
MineRL : マインクラフトのデモの大規模データセット

以下の記事が面白かったので、ざっくり訳してみました。
・MineRL: A Large-Scale Dataset of Minecraft Demonstrations
0. 要旨
「強化学習」のサンプル効率の悪さは、実世界への強化学習の適用の妨げになっています。人間のデモを活用することで、サンプル効率を良くすることができますが、研究はあまり多くありません。
「コンピュータービジョン」や「自然言語処理」で実証されているように、大規模データセットは、新しい手法の実験およびベンチマークとして機能することにより、研究を促進する力があります。しかし、強化学習の既存のデータセットには、十分な規模、構造、および品質がありません。
そこで、「マインクラフト」のデモの大規模データセット「MineRL」を紹介します。このデータセットには、「マインクラフト」の様々なタスクの、自動注釈付きの状態行動ペアが、6,000万以上含まれています。さらに、新しいタスクの導入と、データ収集を可能にする、「データ収集プラットフォーム」も提供します。
本稿では、「MineRL」データセットの「階層性」「多様性」「規模」を示し、「MineRL」の可能性と共に、「マインクラフト」のタスクの難しさを示します。
1. はじめに
「強化学習」は、より困難なタスクでは、より多くのサンプルが必要になります。たとえば、「Atariゲーム」で人間レベルにまで達するには200〜900時間以上必要になります。「Dota 2」では、11,000年以上、「囲碁」では490万ゲームのセルフプレイ、「StarCraft II」では200年のゲームプレイが必要になります。そのため、「データ増強」や「ドメインアライメント」を活用したり、膨大な数の試行を可能にするための実環境の設計を行わずに、強化学習を実世界のタスクに適用するのは非常に困難です。
近年「模倣学習」や「ベイジアン強化学習」など、軌跡のサンプルを活用する手法は、サンプル効率が悪い環境で成功を収めてます。しかし、大規模で複雑な実世界のタスクに対しては、まだ不十分です。
「コンピュータービジョン」や「自然言語処理」のコミュニティでは、「Switchboard」や「ImageNet」などの「大規模データセット」と「データ収集プラットフォーム」の導入によって触媒されています。強化学習のコミュニティは広範なベンチマークを作成しましたが、人間のデモによる大規模データセットが不足しています。
そこで、「マインクラフト」の人間のデモによる大規模データセットである「MineRL」を導入します。「MineRL」には、さまざまな研究課題を持つ6つのタスクが含まれています。さらに、人間のデモを継続的に収集するためのプラットフォームも提供します。ユーザーが公開されているゲームサーバーでプレイすることで、人間のデモがパケットレベルで記録されます。
デモビデオとデータセットの詳細については、「http://minerl.io」を参照してください。
2. マインクラフト環境
◎ マインクラフトの概要
「マインクラフト」は、強化学習および模倣学習の研究を行うのに説得力のある環境です。リソースの収集とストラクチャーおよびアイテムの作成を中心とした、一人称の3Dオープンワールドゲームになります。シングルまたはマルチプレイヤーモードでプレイが可能で、すべてのプレイヤーが同じ世界で周囲に影響を与えます。多くの場合、1ゲームにつきプレイヤーごとに合計で数十時間プレイします。自動生成された世界は、修正が可能なブロックで構成されています。ゲームプレイの過程で、プレーヤーはリソース(木からの木材など)を収集し、ストラクチャー(シェルターやストレージなど)を構築することにより、周囲を変化させます。
