズは20で、訓練は1日で終了しました。知覚損失については、バッチサイズは12で、訓練は2日間続きました。
12. 評価
◎ ネットワーク構成
前のセクションのネットワークと損失関数の組み合わせにより、ポーズ設定タスク全体を実行できるさまざまなネットワーク構成が発生します。顔は3つの方法で回転させることができます。
(1) 「Pumarola et al」のみ
(2) 「Zhou et al.」のみ
(3) または両方とコンバイナーを使用
さらに、顔回転体の各サブネットワークは、「L1」または「知覚損失」のいずれかを使用して訓練できます。可能なすべての構成を以下の表に示します。

上記のすべての構成では、「フェイスローテイター」のみが変更され、「フェイスモーファー」ーは固定されたままであることに注意してください。
◎ 定量的評価
パフォーマンスは2つのメトリックを使用して評価されます。
(1) ネットワークの出力とグラウンドトゥルースイメージの間のピクセルごとの平均二乗平均誤差(RMSE)
(2) 平均構造類似性指数(SSIM)
スコアは、テストデータセットの10,000個の例を使用して計算されます。

一般に、1つの顔の回転経路を単独で使用すると、2つの経路を組み合わせるよりもパフォーマンスが低下します。注目すべき例外の1つは、PU-PのパフォーマンスがMRSEに関してFU-P-Pを除くすべてのネットワークよりも優れていることです。ただし、SSIMの場合、組み合わせることで常にパフォーマンスが向上しました。
別の傾向として、知覚的損失を使用すると、一般に両方のメトリックに従ってパフォーマンスが向上します。ただし、SSIMメトリックに関して最適な構成は、FU-P-PではなくFU-P-L1です。
最適な構成はFU-P-L1とFU-P-Pであり、どちらも両方のメトリックで1番目と2番目の最高スコアを達成したようです。したがって、生成された画像を調べて、どちらが優れているかを判断する必要があります。
◎ 定性的評価
8つのネットワーク構成とMMDモデルレンダラーを使用して、テストデータセットで選択した8つのキャラクターのビデオをレンダリングしました。付録B.1には、2つの設定でレンダリングされたビデオを並べて表示できるインタラクティブビューアがあります。以下に、構成の1つによって生成されたビデオを示します。

視覚的な品質の観点からネットワーク構成を比較してみましょう。PU-L1およびPU-Pは、ぼやけすぎて低品質の結果を生成します。これは、プマロラらのアーキテクチャは顔の小さな部分を修正するのに効果的ですが、修正が出力画像の大部分をカバーする場合にはうまく機能しないことを示しています。また、「Park et al.」によって観察されたように、PU-Pは知覚損失のおかげでより鮮明な画像を生成することも観察できます。ただし、損失自体の副産物であるチェッカーボードアーティファクトがあります。

一方、ZH-L1とZH-Pは、入力画像からピクセルを直接コピーするため、非常にシャープな結果を生成します。ただし、不規則なアーティファクトが生成される可能性があり、これによりキャラクターが不明瞭になる場合があります。

すべてのサブネットワークを使用する構成の場合、コンバイナが「Zhou et al.」の経路からこれらのピクセルを選択するため、ほとんどの顔と体はシャープになります。「Pumarola et al」の経路は、「Zhou et al.」のピクセルよりもすぐ隣のピクセルをコピーする傾向が少ないため、コンバイナーは前者のピクセルから選択し、後者が生成する妨害アーティファクトを大部分(完全ではない)除去できます。したがって、完全な構成は、1つのパスウェイのみを使用するイメージよりも優れたイメージを生成します。ただし、出力は非閉塞部分ではまだぼやけています。図7Fは、4つの完全な構成の中でFU-P-Pが最もシャープな結果をもたらすことを示しています。ただし、一部の視聴者(自分を含む)は、チェッカーボードのアーティファクトが気に入らず、FU-P-L1のより滑らかな出力を好む場合があります。

私は、すべてのネットワークがキャラクターの解剖学についてある程度高度な理解を持っているように見えることに注意してください。たとえば、「ヤマト イオリ」の右目は髪で塞がれており、目を閉じたときに咬合する髪を動かすネットワークはありません。ただし、誤った画像解析による多くの興味深い失敗事例も観察できます。たとえば、「夜桜たま」には、体の前に落ちる長い三つ編みがあります。図7Gaのように、すべてのネットワーク構成で2つの部分に分割され、頭部とともに上部のみが移動します。また、図7Gbおよび7Gcに示すように、衣服やアクセサリーを頭の一部として誤って解釈する可能性があります。



結論として、FU-P-L1およびFU-P-Pは、大規模なアーティファクトをほとんど伴わずにほとんどシャープな出力を生成するため、最良のネットワーク構成であると思われます。FU-P-Pは市松模様のシャープな画像を生成し、FU-P-L1はぼやけたが滑らかな結果を生成します。両方のネットワークは、入力画像を誤って解析し、解剖学的/物理的に信じられないアニメーションを作成する可能性があります。
13. アニメーション化
このプロジェクトの最終目標は、3Dレンダリングではない図面をアニメーション化できるようにすることです。最高のネットワークであるFU-P-Pを使用して、「にじさんじ」に所属するVTubersとWaifu Labsによって生成されたキャラクターの画像をアニメーション化することで、私のアプローチがどれほどうまく機能しているかを評価しました。下図に16のキャラクターのビデオを示します。付録B.2のインタラクティブビューアを使用して、より多くのビデオを見ることができます。

