
Huggingface Transformers 入門 (3) - 前処理

以下の記事を参考に書いてます。
・Huggingface Transformers : Preprocessing data
前回
1. 前処理
「Hugging Transformers」には、「前処理」を行うためツール「トークナイザー」が提供されています。モデルに関連付けられた「トークナーザークラス」(BertJapaneseTokenizerなど)か、「AutoTokenizerクラス」で作成することができます。
「トークナイザー」は、与えられた文を「トークン」と呼ばれる単語に分割します。そして、そのトークンを数値に変換して「テンソル」を作成し、モデルに供給します。さらに、モデルが適切に動作するように「スペシャルトークン」を付加することもできます。
from transformers import AutoTokenizer
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')2. 文の前処理
◎ エンコード
「トークナイザー」には多くのメソッドがありますが、覚えておく必要があるのは「__call__」のみです。インスタンス名をメソッドのように呼び出します。
>>> encoded_input = tokenizer("Hello, I'm a single sentence!")
>>> print(encoded_input)
{'input_ids': [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}戻り値の辞書の値は以下のとおりです。
・input_ids : トークンIDの配列
・token_type_ids : 文を判別するバイナリマスク
・attention_mask : 埋め込みを判別するバイナリマスク
◎ デコード(トークンIDの配列 → 文)
「トークナイザー」は、トークンIDの配列をデコードすることもできます。
>>> tokenizer.decode(encoded_input["input_ids"])
"[CLS] Hello, I'm a single sentence! [SEP]"これで、モデルが期待する「スペシャルトークン」([CLS][SEP])が自動的に追加されていることを確認できます。
全てのモデルが「スペシャルトークン」を必要とするわけではありません。例えば、「bert-base-cased」ではなく「gtp2-medium」を指定していた場合は、デコードしてもオリジナルと同じ文が表示されます。
「スペシャルトークン」の自動追加を無効にするには、「add_special_tokens=False」を指定します。自分で「スペシャルトークン」を追加したい場合に役立ちます。
◎ 複数の文のエンコード
「トークナイザー」に複数の文をリストで渡すことで、まとめてエンコードすることができます。
>>> batch_sentences = ["Hello I'm a single sentence",
... "And another sentence",
... "And the very very last one"]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[101, 1262, 1330, 5650, 102],
[101, 1262, 1103, 1304, 1304, 1314, 1141, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]]}◎ 複数の文のエンコードのオプション
複数の文をモデルに供給したい場合は、あなたは以下の処理も望むでしょう。
・各文をバッチ内の文の最大長にパディング。
・各文をモデルが許容できる最大長で切り捨て(該当する場合)。
・テンソルを返す。
以下のオプションを使用することで、これら全て行うことができます。
>>> batch = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(batch)
{'input_ids': tensor([[ 101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[ 101, 1262, 1330, 5650, 102, 0, 0, 0, 0],
[ 101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}戻り値の辞書の値は「テンソル」になります。
「attention_mask」は、モデルが注意を払うべきトークンの判別に利用します。1が注意を払うべきトークン、0が埋め込みを表しています。
モデルに関連する最大長がない場合、上のコマンドは警告を出すことに注意してください。無視してもかまいませんが、「verbose=False」を渡すことで、警告を出さないようにすることもできます。
3. 文のペアの前処理
モデルに「文のペア」を与える必要がある場合があります。例えば、2つの文が類似しているかどうかを分類したい場合や、文脈と質問を取る質問応答の場合などです。
BERTでは、入力は次のように表現します。
[CLS] 文A [SEP] 文B [SEP]「2つの文」を「2つの引数」として与えることで、モデルが期待する形式で「文のペア」をエンコードすることができます。
>>> encoded_input = tokenizer("How old are you?", "I'm 6 years old")
>>> print(encoded_input)
{'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}「token_type_ids」は、どの部分が文Aで、どの部分が文Bであるかを判別するために使います。「token_type_ids」は全てのモデルで必須ではないことに注意してください。
デフォルトでは、トークナイザーのトークン化は関連するモデルが期待する入力のみを返します。「return_input_ids」または「return_token_type_ids」を使用することで、これらの特別な引数のいずれかを強制的に返す(または返さない)ことができます。