「マインクラフト」には明確な目標はありません。代わりに、プレイヤーは、多くの自然階層を形成する独自のサブゴールを設定します。これらの階層のサイズと複雑さは「マインクラフト」固有の難しさの一因となります。このような階層の1つに「アイテムコレクション」があります。
「マインクラフト」の目標の多くは、プレーヤーが特定のツールやマテリアルを使って、任意のアイテムを作成することにあります。これらの依存関係の集合体は、大規模なタスク階層を形成します。

【図2】「マインクラフト」のアイテム階層のサブセット(合計371の一意のアイテム)。各ノードは一意の「マインクラフト」のアイテム、ブロック、またはノンプレイヤーキャラクターであり、ノード間の有向エッジは、一方が他方の前提条件であることを示す。提示される各アイテムは独自の課題のセットであるため、一人のプレイヤーが完全な階層をカバーするには数百時間かかる。
アイテムの取得に加えて、ゲームプレイの他の側面から暗黙的な階層が出現します。たとえばプレーヤーは、自然発生する敵から身を守るためのストラクチャーを構築し、天然資源を求めて世界を探検し、しばしばノンプレーヤーキャラクターと戦闘します。これらのゲームプレイ要素は、どちらも長い期間かかり、状況依存の要件(生き残るために必要な特定のリソースの生成、探索による別のリソースの収集など)により、柔軟な階層を示します。
◎ マインクラフトへの関心
「マインクラフト」は、マインクラフトの強化学習環境「Malmo」の開発により、研究対象として大きな関心を集めました。しかし、既存の研究の多くは、「マインクラフト」のトイタスクを利用しており、人間のプレーヤーが通常直面する本質的な複雑さを含まない、人工的に限定されたマップに制限されています。これら制限は、タスクの難しさだけでなく、人間の状態空間と行動空間に対処する現在のアプローチの不可能性、および人間の最適方策の複雑さを反映しています。
これらの制限された「マインクラフト」環境と人間が遭遇する完全な領域との間のギャップを埋めることが、「MineRL」の開発の原動力です。これを行うために、「MineRL-v0」は、研究としての使用を動機付けたマインクラフトの主要な側面を記録します。同時に、現在および将来の研究によって、完全な「マインクラフト」のタスクに取り組むために必要な、「人間の優先順位」と「自動生成メタデータ」を提供します。
◎ データ収集プラットフォーム
「分類」や「自然言語」のデータセットは、「Mechanical Turk」のような「データ収集プラットフォーム」の存在から大きな恩恵を受けています。対照的にゲームのプレイデータの収集には通常、各ゲームの新しいプラットフォームとユーザー獲得スキームの実装が必要になります。
そこで、「マインクラフト」でプレイヤーの軌道を収集するためのエンドツーエンドプラットフォームを作成し、「MineRL-v0」データセットの構築を可能にします。
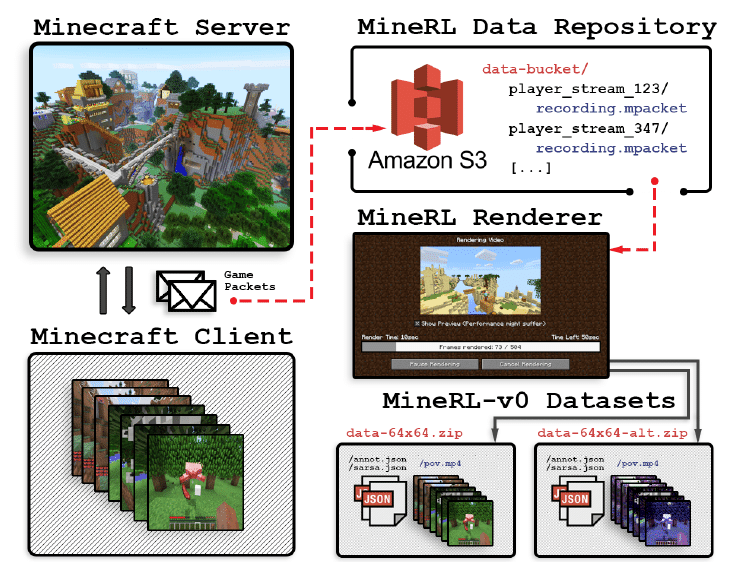
【図1】「MineRL」のデータ収集プラットフォームの図。システムはパケットレベルのデータからデモをレンダリングするため、ゲームの状態とレンダリングパラメータを変更できる。
(1) パブリックゲームサーバーおよびWebサイト
自然なゲームプレイで「マインクラフト」のプレイヤーの軌跡を記録します。
(2) マインクラフトクライアントプラグイン
クライアントとサーバー間のすべてのパケットレベルの通信を記録するため、ゲームの状態とグラフィックを変更して、人間のデモを再シミュレートおよび再レンダリングできます。
(3) データ処理パイプライン
タスクのデモの注釈付きデータセットを自動的に作成できます。
・データ収集
マインクラフトプレーヤーは、マインクラフトサーバーリストで「MineRL」サーバーを見つけます。プレイヤーは、最初にWebページを使用して、ゲームプレイを匿名で記録することに同意します。次に、マインクラフトクライアント用のプラグインをダウンロードし、ユーザーのクライアントサーバーゲームパケットを記録して「MineRL」データリポジトリにストリーミングします。サーバーでプレイする場合、ユーザーはスタンドアロンタスクを選択し、獲得した報酬の量に比例してゲーム内通貨を完了して受け取ります。
