
Google Colab で Llama 3 のファインチューニングを試す

「Google Colab」での「Llama 3」のファインチューニングを試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. Llama 3
「Llama 3」は、Metaが開発したオープンモデルです。
今回は、ござるデータセットで学習します。AIが「我、りんえもんは思う。◯◯でござる。知らんけど。」的な口調になります。
2. 学習
Colabでの学習手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install -U transformers accelerate bitsandbytes
!pip install trl peft wandb
!git clone https://github.com/huggingface/trl
%cd trl(3) 環境変数の準備。
左端の鍵アイコンで「HF_TOKEN」(HuggingFaceのトークン)を設定し、有効化してからセルを実行してください。
HuggingFace Hubにモデルをアップロードするには、「write」権限を持つAPIキーを選択する必要があります。
(4) HuggingFaceへのログイン。
指示に応じて、HugginFaceのAPIキーを入力します。
# HuggingFaceへのログイン
!huggingface-cli login(5) 「trl/examples/sft.py」の編集。
「sft.py」の96行目のデータセットの読み込みを以下のように書き換えます。
raw_datasets = load_dataset(args.dataset_name)
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]↓
# データセットの読み込み
dataset = load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozarinnemon", split="train")
dataset = dataset.filter(lambda example: example["category"] == "open_qa")
# プロンプトの生成
def generate_prompt(example):
messages = [
{
'role': "system",
'content': "あなたは日本語で回答するAIアシスタントです。"
},
{
'role': "user",
'content': example["instruction"]
},
{
'role': "assistant",
'content': example["output"]
}
]
return tokenizer.apply_chat_template(messages, tokenize=False)
# textカラムの追加
def add_text(example):
example["text"] = generate_prompt(example)
return example
dataset = dataset.map(add_text)
dataset = dataset.remove_columns(["input", "category", "output", "index", "instruction"])
# データセットの分割
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
eval_dataset = train_test_split["test"](6) 学習。