ネットワークはアニメキャラクターのレンダリングについて訓練されたため、同じアートスタイルの図面にうまく一般化されました。私は彼らが目を特にうまく処理したことに注意したいと思います。ほとんどのキャラクターでは、髪の一部が隠れている場合でも、目を正しく閉じていました。ただし、いくつかの障害も観察できます。
・キャラクターの外観が訓練データセットから大きく外れると、ネットワークが顔を誤って解析し、無意味な動きにつながる可能性がある。
たとえば、訓練セットのほとんどのキャラクターのスキンは黄色または茶色ですが、「ギルザレンⅢ世」のスキンは紫色です。アニメーション化された後、彼の目と右耳は動かず、顔を回転させると完全に平らに見えます。

・フェイスモーファーは、一部のキャラクターの口を完全に閉じなかった。
これらのキャラクターの口の色は周囲の皮膚に近いことに気づいたので、口をより暗い色で塗り直してみましたが、モーファーはなんとか口を閉じることができました。これは、口と肌の色の間の高いコントラストに向かうデータセットのバイアスを示しています。

・フェイスモーファーが画像を変更する領域は、周囲のピクセルと滑らかにブレンドされない。
それらは、閉じた目と口の周りの円として、周囲の皮膚よりもわずかに暗い色で見ることができます。ただし、この問題は、テストデータセットから3Dレンダリングをアニメーション化する場合には現れません。これは、データセットと2D絵の違いが原因であることを示唆しています。
次に、レンダリングが2D絵より一般的に暗く見えるので、フェイスモーファーはより暗い肌の色を出力することを学んだかもしれません。この理論をテストするために、シーンライティングの設定方法を変更し、データセットを再生成しました。
今回は、周囲の光の大きさを0.5の一定値に設定する代わりに、間隔 [0.5, 1.2] から大きさをサンプリングしたため、生成される画像のほとんどが明るくなります。新しい訓練データセットで訓練されたフェイスモーファーは、黒丸を発生させることなく目と口を閉じることができました。(ただし、場合によっては、残念ながら新しいアーティファクトが導入されます。)

13. その他の結果
ニューラルネットワークは入力として数値ポーズパラメータを受け取るため、これらの数値を生成するあらゆる種類のプロセスで使用できます。要約で見たように、GUI要素を介して手動でポーズパラメータを指定できるツールを作成しました。
ポーズパラメータは、顔のランドマークトラッカーから取得することもできます。以下のビデオでは、dlibとOpenCVで実装されたトラッカーを使用してライブWebカメラストリームを処理し、キャラクターが顔の動きを模倣できるようにしました。
また、このシステムを著名人のビデオに適用しました。
14. おわりに
視聴者をまっすぐ見ているキャラクターの画像が1つしかない場合、表情を変更し、アニメキャラクターの顔を回転させることができるニューラルネットワークシステムを紹介しました。2D入力にもかかわらず、システムは3Dオブジェクトであるかのようにキャラクターの顔を回転させることができます。また、これらの顔の特徴が隠されている可能性があるという事実を考慮して、キャラクターの目と口をもっともらしい方法で閉じる方法を推測します。その結果、キャラクターモデルを作成せずにトーキングヘッドアニメーションを生成することができ、アニメーション制作のコストを大幅に削減できます。
このシステムのもう1つの強みは、その使いやすさです。以前の多くの作品では、アニメーション化されるキャラクターはGAN latent コードに結び付けられており、キャラクターの移動に合わせて外観をカスタマイズしたり、アイデンティティを維持したりすることは困難です。一方、私のシステムはキャラクター画像を直接入力として受け取り、既存のキャラクターをアニメーション化できます。さらに、キャラクターのポーズは6つの数値パラメーターによって決定されるため、数字を調整するプロセスで制御できます。ライブビデオストリームで実行されるUI操作と顔追跡を使用して、キャラクターを制御する方法を示しました。
このプロジェクトの成功の中心は、ダウンロード可能な3Dモデルを活用して訓練データを生成するスケーラブルな方法です。6か月間の空き時間に一人で仕事をし、ほとんどお金をかけずに、簡単な教師あり学習を可能にする大きなペアのデータセットを作成することができました。高品質の訓練データがあれば、比較的単純なネットワークを使用して、優れたアニメーションを作成できます。
VTuberのコンテンツ作成およびビデオゲーム制作で、このシステムのアプリケーションを使用しています。この研究は、機械学習がアニメーションの有用なツールになり得ることを示していると思います。
もちろん、この記事で説明したアプローチには、いくつかの制限があります。
・入力画像は、セクション4の仕様に厳密に従う必要がある
キャラクターは直立して、まっすぐ前を見る必要があります。さらに、画像にはアルファチャネルが含まれている必要があります。その結果、システムは野生のキャラクター画像に適用できません。
・現在は目と口を操作する1つの方法のみ
さまざまな口と目の形を幻覚化することを学べば、はるかに便利です。
・生成された画像はぼやけており、非遮蔽部分に人工物が含まれている
最後に、将来の可能性を考えてみます。
・訓練データとプロセスを変更して、野生のキャラクター画像をアニメーション化できるようにする。
・生成モデルを組み込むことにより、ぼやけと視覚的なアーティファクトを修正。
・アプローチを拡張して、複数の2D絵を組み込み、ほぼすべてのキャラクターデザインシートに存在する同じキャラクターの複数のビューを活用できるようにする。
・アニメーションをより表現力豊かにするために、複数の口、目、眉の形を有効にする。
・髪や布の動きなどの動的な要素をシミュレートするために、ネットワークを繰り返す。
・2D絵から2.5Dレイヤーモデルまたは完全な3Dモデルを推測。
この記事が気に入ったらサポートをしてみませんか?