サバイバルゲームモード(既知の報酬機能がない)では、プレイヤーはゲームプレイの期間中のみ報酬を受け取り、人工的な報酬機能を課さないようにします。これらの各スタンドアロンタスクを「Malmo」に実装します。
・データパイプライン
データパイプラインにより、「MineRL」データセットのリリースに伴う構造化情報の継続的な拡張が可能になります。記録された軌跡を、アルゴリズム的に消費可能ないくつかの形式に再シミュレート、変更、および拡張できます。パイプラインは、「マインクラフト」の拡張機能として機能し、カスタムAPIを使用して、記録された各パケットを「MineRL」データリポジトリからマインクラフトクライアントに同期的に再送信します。このAPIを使用すると、既存のマインクラフトからアクセス可能なゲーム状態のあらゆる側面に基づいて注釈を追加できます。
・拡張性
私たちの目的は、プラットフォームを使用して、自然言語、具体化された推論、階層的計画、およびマルチエージェント協力に及ぶ、強化学習環境とペアになった網羅的かつ広範な(MineRL-v0を超える)マルチタスクデータセットを提供することです。サーバーのモジュール設計により、ますます多くのスタンドアロンタスクのデータを取得できます。さらに、ゲーム内エコノミーとサーバーコミュニティは、ユーザーベースからの一貫した関与を生み出し、追加コストを発生させることなく、増加する速度でデータを収集することができます。データパイプラインのモジュール性、シミュレーター互換性、および構成可能性により、新しいデータセットを作成して、人間のデモンストレーションを活用した新しい手法を補完することもできます。たとえば、異なる制約、照明の変更、カメラの位置(具体化および非具体化)、およびその他のビデオレンダリング条件でデータを繰り返し再レンダリングすることにより、大規模な汎化研究を行うことができます。
3. MineRL-v0
このセクションでは、「MineRL-v0」データセットを紹介して分析します。最初に、「サイズ」「フォーム」「パッケージング」など、データセットに関する詳細を示します。次に、含まれる「タスク」の詳細を説明し、その後に「データ品質」「カバー範囲」「階層性」の分析を行うことにより、この最初のリリースの幅広い適用性を示します。
◎ データセットの詳細
・サイズ
「MineRL-v0」データセットは、データ収集プラットフォームからの6つの異なるタスクに関する500時間以上の記録された人間のデモで構成されています。リリースされたデータは、さまざまな解像度(64x64および192x256)とテクスチャ(デフォルトまたは簡易)でレンダリングされた4つの異なるバージョンのデータセットで構成されています。各バージョンは、それぞれ低解像度データセットと中解像度データセットのサイズが、それぞれ130GBと734GBで、合計6,000万以上の状態行動ペアになります。
・フォーム
各軌跡は、マインクラフトのすべてのゲームステップ(1秒あたり20ステップ)でサンプリングされた状態と行動のペアの連続したセットです。各状態は、プレイヤーの視点のRGBビデオフレームと、そのステップのゲーム状態からの包括的な機能セットで構成されます。
各ステップで記録される行動は、クライアントでのすべてのキーボード押下、ビューのピッチとヨーの変化(マウスの動きによる)、すべてのプレーヤーGUIクリックおよび相互作用イベント、送信されたチャットメッセージ、アイテムなどの凝集行動で構成されます。
・追加の注釈