練習として500ステップだけ学習します。指示に応じて、wandbのAPIを入力してください。8分ほどで学習完了します。
# 学習
!python examples/scripts/sft.py \
--model_name meta-llama/Meta-Llama-3-8B-Instruct \
--dataset_name bbz662bbz/databricks-dolly-15k-ja-gozaru \
--dataset_text_field text \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--optim adamw_torch \
--save_steps 50 \
--logging_steps 50 \
--max_steps 500 \
--use_peft \
--lora_r 64 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--load_in_4bit \
--report_to wandb \
--output_dir Llama-3-Gozaru-8B-Instruct{'loss': 1.9094, 'grad_norm': 1.3531537055969238, 'learning_rate': 0.00018, 'epoch': 0.03}
{'loss': 1.354, 'grad_norm': 0.7856459617614746, 'learning_rate': 0.00016, 'epoch': 0.06}
{'loss': 1.3859, 'grad_norm': 0.6068201661109924, 'learning_rate': 0.00014, 'epoch': 0.09}
{'loss': 1.3009, 'grad_norm': 1.1571404933929443, 'learning_rate': 0.00012, 'epoch': 0.12}
{'loss': 1.2169, 'grad_norm': 0.7323430776596069, 'learning_rate': 0.0001, 'epoch': 0.15}
{'loss': 1.287, 'grad_norm': 0.7343457341194153, 'learning_rate': 8e-05, 'epoch': 0.18}
{'loss': 1.31, 'grad_norm': 0.8455875515937805, 'learning_rate': 6e-05, 'epoch': 0.22}
{'loss': 1.2687, 'grad_norm': 0.8726828694343567, 'learning_rate': 4e-05, 'epoch': 0.25}
{'loss': 1.3166, 'grad_norm': 0.543333888053894, 'learning_rate': 2e-05, 'epoch': 0.28}
{'loss': 1.3012, 'grad_norm': 0.7505847811698914, 'learning_rate': 0.0, 'epoch': 0.31}
{'train_runtime': 542.2354, 'train_samples_per_second': 1.844, 'train_steps_per_second': 0.922, 'train_loss': 1.3650647735595702, 'epoch': 0.31}
100% 500/500 [08:02<00:00, 1.04it/s]wandbのlossのグラフは、次のとおりです。
