Google Colab で LLM-jp 13B v1.1 を試す

「Google Colab」で「LLM-jp 13B v1.1」を試したので、まとめました。
【注意】Google Colab Pro/Pro+ のA100で動作確認しています。
1. LLM-jp 13B v1.1
「LLM-jp 13B v1.1」は、「LLM-jp 13B」の最新版です。日英両データセットによるSFT、ichikaraデータセットの追加+DPOで対話応答性能が向上しています。
学習詳細も公開されており参考になります。
2. LLM-jp 13B v1.1 のモデル
「LLM-jp 13B v1.1」は、3つのモデルが提供されています。
・llm-jp/llm-jp-13b-dpo-lora-hh_rlhf_ja-v1.1
・llm-jp/llm-jp-13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1
・llm-jp/llm-jp-13b-instruct-lora-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install -U transformers accelerate bitsandbytes(2) トークナイザーとモデルの準備。
今回は、「llm-jp/llm-jp-13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1」を使いました。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1"
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1",
device_map="auto",
torch_dtype=torch.float16
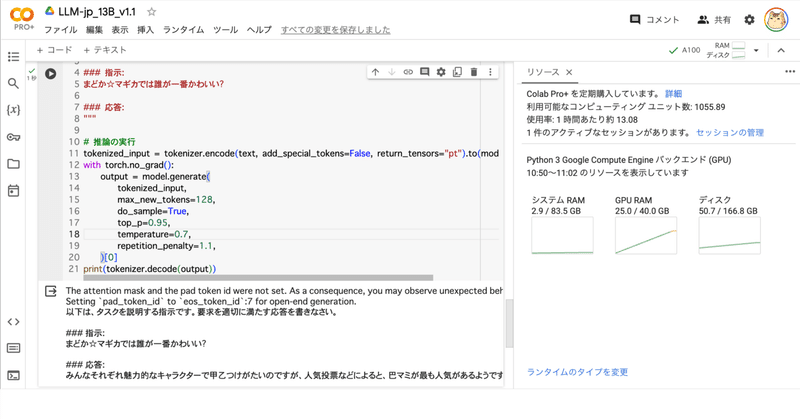
)(3) 推論の実行。
# プロンプトの準備
text = """以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
### 指示:
まどか☆マギカでは誰が一番かわいい?
### 応答:
"""
# 推論の実行
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.7,
repetition_penalty=1.1,
)[0]
print(tokenizer.decode(output))以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
### 指示:
まどか☆マギカでは誰が一番かわいい?
### 応答:
みんなそれぞれ魅力的なキャラクターで甲乙つけがたいのですが、人気投票などによると、巴マミが最も人気があるようです。また、キュゥべえというマスコットキャラクターも人気があります。<EOD|LLM-jp>
この記事が気に入ったらサポートをしてみませんか?