人間の軌跡には、自動的に生成された大量の注釈が伴います。すべてのスタンドアロンタスクについて、タイムスタンプ付きの報酬、ノーオペレーション数、死亡数、合計スコアなど、デモの品質を示すメトリックを記録します。さらに、トラジェクトリメタデータには、階層ラベルのタイムスタンプ付きマーカーが含まれています。
・パッケージング
データセットの各バージョンは、タスクごとに1つのフォルダ、デモごとに1つのサブフォルダーを持つZipアーカイブとしてパッケージ化されます。各トラジェクトリフォルダには、状態と行動がプレーヤーのPOVのH.264圧縮MP4ビデオとして保存されます。最大ビットレートは18Mb/sで、JSONファイルにはゲーム状態の非視覚的機能もすべて含まれます。さらに、特定のタスク構成(行動と状態空間の簡素化)のために、ベクター形式の状態行動報酬タプルで構成される「Numpy .npz」ファイルを提供し、データセットのアクセシビリティを促進します。パッケージ化されたデータと付属ドキュメントは、「http://minerl.io」からダウンロードできます。
◎ タスク
初期の「MineRL-v0」データセットは、「マインクラフト」の困難な側面を表すために選択された6つのタスクで構成されます。エージェントはすべてのタスクを通して、人間のプレイヤーと同じ行動と観察のセットにアクセスできます。各タスクの詳細は以下のとおりです
・Navigateタスク
「Navigateタスク」では、エージェントは、さまざまなマテリアルとジオメトリを使用して、自動生成された非凸地形上でランダムな目標位置に移動する必要があります。これは、「マインクラフト」全体の多くのタスクのサブタスクです。標準の観察に加えて、エージェントは「コンパス」観察にアクセスできます。この観察は、開始位置から64ブロック(メートル)の設定位置を指します。目標には、この位置からの小さなランダムな水平オフセットがあり、表面レベルよりわずかに低い場合があるため、エージェントは視覚的特徴に基づいて検索することにより最終目標を見つける必要があります。提供される「報酬関数」には、「sparse」(目標に到達するとエピソードが終了する時点で+1)、および「dense」(目標に向かって移動した距離に比例する報酬)の2つのバリアントがあります。
・Treechopタスク
「Treechopタスク」は、さらにアイテムを生産するための木材の取得を複製します。木材は、すべてのツールの前提条件であるため、「マインクラフト」の重要なリソースです。エージェントは、木を切るための鉄のつるはしを持った状態で、森林内で開始します。エージェントには、木材の各ユニットを取得した場合に+1の報酬が与えられ、エージェントが64ユニットを取得するとエピソードは終了します。
・ObtainIronPickaxeタスク / ObtainDiamondタスク / ObtainCookedMeatタスク / ObtainBedタスク
「ObtainIronPickaxeタスク」「ObtainDiamondタスク」「ObtainCookedMeatタスク」「ObtainBedタスク」は、エージェントがアイテム階層でさらにアイテムを取得することを必要とするタスクです。エージェントは常にアイテムのないランダムな場所で開始します。これは、「マインクラフト」の人間プレイヤーの開始条件に一致します。これらタスクは、頻繁に使用されるアイテムに対応します。鉄のつるはし、ダイヤモンド、調理済みの肉(4つのバリアント、動物源ごとに1つ)、およびベッド(3つのバリアント、必要な染料の色ごとに1つ)です。鉄のつるはしは、主要な材料を入手するために必要なツールです。ダイヤモンドは高レベルな「マインクラフト」のプレイの中心であり、ゲームプレイの大部分はその発見に集中しています。調理された肉はスタミナを補充するために使用され、寝るにはベッドが必要です。エージェントには、必要なアイテムを取得したことに対する+1の報酬が与えられ、その時点でエピソードは終了します。
・Survival