取得したトークンIDをデコードすると、「スペシャルトークン」が適切に追加されていることがわかります。
>>> tokenizer.decode(encoded_input["input_ids"])
"[CLS] How old are you? [SEP] I'm 6 years old [SEP]"処理したい「文のペア」のリストがある場合は、それら「2つのリスト」を「トークナイザー」に供給します。
>>> batch_sentences = ["Hello I'm a single sentence",
... "And another sentence",
... "And the very very last one"]
>>> batch_of_second_sentences = ["I'm a sentence that goes with the first sentence",
... "And I should be encoded with the second sentence",
... "And I go with the very last one"]
>>> encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102],
[101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102],
[101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}モデルに与えられたものをチェックするために、「input_ids」のリストを1つずつデコードすることもできます。
>>> for ids in encoded_inputs["input_ids"]:
>>> print(tokenizer.decode(ids))
[CLS] Hello I'm a single sentence [SEP] I'm a sentence that goes with the first sentence [SEP]
[CLS] And another sentence [SEP] And I should be encoded with the second sentence [SEP]
[CLS] And the very very last one [SEP] And I go with the very last one [SEP]4. パディングと切り捨ての詳細
「パディング」と「切り捨て」の詳細を解説します。パディングと切り捨てを行うために、知っておくべき引数は、「padding」「truncation」「max_length」です。
◎ padding
パディングを指定します。「bool」「文字列」を指定します。
・false・do_not_pad : パディングが行わない。
・true・longest : 最大長でパディングを行う。
「max_length」が指定されてる場合はその長さ、指定されていない場合はモデルが許容する最大長にパディングします (max_length=None)。
◎ truncation
切り捨てを指定します。「bool」「文字列」を指定します。
・true・only_first : 最大長で切り捨てを行う。
・only_second : 文のペアの2番目の文を切り捨てを行う。
・longest_first : トークンごとに切り捨てを行う。適切な長さに達するまでペアの中で最も長い文からトークンを削除。
・false・do_not_truncate : 切り捨てを行わない
◎ max_length
パディング・切り捨ての長さを指定します。「整数」「None」(モデルの最大長)を指定します。
以下は、パディングと切り捨ての設定方法のおすすめの方法をまとめた表です。
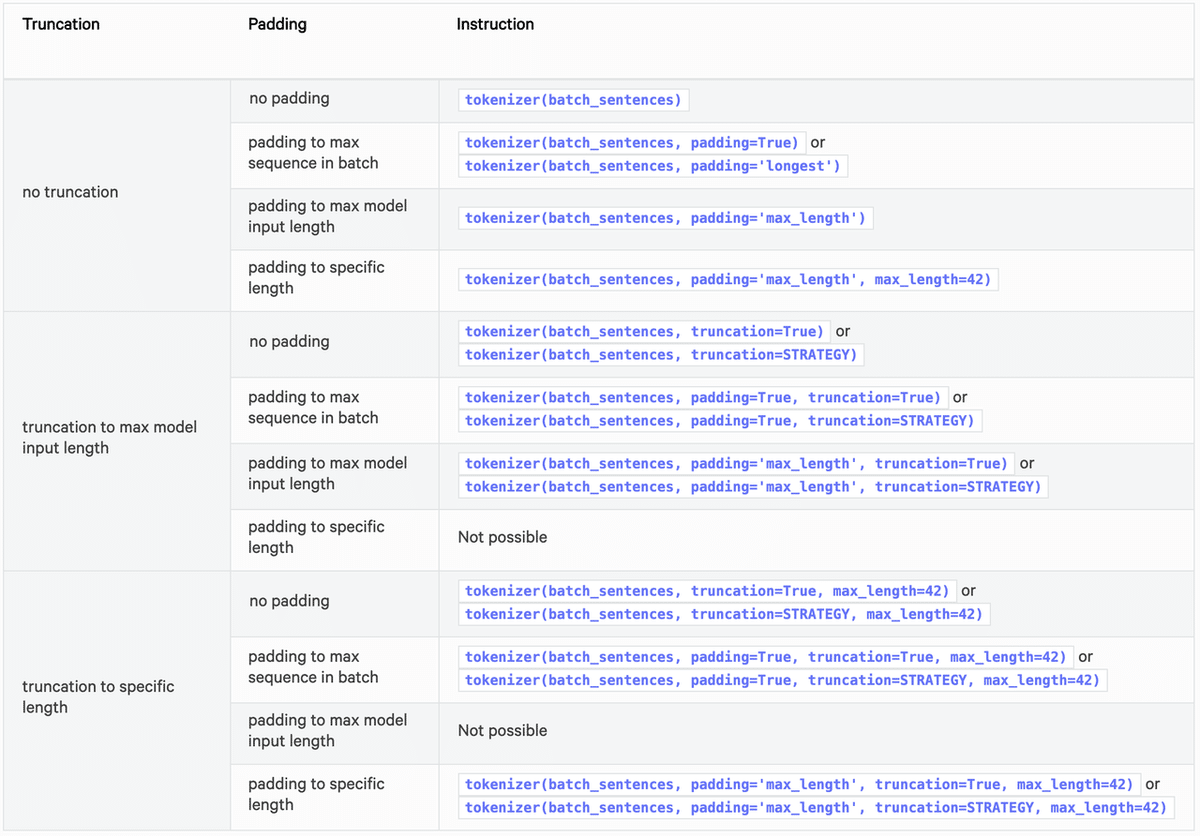
5. 事前トークン化された文の前処理
前処理は、事前トークン化された入力も受け付けます。これは、「固有表現抽出」や「品詞タグ付け」でラベルを計算して予測値を抽出したい場合に有効です。
【注意】「事前トークン化」とは、入力がすでにトークン化されているという意味ではなく(そうであればトークンライザーに渡す必要はありません)、単語に分割されているだけです。これは「BPE」のようなサブワードのトークン化アルゴリズムの最初のステップであることが多いです。
事前トークン化された入力を使用したい場合は、「トークナイザー」に入力を渡す際に「is_pretokenized=True」を指定します。
>>> encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_pretokenized=True)
>>> print(encoded_input)
{'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}「トークナイザー」は、「add_special_tokens=False」を指定しない限り、「スペシャルトークン」を追加することに注意してください。これは、文のバッチや文のペアのバッチの場合と全く同じように動作します。
文のバッチを次のようにエンコードすることができます。
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"],
["And", "another", "sentence"],
["And", "the", "very", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, is_pretokenized=True)また、以下のように文のペアを次のようにエンコードすることができます。
batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"],
["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"],
["And", "I", "go", "with", "the", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences, is_pretokenized=True)次回
この記事が気に入ったらサポートをしてみませんか?