
YOLO V5 の使い方

1. YOLO V5
「YOLO V5」は物体の位置と種類を検出する機械学習アルゴリズムです。
「YOLO V5」には、以下の4種類の大きさのCOCOモデルが提供されています。大きい方が精度が上がりますが、速度は遅くなります。
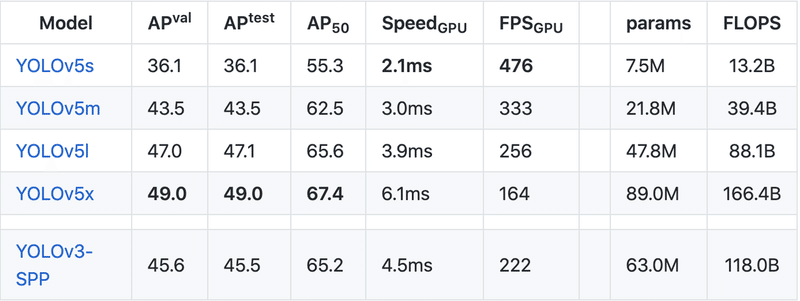
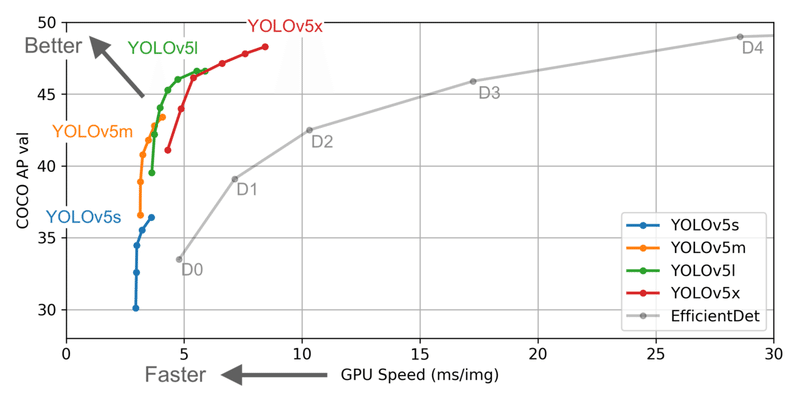
以下のグラフは、1枚の画像の推論にかかる時間(ms)の比較です。バッチサイズ8のV100 GPUを使用し、画像の前処理と後処理も含みます。
2. YOLO V5 のインストール
「YOLO V5」のインストールには、「Python 3.8以降」が必要です。
今回は、AnacondaでPython環境を構築して、インストールします。「macOS10.15.6」で動作確認しています。
$ conda create -n yolov5 python=3.8
$ conda activate yolov5
$ git clone https://github.com/ultralytics/yolov5.git
$ cd yolov5
$ pip install -U -r requirements.txt自分の環境では「pyqt5」「opencv-python-headless」のインストールも必要でした。
$ pip install pyqt5
$ pip install opencv-python-headless3. YOLO V5の実行
「Webカメラ」で「YOLO V5」を実行するコマンドは、次のとおりです。
$ python detect.py --source 0デフォルトでは、一番軽い「YOLOv5s」を使用します。他のモデルを使用するには、ここからダウンロードして、「--weights yolov5m.pt」のように指定します。
$ python detect.py --source 0 --weights yolov5m.pt4. 推論
推論は、Webカメラ以外の様々なメディア形式で実行できます。
$ python detect.py --source 0 # Webカメラ
file.jpg # イメージ
file.mp4 # ビデオ
path/ # フォルダ
path/*.jpg # glob
rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtspストリーム
http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # httpストリーム「./inference/images」フォルダ内の画像を推論するには、次のコマンドを実行します。結果は「./inference/output」に出力されます。
$ python detect.py --source ./inference/images/ --weights yolov5s.pt --conf 0.45. 学習
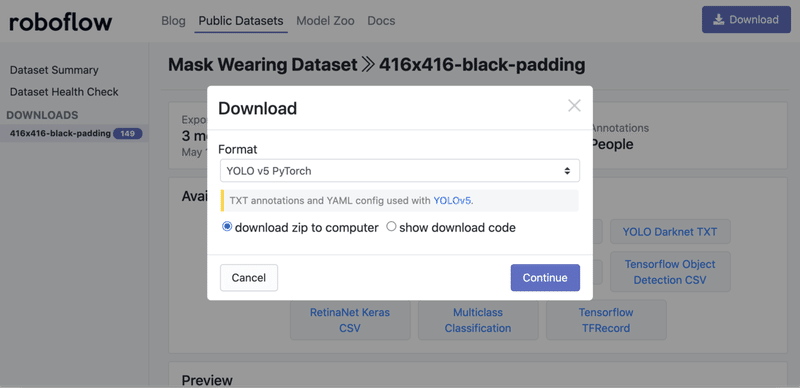
はじめに、「roboflow」からデータセットをダウンロードします。
今回は、「Mask Wearing Dataset」(マスク着用データセット)を「YOLO v5」形式でダウンロードします。
「yolov5/data」フォルダに「test」「train」「valid」をコピーします。
「yolov5」フォルダに「data.yaml」をコピーし、以下のように編集します。
train: data/train/images
val: data/valid/images
nc: 2
names: ['mask', 'no-mask']以下のコマンドで学習を実行します。
$ python train.py --data data.yaml --cfg yolov5s.yaml --weights '' --batch-size 16この記事が気に入ったらサポートをしてみませんか?