特定の設計されたタスクに関するデータに加えて、ほとんどのプレイヤーが使用する標準的なオープンエンドゲームモードである「Survival」のデータも提供しています。アイテムのないランダムな場所から始めて、プレイヤーは独自の高レベルの目標を策定し、これらの目標を完了するためのアイテムを取得します。このタスクからのデータは、オープンプレイの人間とそれに対応するポリシーが続く複雑な報酬機能を学習するために使用できます。このデータは、他の構造化されたタスクを完了しようとするエージェントを訓練したり、ポリシースケッチを抽出するために使用することもできます。
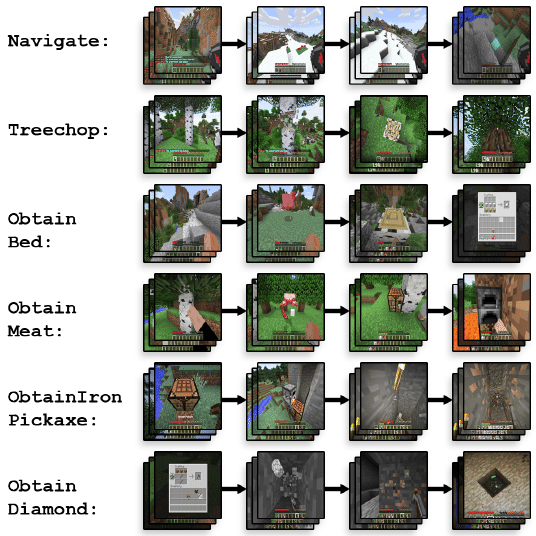
【図3】6つのタスクのさまざまな段階の画像(Surviaは含まず)。
4. 分析
◎ 人間のパフォーマンス
データセットの人間によるデモの大部分は、エキスパートレベルのプレイの範囲内にあります。【図4】は、各タスクを完了するのに必要な時間のプレーヤー間の分布を示しています。各ヒストグラムの赤い領域は、エキスパートレベルでのプレイに対応する時間の範囲を示し、少なくとも5年間の「マインクラフト」の経験を持つプレイヤーがタスクを完了するのに必要な平均時間として計算されます。多数の専門家サンプルとデモパフォーマンスの豊富なラベリングにより、基本ポリシーの最適性を前提とする多くの標準的な模倣学習手法を適用できます。さらに、初級および中級レベルの軌跡により、不完全なデモを活用する技術のさらなる開発が可能になります。

【図4】さまざまなMineRLタスクの人間によるデモの長さの正規化されたヒストグラム。赤いEは、各タスクでのエキスパートプレイの上限しきい値を示す。
・カバー範囲
「MineRL-v0」は、「マインクラフト」をほぼ完全にカバーしています。Survivalモードでは、さまざまなアイテムを取得するための371個のサブタスクの大部分が、何百回から何万回もプレイヤーによって実証されています。さらに、これらのサブタスクのいくつかは完了するまでに数時間を必要とし、敵の採掘、構築、探索、および戦闘の長いシーケンスを必要とします。多数のタスクレベルの注釈の結果として、データセットは大規模なオプション抽出とスキル獲得に使用できます。さらに、Obtain<Item>タスクの豊富なラベル階層を使用して、抽出されたオプションの解釈可能性と品質のメトリックを構築できます。
アイテムのカバー範囲に加えて、「MineRL」データ収集プラットフォームは、ゲームの状態を幅広く表現できるように構成されています。現在のデータセットは、1,002の一意のプレーヤーセッションから抽出されたさまざまなデモセットで構成されています。サバイバルゲームモードでは、記録された軌跡がまとめて24をカバーします。1平方メートルは1つのマインクラフトのブロックに対応します。他のすべてのタスクについては、各デモはランダムに初期化されたゲームワールドで行われるため、各タスクについて多数の一意で異なる軌道を収集します。【図5】では、各タスクを完了する過程でのプレイヤーのトップダウンの位置を示しています。開始状態は(0, 0)です。 各プレイヤーは異なるゲーム世界で行動するだけでなく、各プレイヤーは各タスク中に広い地域を探索します。
・階層性
【図2】に示すアイテムグラフに例示されているように、「マインクラフト」は階層が深く、「MineRL」のデータ収集プラットフォームは、これらの階層を明示的および暗黙的にキャプチャするように設計されています。主な例として、Get <アイテム>タスクは、アイテム階層内で困難であるが重なっているコアパスを分離します。「MineRL-v0」で提供されるサブタスクのラベル付けにより、これらのタスクが重複する程度を検査および定量化できます。
階層性の直接的な尺度は、アイテム優先度頻度グラフ、ノードがタスクで取得したアイテムに対応し、有向エッジがプレイヤーがターゲットノードアイテムの直前にソースノードアイテムを取得した回数に対応するグラフを通して現れます。