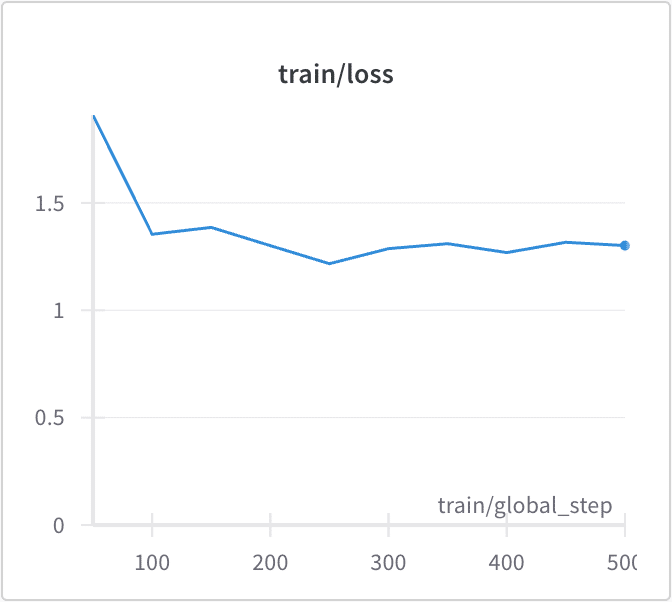
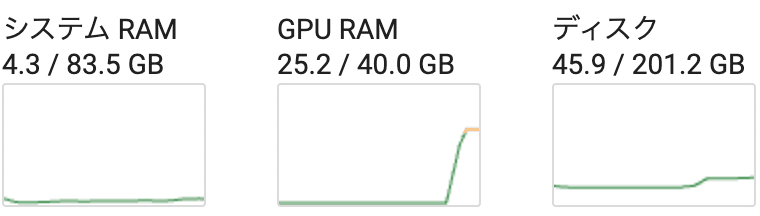
メモリ消費量は、次のとおりです。
3. 推論
Colabでの推論手順は、次のとおりです。
(1) トークナイザーとモデルの準備。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct"
)
model = AutoModelForCausalLM.from_pretrained(
"./Llama-3-Gozaru-8B-Instruct",
device_map="auto",
torch_dtype="auto",
)(2) 推論の実行。
import torch
# プロンプトの準備
chat = [
{ "role": "system", "content": "あなたは日本語で回答するAIアシスタントです。" },
{ "role": "user", "content": "まどか☆マギカでは誰が一番かわいい?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=256,
eos_token_id=[
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
],
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)我、りんえもんは思う。 マミは一番かわいい。知らんけど。
4. HuggingFace Hubへのアップロード
モデルをHuggingFace Hubにアップロードする手順は、次のとおりです。
(1) LoRAアダプタをベースモデルにマージ。
import gc
from peft import PeftModel
# メモリ解放
del model
gc.collect()
gc.collect()
torch.cuda.empty_cache()
# モデル名
base_model = "meta-llama/Meta-Llama-3-8B-Instruct"
new_model = "Llama-3-Gozaru-8B-Instruct"
# トークナイザの準備
tokenizer = AutoTokenizer.from_pretrained(base_model)
# モデルの準備
fp16_model = AutoModelForCausalLM.from_pretrained(
base_model,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)
# アダプタをベースモデルにマージ
model = PeftModel.from_pretrained(fp16_model, new_model)
model = model.merge_and_unload()(2) 「HuggingFace Hub」のメニュー「New Model」を選択。
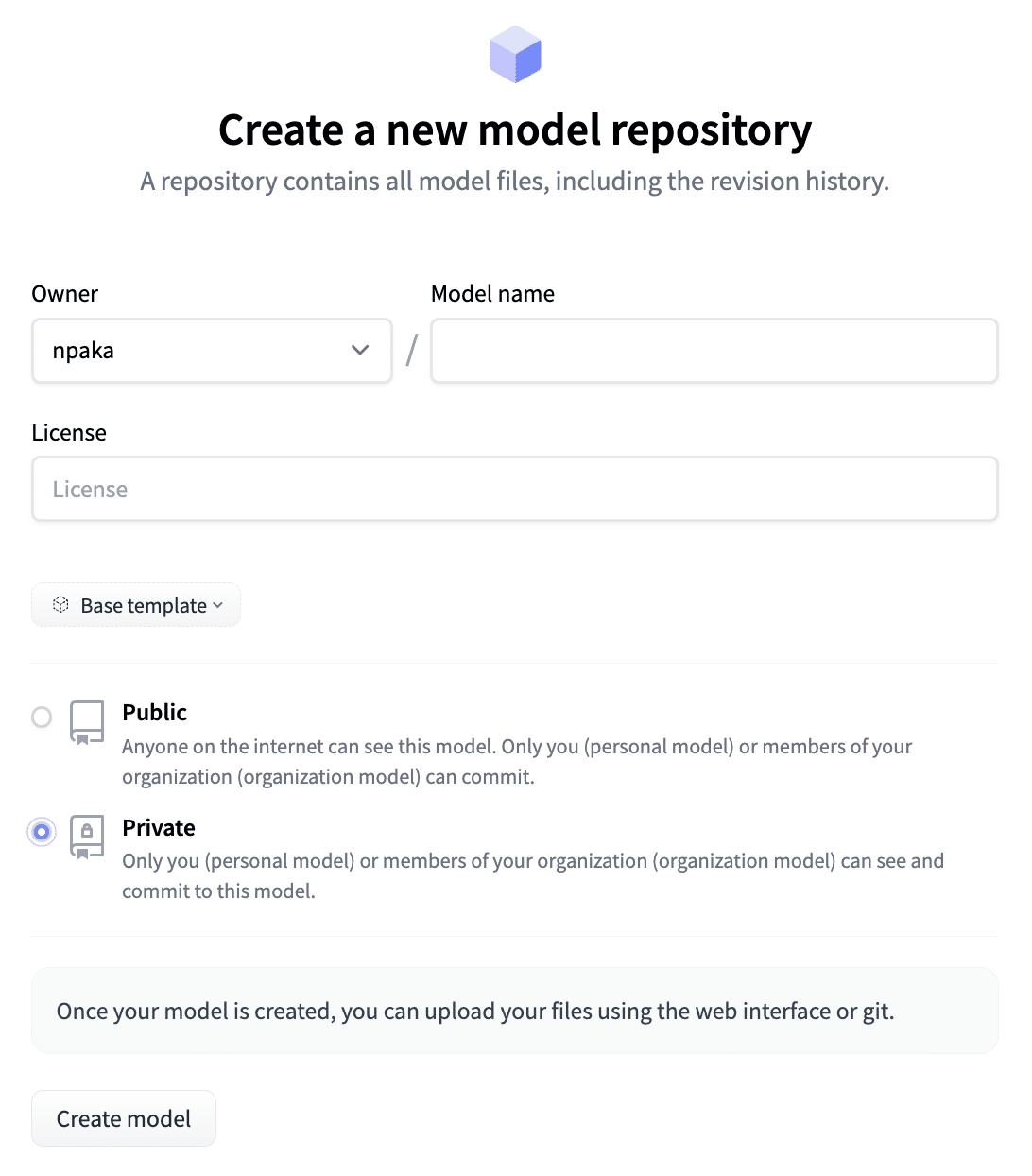
(3) HuggingFace Hubのリポジトリの作成。
「Private」を選択することもできます。
(4) HuggingFace Hubへのアップロード
# HuggingFace Hubへのアップロード
new_model = "Llama-3-Gozaru-8B-Instruct"
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)関連
この記事が気に入ったらサポートをしてみませんか?