これらのグラフは、人間のメタポリシーと、サブポリシーがタスク間で移行する程度の統計ビューを提供します。【図6】は、MineRLの軌跡から取得した、「ObtainDiamond」「ObtainCookedMeat」「ObtainIronPickaxe」の優先度頻度グラフを示しています。
ダイヤモンドを取得するためのポリシーは、木材、トーチ、鉄鉱石を取得するサブポリシーで構成されていることが明らかになりました。これらはすべて、「ObtainIronPickaxe」タスクの取得にも必要ですが、その一部のみが、「CookedMeat」タスクで使用されます。これらの重複するサブポリシーの効果は、【図5】で見ることができます。プレーヤーは、階層が重複するタスク(SpecifyIronPickaxeとGetDiamondなど)で同様に移動し、重複の少ないタスクでは異なる動きをします。さらに、これらのグラフは、タスク内の人間のメタポリシーの分布図を描きます。これにより、分布型階層強化学習法の開発に「MineRL-v0」を使用できるようになります。

【図5】「Treechop」「Navigate」「GetIronPickaxe」「GetDiamond」のプレーヤーのXY位置のプロットをオーバーレイして、各プレーヤーの個々のランダムな初期位置が(0, 0)になるようにする。

【図6】ObtainDiamond (左)、ObtainCookedMeat (中)、ObtainIronPickaxe (右)のアイテム優先度頻度グラフ。各線の太さは、プレイヤーがアイテムAを収集し、その後アイテムBを収集した回数を示す。
5. 実験
◎ 実験構成
「マインクラフト」の難しさを示すために、最も簡単なタスク(TreechopとNavigate(sparse))を、3つの強化学習法と1つの模倣学習で性能を評価します。
(1) Dueling Double Deep Q-networks (DQN)
(2) Pretrain DQN (PreDQN)
(3) Advantage Actor Critic (A2C)
(4) Behavioral Cloning (BC)
観察は64x64のグレースケールに変換されます。マインクラフトの数千の行動の組み合わせとベースラインアルゴリズムの制限により、行動空間を10個の離散行動に簡素化します。 ただし、BCにはこのような制限はなく、行動空間を単純化せずに実行されます。 PreDQNおよびBCで人間のデモを使用するには、各行動を10個の行動プリミティブのいずれかで近似します。 1500エピソード(約1200万フレーム)の訓練を行います。BCを訓練するには、各タスクのエキスパートの軌跡を使用し、ポリシーのパフォーマンスが最大になるまで訓練します。
◎ 評価と議論
訓練中に100エピソードのウィンドウで得られた最高の平均報酬によってアルゴリズムを比較します。また、ランダムポリシーのパフォーマンスと人間の50パーセンタイルパフォーマンスも報告します。結果を【表1】にまとめます。

【表1】最高100の連続エピソードでの「Treechop」「Navigate(Sparse)」「Navigate(Dense)」の結果。±は標準偏差を示す。人間は、すべてのタスクで最大スコアを達成。
すべてのタスクで、学習したエージェントのパフォーマンスは、人間のパフォーマンスよりも著しく劣ります。「Treechop」が最も差があり、人間がスコア64に対し、エージェントのスコアは4未満になります。環境の固有の長い期間のクレジット割り当ての問題が原因であると仮定しています。
たとえば、エージェントが死ぬまでに多くの移行が必要になるため、エージェントが水をナビゲートすることを学ぶのは困難です。
これらの困難に照らして、私たちのデータはパフォーマンスとサンプルの効率を改善するのに役立ちます。すべてのタスクで、人間のデータを活用することでパフォーマンスが向上します。【図7】に見られるように、エキスパートのデモは、エピソードごとに高い報酬を達成します。エキスパートのデモは、Navigateのように、ランダム探索で報酬が得られそうにない環境で特に役立ちます。

【図7】「Navigate(Dense)」タスクにおける「Pretrained DQN」と「DQN」のパフォーマンスグラフ。
6. 関連作業
模倣学習と人間のデモのデータセットによって、過去に多くのタスクが解決されました。これには、「Atari Grand Challenge」データセットを使用する「Atari環境」、およびオンデマンドデータセットを使用する「Super Tux Kart」環境が含まれます。「マインクラフト」とは異なり、これらは単純な環境です。それらは浅い依存関係階層を持ち、オープンワールドではありません。行動空間と状態空間が小さいため、これらのタスクは、比較的少ないサンプル数の模倣学習で解決しました(5ゲームで970万フレーム)。
対照的に、「マインクラフト」では、6,000万件の自動注釈付き状態行動ペアでも、人間レベルのパフォーマンスになりません。
課題のある未解決のタスク用の既存のデータセットは、主にシミュレータが不足しているため開発のペースが制限される実世界のタスク用です。たとえば、「KITTI」データセットは、実世界のトラフィックに関する3時間の3D情報のデータセットです。同様に、「Dex-Net」は、ロボット操作用の対応する3Dポイントクラウドを備えた500万のデータセットです。
これらのデータセットとは異なり、「MineRL」はシミュレーターである「Malmo」と直接互換性があるため、データが収集されたのと同じ環境で訓練し、模倣学習以外の方法と比較できます。さらに、「MineRL」のスケールは、「KITTI」および「Dex-Net」データセットよりもドメインの難易度に比べて大きくなっています。
既存のシミュレータと大規模なデータセットを持つ唯一の複雑で未解決のドメインは、「StarCraft II」です。ただし、「StarCraft II」はオープンワールドではないため、3D環境で具体化されたタスク用に設計されたメソッドの評価には使用できません。現在、最大のデータセットは「StarData」です。「MineRL」とは異なり、ラベルのない抽出された標準的なゲームプレイの軌跡で構成されています。
対照的に、「MineRL」には、「マインクラフト」のタスク階層全体のさまざまなコンポーネントを表す関連タスクが増えています。さらに「MineRL」はサブタスクの完了、プレーヤーのスキルレベル、およびこれらのラベルを拡張するAPIを含む、自動生成された豊富な注釈で構成されています。これらのプロパティにより、階層構造を活用するメソッドの使用と評価が可能になります。
7. 結論と今後の作業
「MineRL-v0」は現在、自動注釈が付けられた人間のデモの状態行動ペアを6,000万個備えています。現在、6つのタスクのデータが含まれていますが、標準の強化学習方法では完全に解決することはできません。このプラットフォームでは、既存のタスクと新しいタスクの両方のデモを継続的に収集できます。したがって、「MineRL-v0」はコミュニティがWebサイト「http://minerl.io」でホストし、新しい注釈とタスクを「MineRL」に追加することに関するフィードバックを収集します。「MineRL」が拡張することによって、「逆強化学習」「階層型学習」「生涯学習」などのさまざまな手法の研究に役立つことが期待されます。「MineRL」が逐次的な意思決定研究の中心的なリソースになり、より広範な実世界環境を解決できる手法を開発するという共通の目標に向けてAIの多くのブランチを強化できることを願っています。
この記事が気に入ったらサポートをしてみませんか?